
Reward Hacking en Agentes de Lenguaje: Revisitando Gridworlds de Seguridad
Aprende cómo el reward hacking engaña a los agentes de lenguaje y por qué el RL no lo soluciona. Estudio basado en Gridworlds de seguridad.
Aprende cómo el reward hacking engaña a los agentes de lenguaje y por qué el RL no lo soluciona. Estudio basado en Gridworlds de seguridad.

Descubre cómo los LLM optimizan problemas complejos: enfoques directos, con herramientas o creando algoritmos. Conoce las fronteras de rendimiento y el futuro.

Descubre CoTE-SQL, un nuevo método que integra razonamiento y generalización en Text-to-SQL mediante ajuste fino auto-mejorado, logrando mejores resultados en

Descubre cómo la IA incorporada integra percepción, decisión y acción para la salud del futuro. Revisión de modelos y aplicaciones clínicas.

Supera el desajuste de impedancia: fusiona modelos fundacionales y grafos de conocimiento con esta hoja de ruta teórica.

El nuevo benchmark RecurrReason evalúa la verdadera capacidad de razonamiento de modelos de IA en puzzles simbólicos. Descubre por qué fallan en River Crossing.

Descubre cómo RoboPIN con PinCoT mejora el razonamiento incorporado usando anclas visuales, logrando un 12% más de precisión en benchmarks.

Heterogeneidad estructural en señales de incertidumbre limita optimización en verificación de LLM. Intervención simple mejora tasa de aciertos 17%.

Descubre cómo RetailBench pone a prueba la toma de decisiones de agentes LLM en supermercados simulados durante 180 días.

STRIDE mejora el RLVR con estimación discriminativa: asigna créditos precisos a patrones estratégicos. ¡Optimiza el razonamiento de tu IA!

UrbanWell: benchmark para evaluar modelos multimodales en análisis de bienestar urbano espacio-temporal. Descubre sus resultados y rendimiento.

Mind-Studio crea modelos de mundo ejecutables de juegos, con 48.7% de precisión en predicción de estados, superando métodos anteriores. Perfecto para IA y

Descubre cómo el pensamiento visual con grounding mejora el razonamiento de modelos de IA, vinculando pensamientos a regiones de imagen para mayor precisión.
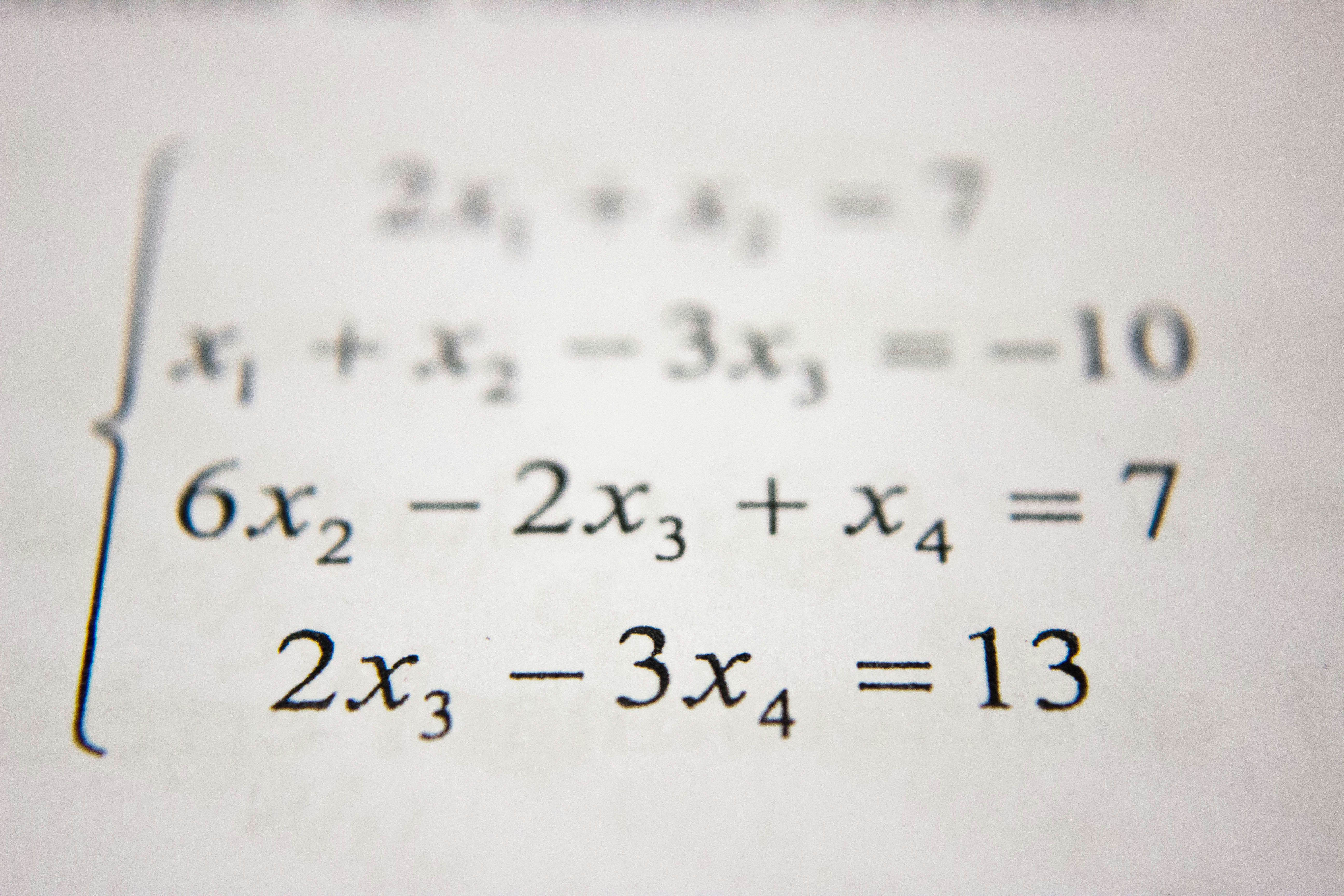
Descubre por qué los datos de alta recompensa dañan el razonamiento matemático en modelos pequeños y cómo la alineación de estilo mejora la destilación.

TimeVista utiliza VLM como jueces para evaluar pronósticos de series temporales, logrando una alineación humana superior a métricas tradicionales.

Descubre cómo Latent Thought Flow mejora la precisión un 9.5% y reduce el tiempo de razonamiento un 27.2% en modelos de lenguaje grandes. Nuevo método de

Descubre cómo SpecAlign utiliza datos sintéticos para alinear modelos de lenguaje con especificaciones detalladas, mejorando el cumplimiento de reglas sin

AdaSTORM escala el razonamiento de LLM en grafos dinámicos a miles de nodos con más del 90% de precisión, superando límites de contexto y coste.

Auditoría algorítmica revela cómo los LLM recomiendan hoteles: precio y calificación mandan, pero el orden de lista influye como si costara 12€/noche.

METIS: fusión many-shot con equilibrio de pérdida para superar interferencia entre tareas y evitar borrado de información. Mejora la peor tarea.