
La paradoja de la optimización por resultados en LLMs
Los LLMs optimizados por resultados alcanzan altos benchmarks pero colapsan en razonamiento. Te explicamos la paradoja y cómo los modelos de recompensa de procesos la resuelven.
Los LLMs optimizados por resultados alcanzan altos benchmarks pero colapsan en razonamiento. Te explicamos la paradoja y cómo los modelos de recompensa de procesos la resuelven.
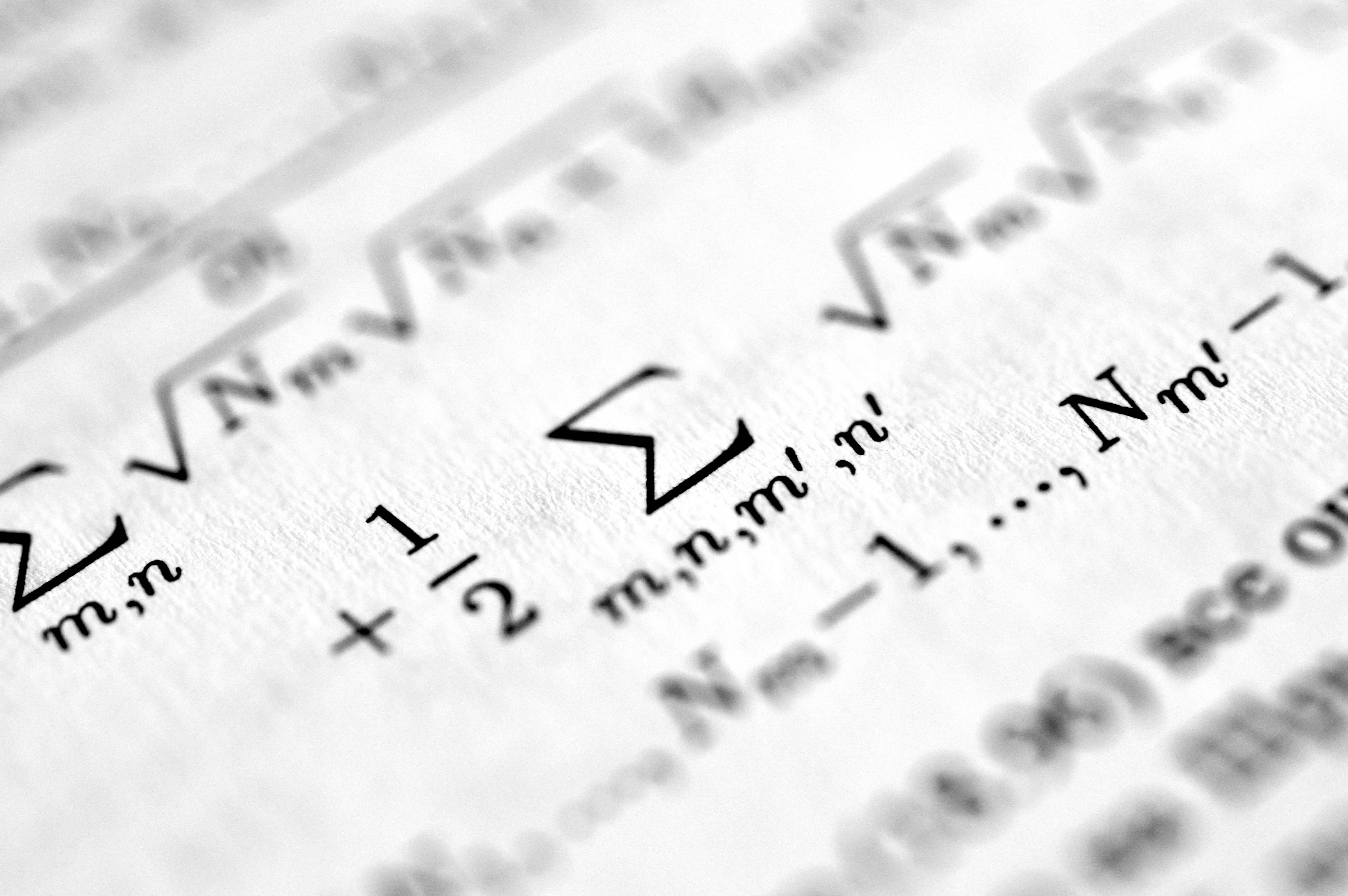
Descubre cómo el marco de Lyapunov permite analizar la convergencia en tiempo finito de algoritmos estocásticos como Q-learning y SGD. Ideal para IA y RL.
