
Robo de modelos a través del lente de la multiplicidad
Descubre cómo la multiplicidad de modelos revela que los sustitutos de alta fidelidad no son equivalentes al original, afectando seguridad y equidad.
Descubre cómo la multiplicidad de modelos revela que los sustitutos de alta fidelidad no son equivalentes al original, afectando seguridad y equidad.

MoECa acelera hasta 2.83x la inferencia de Transformers de Difusión con Mixture of Experts, manteniendo la calidad.

Re-alimentar el prompt introduce ruido en crédito contrafactual, afectando selección de tokens. Estudio vLLM revela diferencias hasta 28pp.

Aprende cómo el marco FC-MoE resuelve conflictos en el ajuste fino federado de modelos de lenguaje grandes con mezcla de expertos, mejorando convergencia y
Descubre cómo la distorsión estructural en atención de LLMs perjudica el razonamiento en grafos y cómo GaLA lo corrige. Mejora sin sobrecarga.

HAPI-EP: marco de IA para gemelos digitales cardíacos híbridos, adaptativos y predictivos. Se adapta en tiempo real a datos del paciente.
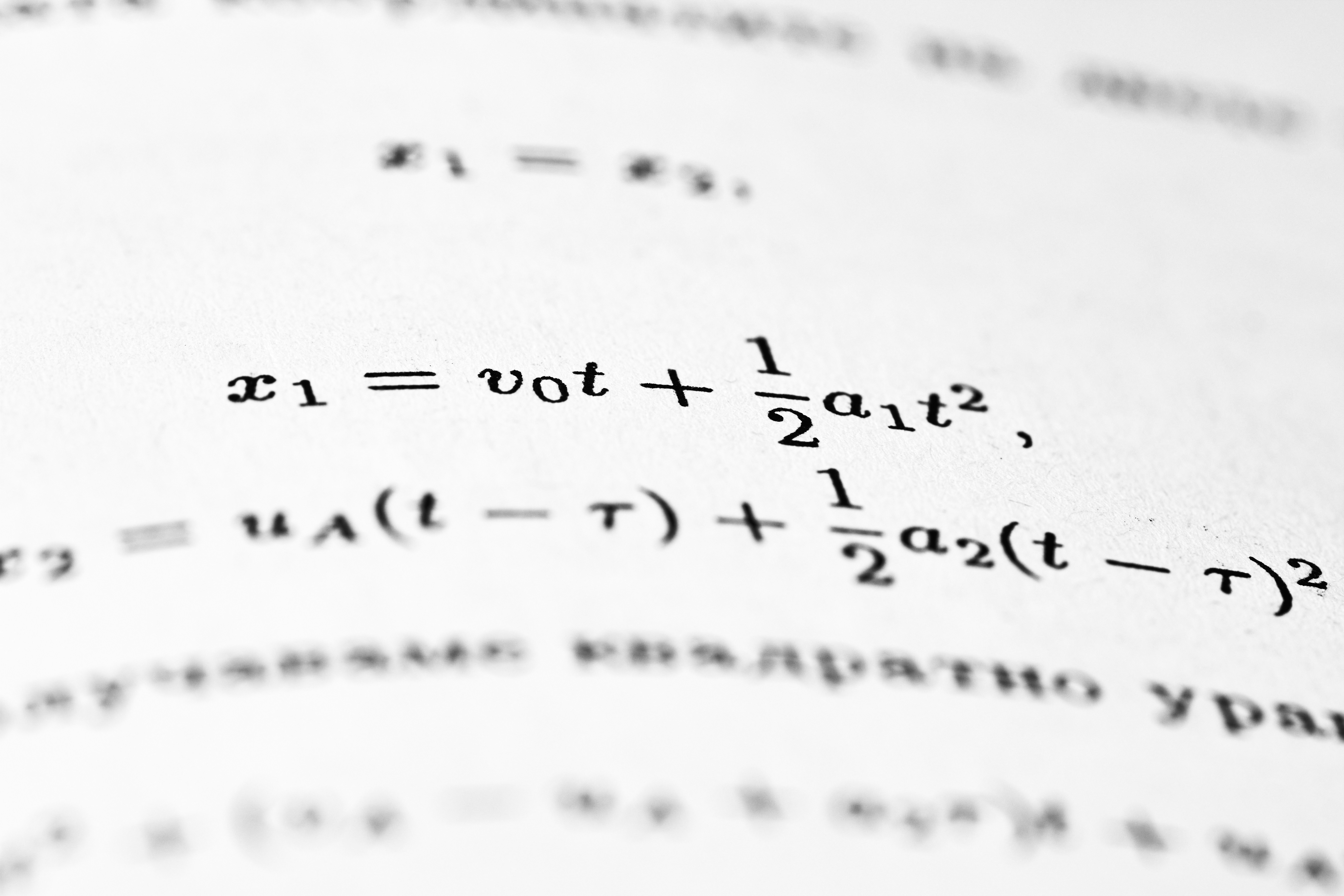
Descubre MosaicQuant: cuantización 4-bit unificada que preserva precisión casi FP16 y acelera hasta 1.24x en LLMs. ¡Optimiza tu inferencia!

Descubre ReQAT, el método que logra precisión completa en modelos de razonamiento grandes con cuantificación FP4, reduciendo costos y acelerando el rendimiento

Descubre cómo FC-MoE optimiza el ajuste fino federado de LLMs con mezcla de expertos, resolviendo conflictos entre clientes para acelerar la convergencia y

Optimiza modelos MoE con poda de expertos de un solo disparo: conoce la formulación unificada y los criterios MAN y MSAN que logran hasta 8.8 puntos de mejora.

Descubre cómo UL4M4 imputa modalidades faltantes en aprendizaje multimodal usando clustering no supervisado, logrando F1 >0.7 incluso con más del 50% de datos

ReQAT logra precisión de razonamiento completa usando cuantificación FP4 de 4 bits, con aceleración de hasta 3.9x en NVIDIA DGX Spark. Descubre cómo.

Coordinación de actualizaciones paralelas en modelos de difusión para mejorar calidad y latencia en generación de texto y código. Descubre cómo.

Descubre cómo Multi-Fidelity SINDy mejora la identificación de sistemas dinámicos no lineales usando datos de baja y alta fidelidad.

¿Quieres reducir memoria en modelos MoE sin perder rendimiento? Descubre un principio de selección unificado que mejora hasta 8.8 puntos en benchmarks.
Descubre cómo UL4M4 imputa embeddings faltantes en aprendizaje multimodal mediante clustering no supervisado, logrando F1 >0.7 incluso con >50% de datos

Mejora la eficiencia de modelos de difusión discretos con decodificación paralela de campo medio. Coordina actualizaciones para generar más tokens por paso sin

¿Un simple contador supera a modelos de IA? Este benchmark revela que argmax iguala o supera a LSTM, Transformer y LLMs.
Descubre cómo GRPO entrena LLMs para predecir eventos reales, logrando que un modelo de 1.5B supere a Claude Sonnet 3.5. Resultados sorprendentes.

Aprende cómo ProGenMech descubre circuitos neuronales en modelos de proteínas para mejorar la generación y predicción de fitness.