Así aprendería Linux si empezara de cero
Descubre los errores que cometí al aprender Linux y cómo evitarlos. Basado en mi experiencia de 4 años usando exclusivamente Linux en mi trabajo.
Descubre los errores que cometí al aprender Linux y cómo evitarlos. Basado en mi experiencia de 4 años usando exclusivamente Linux en mi trabajo.

Descubre cómo las representaciones generalizadas de Fourier permiten aprender DNF bajo distribuciones no producto. Un avance clave en teoría del aprendizaje automático.

Aprende a adaptar el ruido latente usando funciones cuantiles para optimizar distribuciones previas en flujos generativos. Mejora el aprendizaje de colas pesada
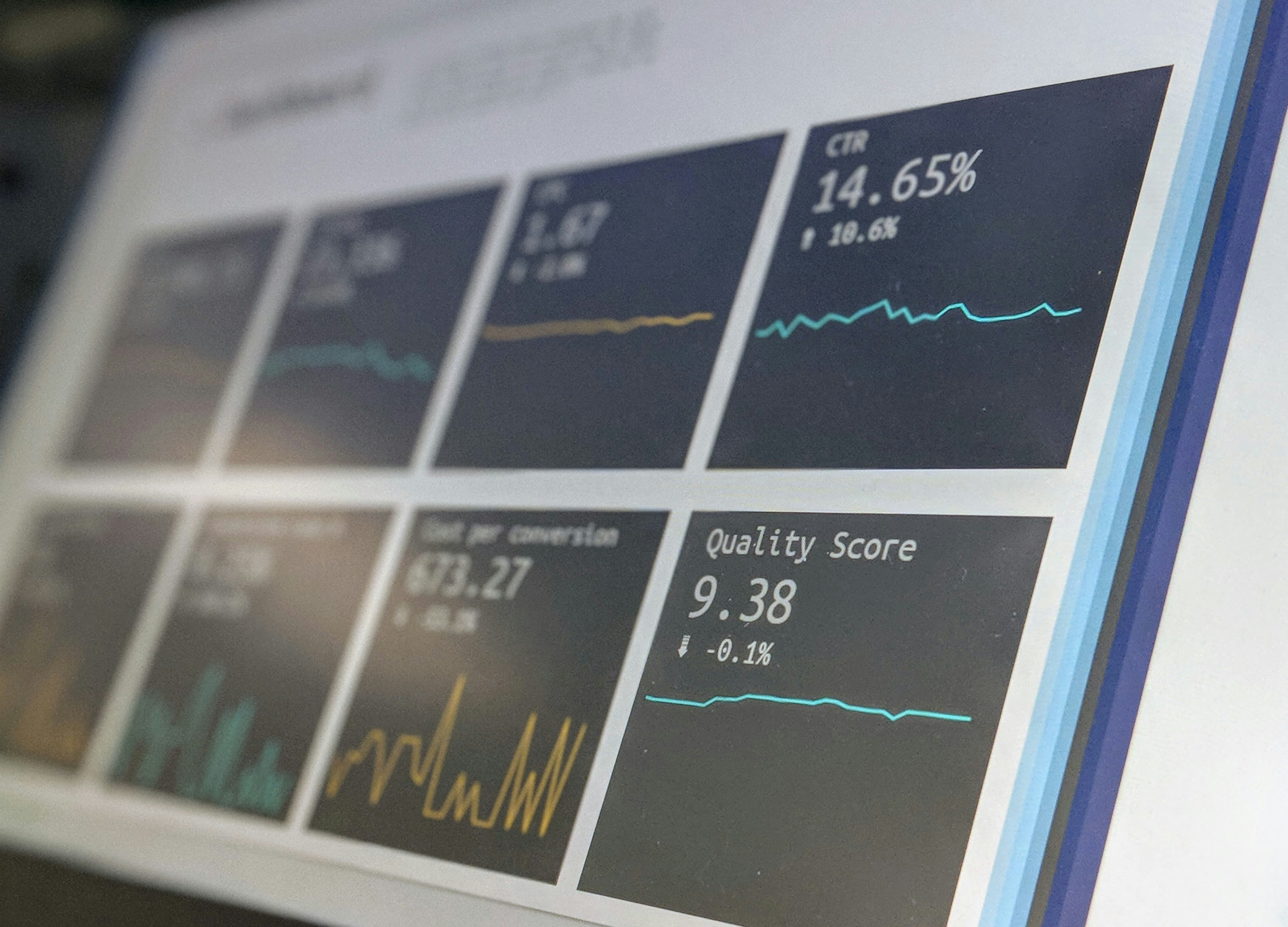
¿Pocos datos sesgan tus conclusiones? Detecta influencia excesiva con tests rigurosos basados en distribuciones extremas. Aplica en economía, biología y ML.

