
Factorización triple ortogonal no negativa para matrices simétricas
Descubre cómo resolver el problema de factorización triple de matrices no negativas ortogonales simétricas con dos nuevos algoritmos heurísticos. Aplicaciones en clustering y redes.
Descubre cómo resolver el problema de factorización triple de matrices no negativas ortogonales simétricas con dos nuevos algoritmos heurísticos. Aplicaciones en clustering y redes.

Descubre cómo GENERIC-FNO logra precisión de máquina en la preservación de leyes termodinámicas, superando a modelos previos en PDEs complejas.

Descubre cómo la transformada Neural de Legendre-Fenchel con precondicionamiento Hessiano mejora la precisión y convergencia en funciones mal condicionadas.

Descubre cómo la descomposición bulk-boundary revela dinámica intrínseca y estocástica de redes neuronales, con ecuación de continuidad de energía.

Aprende cómo la factorización CP y la doble proyección mejoran la estimación de cargas factoriales en series temporales tensoriales de alta dimensión.

Descubre TN-gram: un módulo de memoria compacto que mejora LLMs al compartir factores latentes entre embeddings de N-gramas con menos parámetros.

Descubre cómo el razonamiento contrafáctico mejora la precisión y fiabilidad del VideoQA al separar evidencia causal de correlaciones espurias. Ideal para sistemas de IA más confiables.

Descubre un nuevo método para auditar estrategias de inversión en IA basado en la descomposición exacta del arrepentimiento. Ideal para evaluar carteras y mecanismos de plataforma.
Descubre cómo la descomposición Lagrangiana resuelve problemas de gran escala en aprendizaje centrado en decisiones, mejorando eficiencia y paralelización.

SearchSwarm logra 68.1 en BrowseComp y 73.3 en BrowseComp-ZH, superando a modelos de su escala. Descubre cómo entrena la inteligencia de delegación.

Conoce LFNO, operador neuronal que une Laplace y Fourier para modelar sistemas dinámicos con descomposición transitorio-estacionaria, superando en ODE y PDE.

Descubrimos que el control de modelos de lenguaje depende de la interacción entre ángulo y norma. Explicamos por qué los métodos de steering difieren y proponem

Aprende a construir habilidades (skills) para agentes de IA desde trazas heterogéneas con el método RWSA. Mejora la consistencia de comportamiento en un 10.5% – sin escritura manual.
Descubre cómo el POD multiescala con wavelet Morlet extrae modos energéticos de atención en transformers, revelando jerarquía de escalas sin anotaciones.

Aplicamos POD multiescala con wavelet de Morlet a campos de atención de transformers, revelando modos dominantes y organización por capas. Sin modificaciones arquitectónicas.

Descubre SigmaScale, método para comprimir LLMs con descomposición SVD y matrices de escala aprendidas. Reduce costo computacional sin perder rendimiento.
Descubre la Descomposición Proxy de Benders: acelera optimización a gran escala con gaps <0.5% y hasta 161x más rápido, reduciendo cortes en 240x. ¡Lee más!

Estudio comparativo de RAG adaptativo orquestado por agentes: mejoras en precisión en dominios estructurados pero costos de latencia en multi-salto.
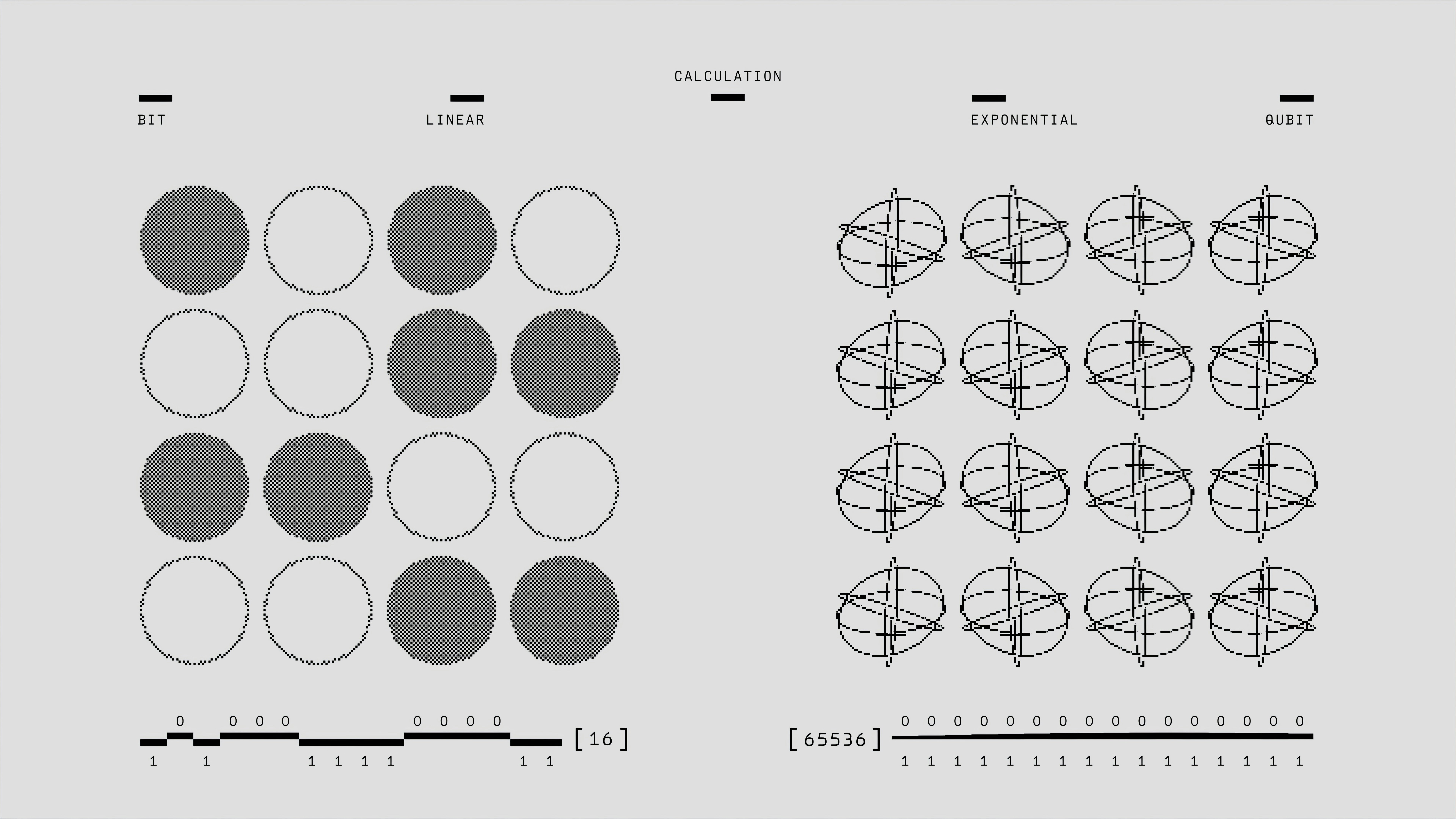
Descubre TailLoR, un método que protege los componentes principales usando descomposición espectral para un aprendizaje continuo eficiente y sin interferencias.
Descubre cómo la descomposición SVD funcional dispersa identifica patrones ocultos en datos longitudinales, aplicado a enfermedades inflamatorias y señales EEG.