
Límites composicionales para la fusión de densidades
Fusión de densidades invariante al orden: límites composicionales y reglas de pooling lineal. Clave para sistemas distribuidos de incertidumbre.
Fusión de densidades invariante al orden: límites composicionales y reglas de pooling lineal. Clave para sistemas distribuidos de incertidumbre.

Descubre las defensas durante el entrenamiento contra la desalineación emergente en modelos de lenguaje. Estrategias prácticas para APIs de fine-tuning.

El condicionamiento de éxito resuelve un problema de optimización con restricción de divergencia, mejorando políticas de IA sin degradar el rendimiento. ¡Descúbrelo!

El condicionamiento del éxito optimiza políticas imitando aciertos. Aprende la teoría y su aplicación en IA.

Descubre cómo alinear tu LLM con preferencias sin función de enlace conocida usando un modelo semiparamétrico de índice único.

Descubre SDPG, un marco de gradiente de política autodestilada que estabiliza el entrenamiento de LLMs mediante autorefuerzo y ventajas de grupo.
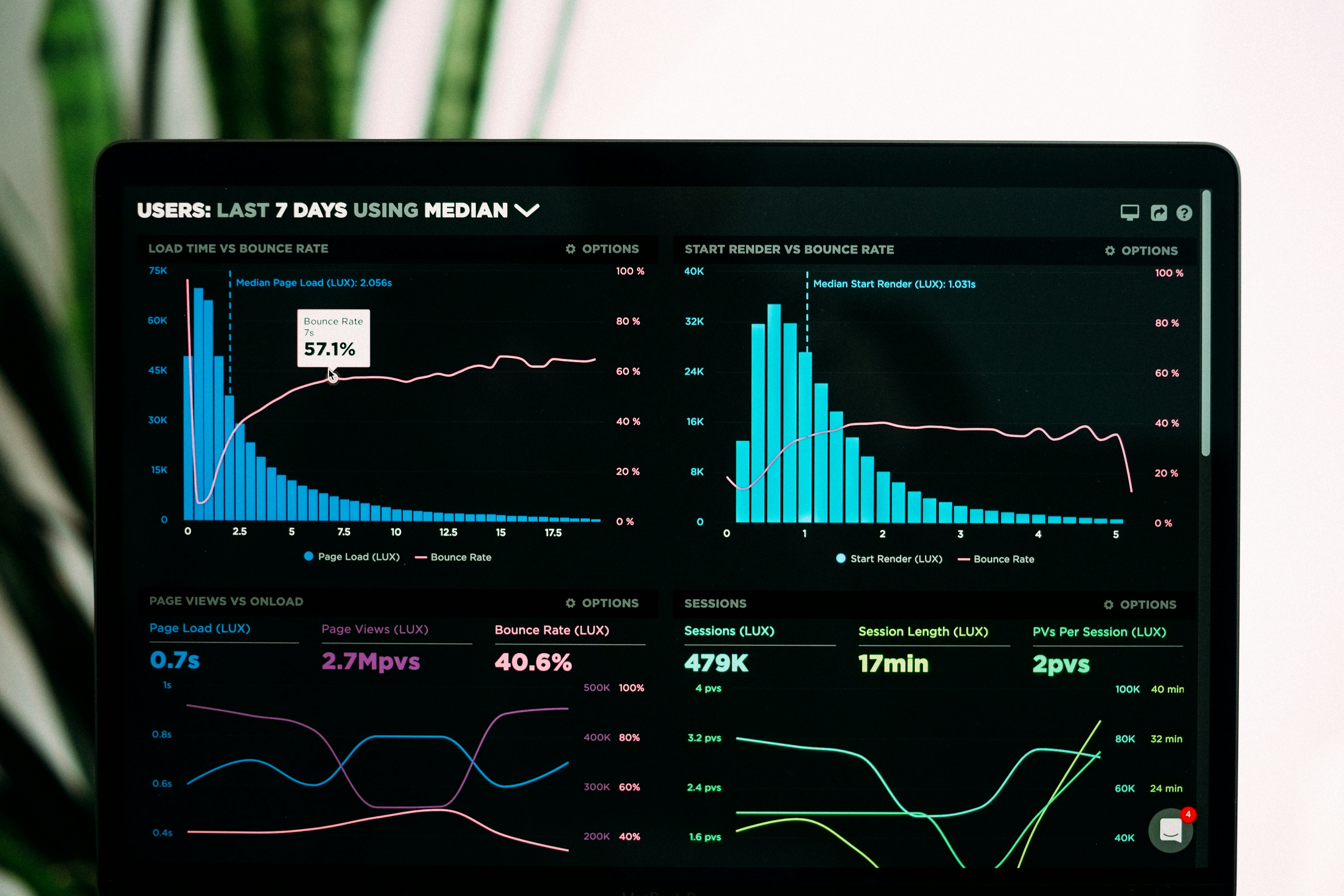
Descubre CRAFT: un entrenamiento único supera la divergencia de protocolos en IMVC. Elimina reentrenamiento y logra robustez en datos faltantes.
Descubre cómo los principios de contracción local y global aceleran la convergencia en algoritmos MCMC, con aplicaciones a Langevin y Metropolis-Hastings.
Descubre cómo recuperar comunidades exactas en hipergrafos no uniformes con algoritmos óptimos. Un umbral preciso incluso si las capas individuales fallan.
Descubre cómo la divergencia de la IA en 2026 impacta a líderes empresariales. Estrategias clave para navegar la transformación y asegurar la competitividad.

HiSE es un explicador ligero para redes neuronales de grafos heterogéneos con explicaciones semánticas jerárquicas de alta fidelidad y bajo costo.
El Drifting Generativo no es magia: es Score Matching. Aprende su teoría, la elección de kernels, y cómo estabilizar el entrenamiento con el operador stop-gradient.

Analizamos la propagación de errores en modelos de difusión con datos sintéticos. Primeras cotas inferiores de divergencia y regímenes de deriva.

Descubre cómo ELA, usando divergencia KL y mapeo cuantil beta, reduce un 30% el tiempo de entrenamiento al podar capas redundantes en atención por capas.
VAEs hipersféricos con Cauchy esférica: más eficiente y estable que vMF. Ideal para datos complejos.

Descubre cómo las garantías generalizadas para inferencia variacional con simetría par y elíptica aseguran la recuperación de media y correlación, incluso sin condiciones estrictas.
Aproxima divergencias-f con estadísticos de rango. Método rank-statistic para alta dimensión usando proyecciones aleatorias. Eficiente y validado.
Nuevas divergencias Wasserstein y Kalman-Wasserstein mejoran el control KL, ofreciendo soluciones estables incluso con ruido bajo: doble integrador y cart-pole.

Nuevo marco teórico para evaluar modelos generativos. Analizamos IPMs, divergencias y perplexidad. Ideal para investigadores en IA.

La cuantización agresiva reduce la precisión y alarga el razonamiento de los modelos de IA. Descubre cómo una penalización simple en tokens de 'overthinking' mejora la eficiencia.