Descubre cómo el nuevo algoritmo A-MWGraD acelera la optimización multiobjetivo en espacios de Wasserstein, logrando convergencia O(1/t²) y mejor muestreo.

Descubre la robustez probabilística no paramétrica (NPPR), una métrica práctica que estima el riesgo de forma conservadora sin necesidad de conocer la distribuc
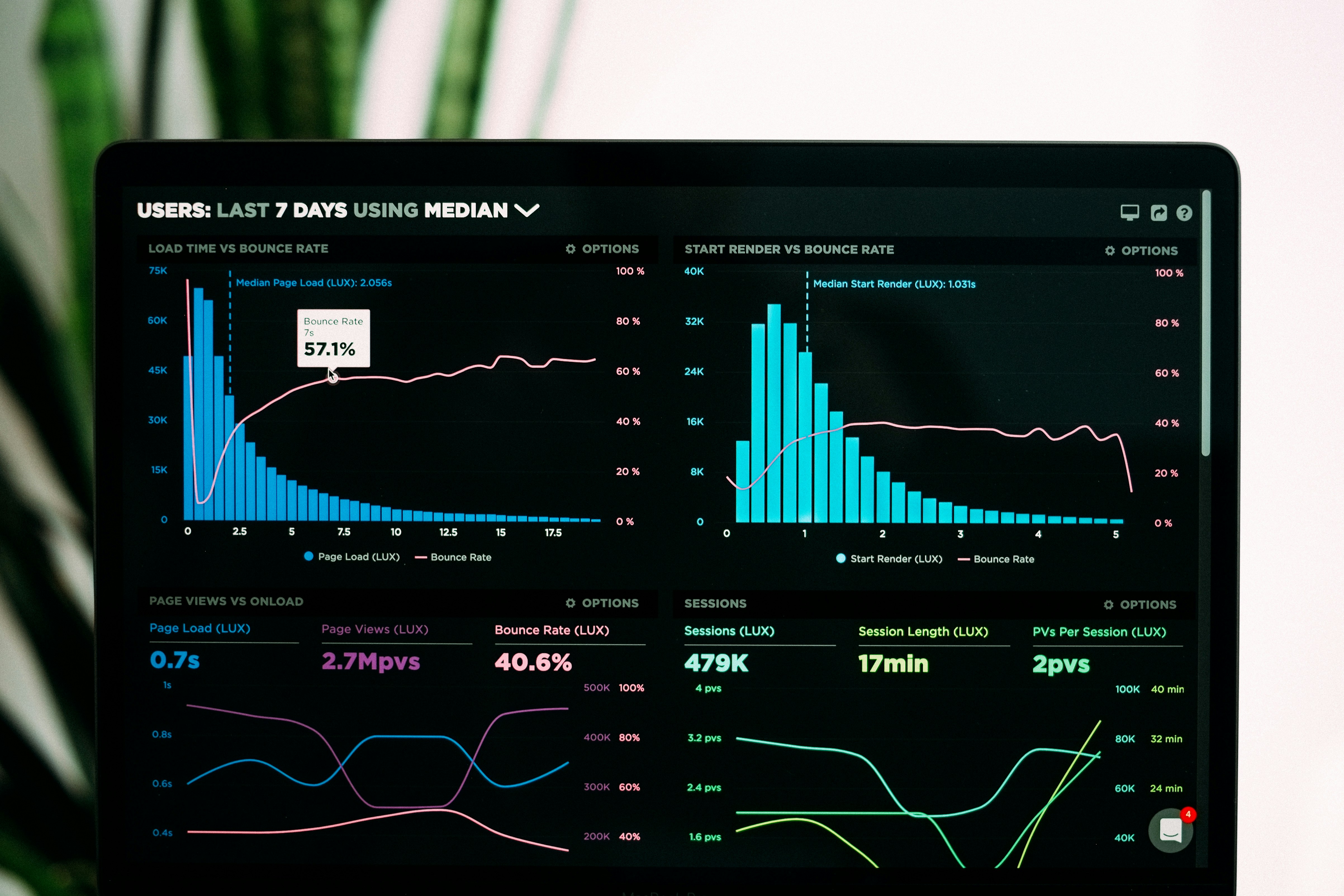
Descubre cómo un enfoque de prueba de distribución permite recuperar la partición oculta de distribuciones con cotas de complejidad de muestreo ajustadas.

E2M revoluciona la predicción de datos no euclidianos con deep learning. Conoce su teoría, rendimiento y aplicaciones en mortalidad y tráfico.

