
ArrowFlow: Aprendizaje automático jerárquico en el espacio de permutaciones
ArrowFlow: modelo de aprendizaje automático en permutaciones sin parámetros flotantes. Competitivo, robusto al ruido, ideal para hardware neuromórfico.
ArrowFlow: modelo de aprendizaje automático en permutaciones sin parámetros flotantes. Competitivo, robusto al ruido, ideal para hardware neuromórfico.
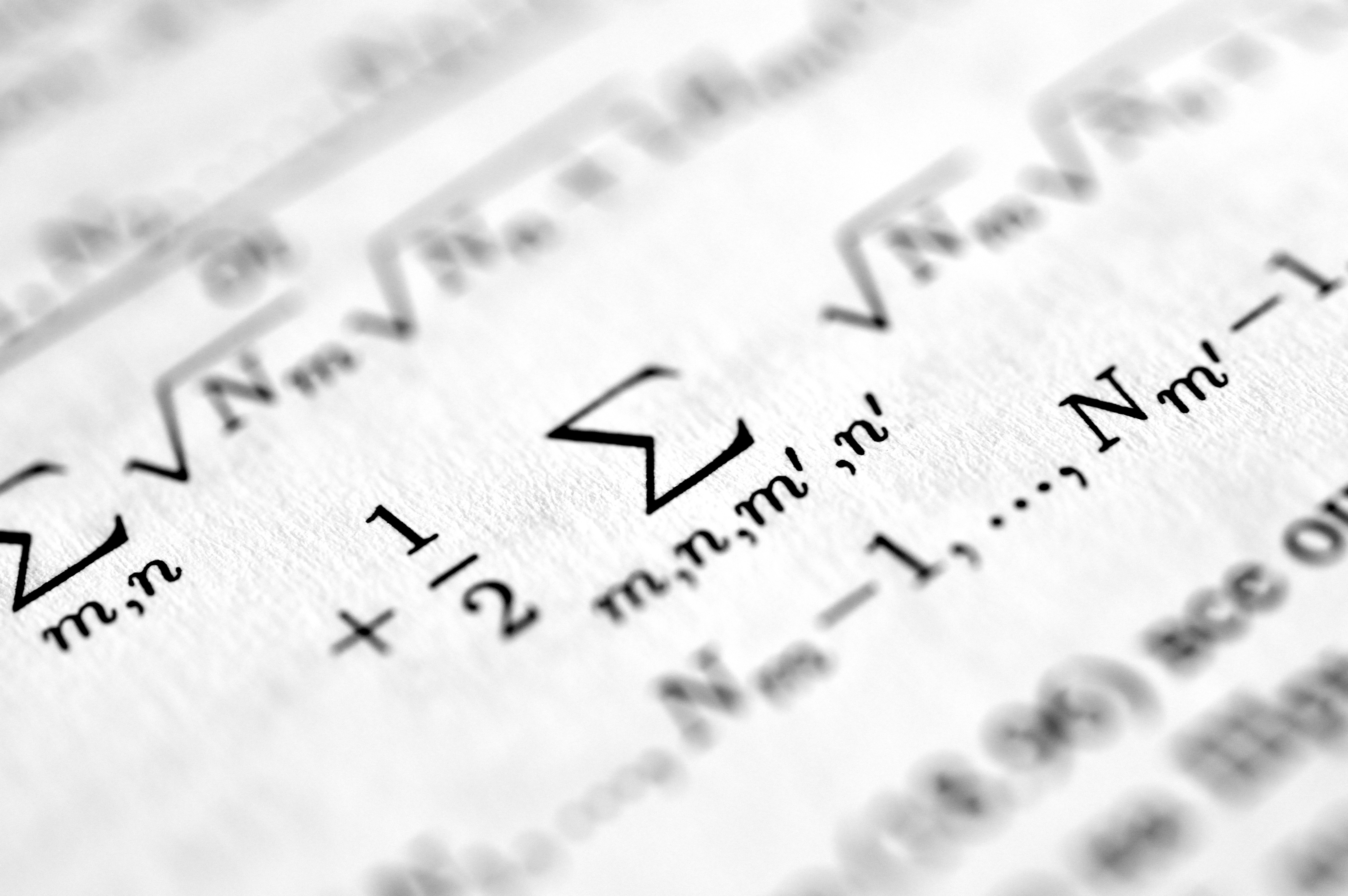
Descubre cómo un nuevo marco unifica y mejora algoritmos MCMC usando variables auxiliares, sin necesidad de evaluar la distribución objetivo. Mejor rendimiento en datos sintéticos y reales.

Descubre cómo la perspectiva codiciosa unifica dos técnicas de guía en generación. Ahorra cómputo sin perder precisión. Ideal para modelos de difusión.

Descubre cómo PipeDream logra convergencia en entrenamiento distribuido con un nuevo análisis teórico no convexo. Comparativa con LocalSGD.

Reveal-IG: atribución basada en caminos distribucionales. Atribuciones estables con signo sin artefactos. Ideal para explicabilidad en IA.

MAdam: el drop-in wrapper que mejora Adam en optimización multiobjetivo. Corrige sesgos de ponderación y geometría. ¡Conócelo!

Descubre TERA, un método que acelera procesos Gaussianos derivativos en altas dimensiones sin perder precisión. Ideal para simulaciones costosas.

Descubre MuLoCo, el optimizador con Muon que supera a DiLoCo, permite mayores batch sizes y mejor escalabilidad en entrenamiento de modelos de lenguaje.

Mejora la predicción de clima extremo con NTK-UQ: intervalos 31-37% más precisos, adaptativos y sin reentrenamiento.

Descubre MeSP: reduce un 49% la memoria al ajustar LLMs en dispositivos, con gradientes exactos. Ideal para entrenamiento privado.

Descubre cómo las entropías de grupo y la dualidad espejo crean una familia flexible de actualizaciones de descenso espejo para optimizar modelos de ML con mayor adaptabilidad y convergencia.

Cómo los gradientes estocásticos convergen con parámetros nuisance. Ortogonalidad de Neyman y actualizaciones ortogonalizadas para optimización robusta.

Descubre cómo estimar gradientes Poisson sin sesgo con el método EAT modificado. Comparativa con Gumbel-Softmax para VAEs y modelos de inferencia neuronal.

Descubre CORE-MTL, el nuevo enfoque de representaciones causales ortogonales que mejora la generalización en aprendizaje multitarea, reduce interferencias y supera métodos existentes.

Descubre cómo las redes neuronales recurrentes guiadas por física mejoran la predicción multietapa, incluso con datos limitados y modelos imperfectos.
Nuevo método SPS protegido para optimización no suave en redes neuronales. Convergencia robusta sin gradientes pequeños. ¡Mejora tu entrenamiento!
Un nuevo modelo generativo identifica componentes independientes en datos de conteo temporal con cambios de régimen. Aplicaciones en microbioma y clima.

Primer análisis teórico de complejidad muestral del Straight-Through Estimator para cuantización 1-bit. Descubre por qué el tamaño de muestra es clave para su éxito.

Descubre Quartet II, el método que optimiza el pre-entrenamiento de LLMs en formato NVFP4 en GPUs Blackwell. Mayor precisión y velocidad en tus modelos.

Protege tu privacidad en aprendizaje federado tabular. Vemos cómo los ataques de inversión de gradientes revelan datos. Descubre factores clave de riesgo.