
Optimización de Políticas Guiada por Física con Autodestilación
Descubre PGPO, un nuevo método de optimización guiado por la física que estabiliza el post-entrenamiento de LLMs, mejorando hasta 4.5 puntos en Science-QA.
Descubre PGPO, un nuevo método de optimización guiado por la física que estabiliza el post-entrenamiento de LLMs, mejorando hasta 4.5 puntos en Science-QA.

Descubre TurtleAI, el benchmark que evalúa modelos multimodales en programación visual con Turtle Graphics. Muestra fallos y cómo el ajuste fino mejora un 20%.

El método SHARS reduce alucinaciones en generación de textos largos usando muestreo de rechazo. Mejora la consistencia factual sin recursos externos. ¡Descúbrelo!

Descubre VidMsg, el benchmark que evalúa cómo los modelos de IA entienden mensajes implícitos en videos cortos. ¡Resultados que te sorprenderán!
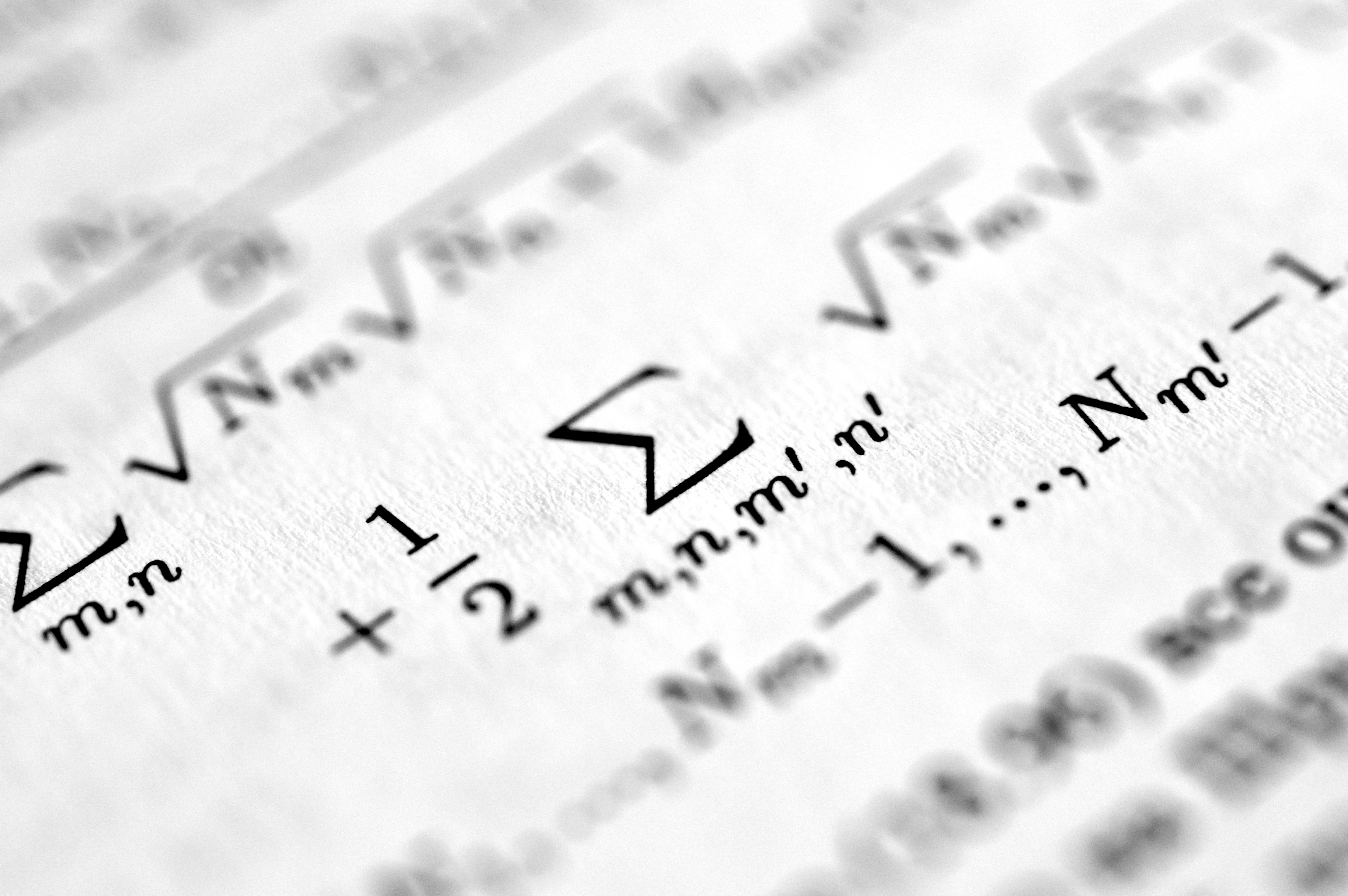
Descubre cómo los LLMs representan la suma geométricamente y por qué cometen errores. Un nuevo estudio revela la estructura oculta de la aritmética.

Descubre CoEval: un framework que evalúa y rankea modelos de lenguaje sin necesidad de datos etiquetados ni benchmarks fiables. Resultados limpios y por solo $5.89.

¿Aprenden los LLM a representar el modelo del mundo al planificar? Este análisis revela cómo el ajuste supervisado codifica la validez de acciones y predicados.

Aprende cómo aplicar modelos fundacionales tabulares al análisis de supervivencia sin entrenamiento. Resultados competitivos con Cox y AFT. ¡Entra!

Descubre cómo Qwen-Image-Flash optimiza el pipeline de entrenamiento en destilación de pocos pasos para modelos visuales, yendo más allá del diseño objetivo.

Descubre cómo E2LLM optimiza el despliegue de LLMs en entornos Edge/Fog, reduciendo el tiempo de espera en más del 50%.

Descubre cómo la aumentación sintética de tareas sustituye la curación humana en RLVR, reduciendo costos sin perder rendimiento en benchmarks de código y razonamiento.

Un estudio revela que el entrenamiento por consistencia puede afianzar la desalineación en modelos de IA. Descubre sus efectos contradictorios en la alineación.

Los agentes de IA crean gusanos adaptativos que se propagan sin costo para el atacante. Descubre la nueva amenaza cibernética.

La evaluación con pocos ejemplos revela nuevas perspectivas sobre estabilidad y plasticidad en aprendizaje continuo. El meta-aprendizaje mejora la adaptación.

Aprende cómo la autoevaluación por clusters permite a los LLMs medir su incertidumbre con solo dos muestras, mejorando la confiabilidad de sus respuestas.

Descubre FLARE: retroalimentación precisa a nivel de línea para depurar código LLM. Mejora la precisión hasta un 8.5%.

Descubre cómo medir el rol de cada codificador en modelos VLM multicodificador. Capacidad y Necesidad revelan pares óptimos para entrenar sin acumular. Investigación con 16 benchmarks.

Descubre q0: primitivas para preentrenar con hiper-épocas. Genera una población de modelos diversos que logran menor pérdida de validación con hasta 4.6x menos épocas.

AlignAtt4LLM logra traducción simultánea inglés-alemán/italiano con baja latencia aplicando AlignAtt en LLMs solo decodificador. Resultados superiores.

¿Los modelos de razonamiento grandes expresan su confianza de forma fiel? Cuantificamos la calibración entre incertidumbre interna y verbalizada, revelando desa