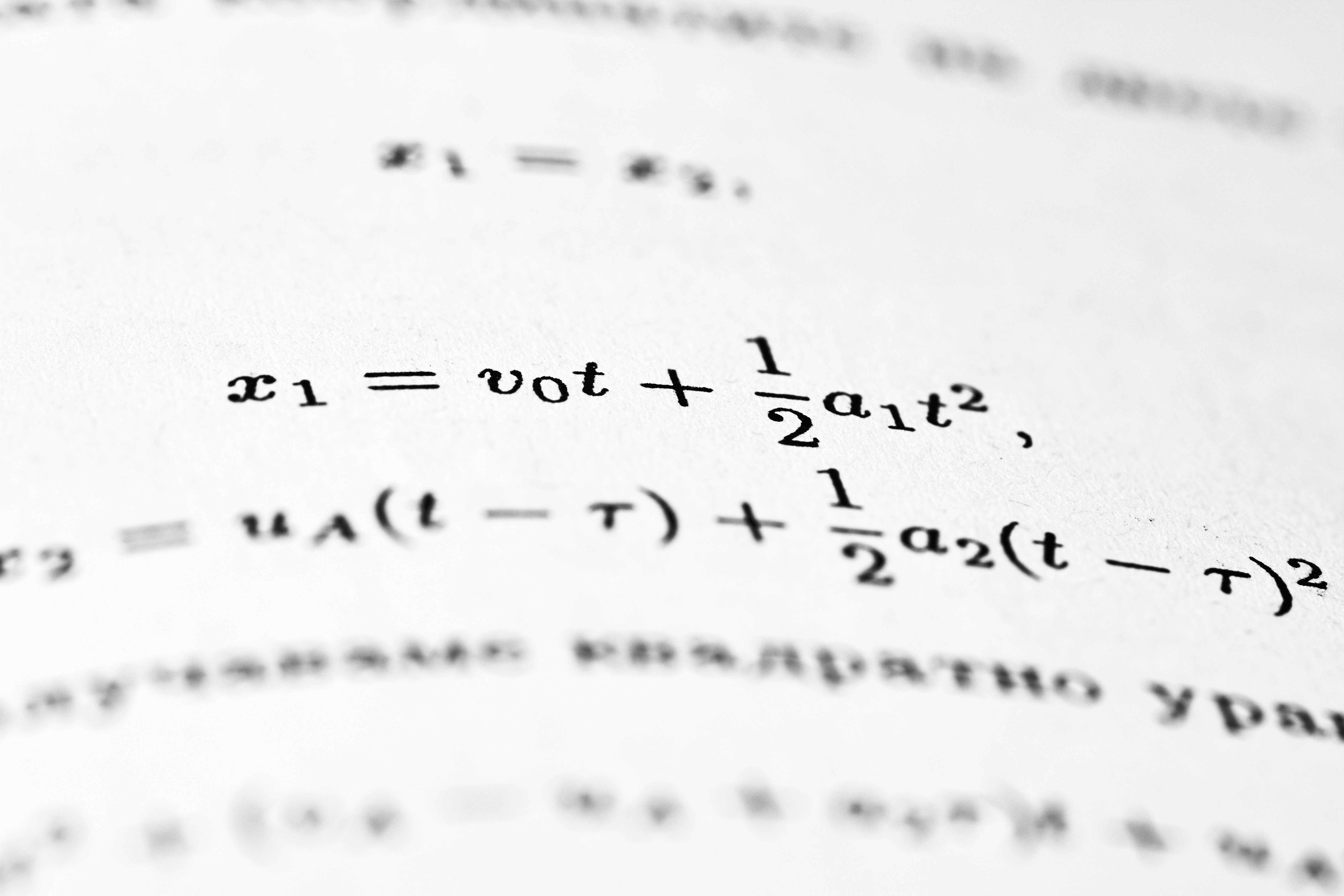
Descubre cómo el descenso más pronunciado y Adam logran convergencia lineal bajo suavidad no uniforme, superando a GD, AdaGrad y otros.