Descubre el análisis teórico del valor Shapley para localizar anomalías en sensores. Comparamos su rendimiento con tests más simples y revelamos sorpresas.
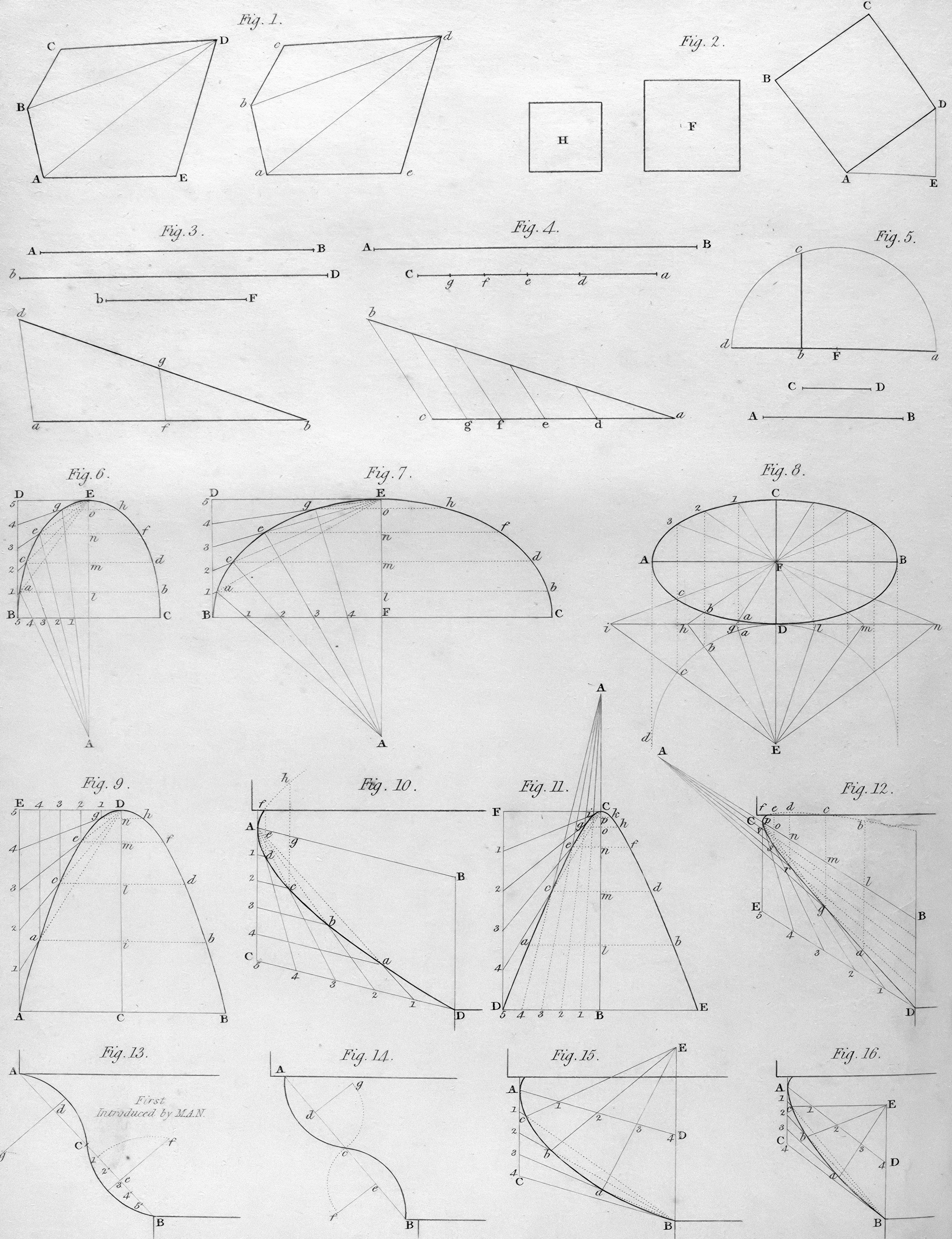
Descubre CDOT, un marco convexo de transporte óptimo que alinea distribuciones heterogéneas preservando geometría. Mejora robustez y precisión.

Descubre cómo las garantías generalizadas para inferencia variacional con simetría par y elíptica aseguran la recuperación de media y correlación, incluso sin condiciones estrictas.
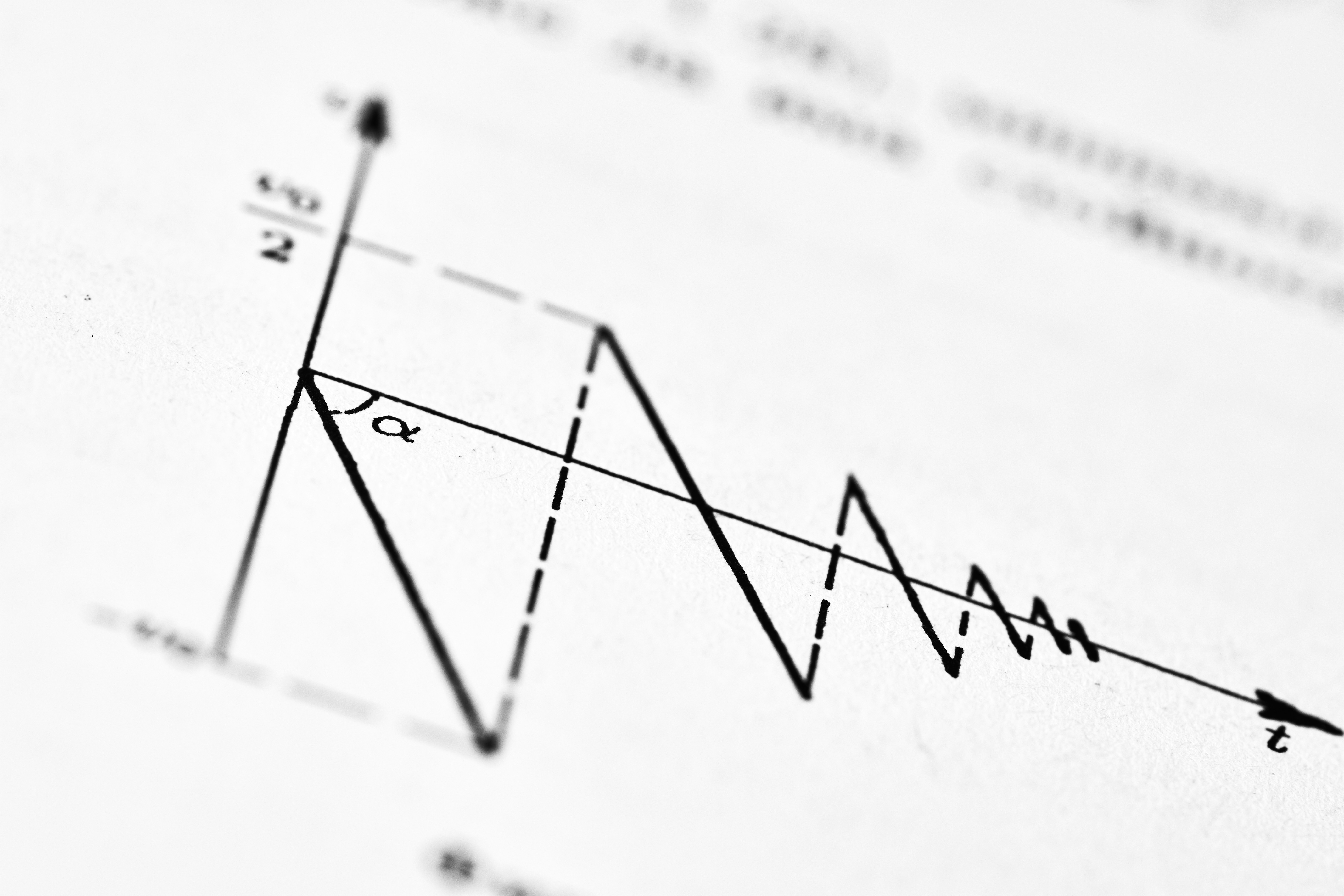
Aproxima divergencias-f con estadísticos de rango. Método rank-statistic para alta dimensión usando proyecciones aleatorias. Eficiente y validado.
Descubre cómo la estimación de razón de densidades con flujos condicionados permite comparar estados celulares en genómica para evaluar efectos de tratamiento.

Descubre cómo obtener garantías formales de rendimiento en aprendizaje por refuerzo multitarea para tareas no vistas, incluso con pocos datos.

El entrenamiento de LLMs converge lentamente por una razón fundamental: softmax y entropía cruzada generan un escalado de pérdida universal 1/3. Descubre las implicaciones.

Descubre DistMatch, nuevo método de agrupación adaptativa que mejora la robustez de la predicción conforme secuencial ante cambios de distribución.

¿Cómo se relacionan las leyes de escalado con las representaciones internas en deep learning? Este estudio revela una correlación entre rendimiento y estructura

Descubre cómo el Monte Carlo secuencial reforzado mejora el muestreo amortizado de distribuciones complejas. Entrenamiento off-policy y temperado adaptativo para mayor precisión.
Descubre cómo mejoramos la estimación de distribuciones discretas bajo norma infinito con nuevas cotas minimax y resultados empíricos prometedores.

Descubre cómo los flujos Wasserstein unifican GANs, MMD y modelos generativos con JKO. Una visión teórica para la optimización de distribuciones.