
The Atlantic crea base de datos de música usada para entrenar IA
El Atlantic revela una base de datos de millones de canciones usadas para entrenar IA. Google y Stability AI la han utilizado. Descúbrela.
El Atlantic revela una base de datos de millones de canciones usadas para entrenar IA. Google y Stability AI la han utilizado. Descúbrela.

Descubre la encuesta más completa sobre datasets de lengua de señas: 120 recursos, 35 lenguas, desafíos de anotación y benchmarks. Ideal para investigadores y

Descubre PrefSQA: predicción de preferencias pareadas para evaluar calidad de voz. Datasets de alta calidad mejoran resultados. Sin MOS.

Descubre cómo la localización por nacionalidad en datasets multilingües de salud mental causa inconsistencias y sesgos al evaluar depresión por LLM.

Descubre cómo elegir modelos neuronales más rápidos y pequeños para datasets con pocas clases. Ahorra recursos sin perder precisión.
Aprende a clasificar modelos OCC con correlación de ranking y vecino cercano. Alta precisión en datasets y algoritmos. Código público.
Meta-clasificación de modelos OCC con ranking y vecino cercano: alta precisión clasificando datos y algoritmos. Solución unificada de modelos, datos y rankings.

Descubre FineGen, un marco multiagente basado en VLM que construye datasets de imagen-texto con muestras negativas duras, logrando un 96.7% de validez y +14.4%
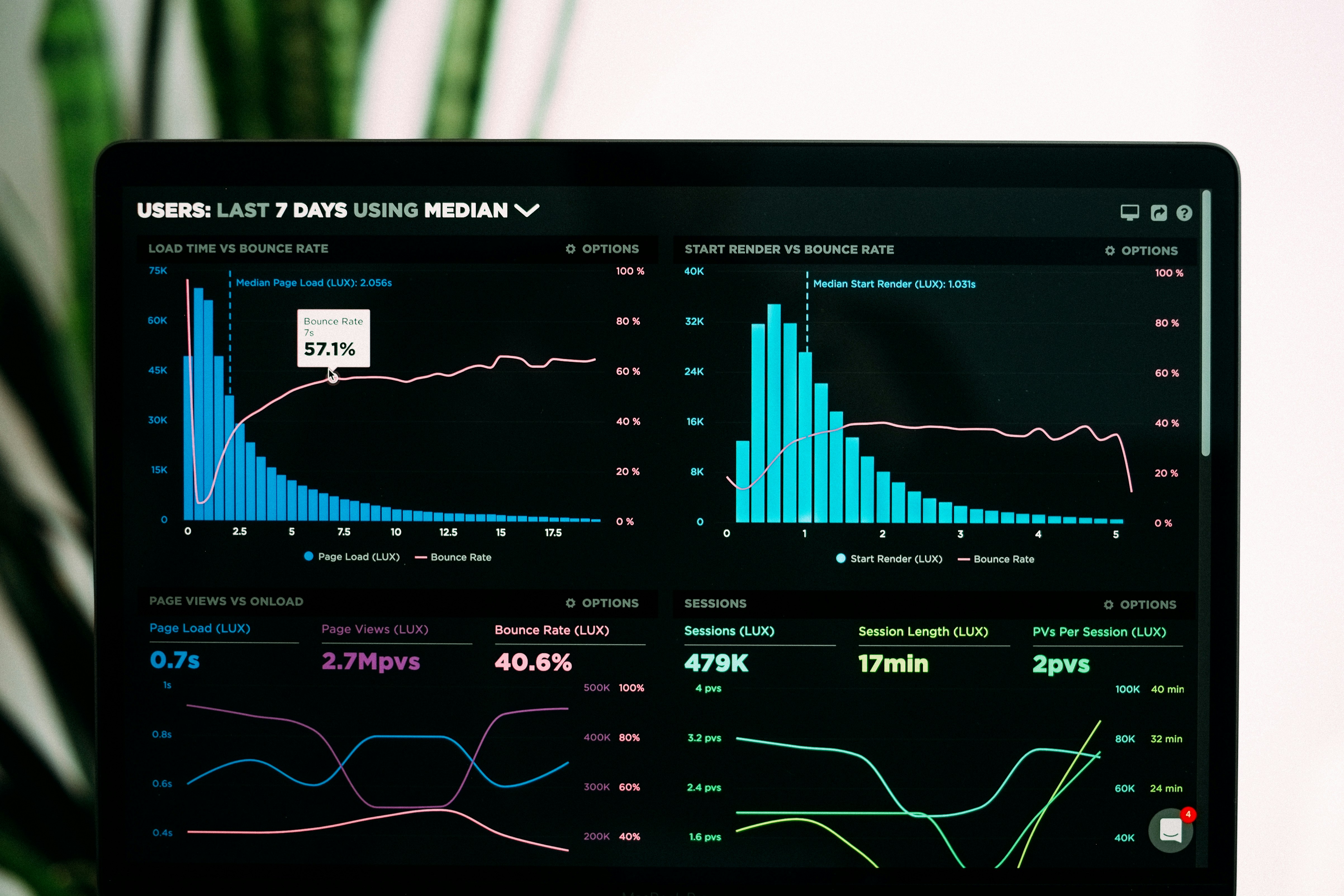
Descubre cómo UL4M4 imputa embeddings faltantes en aprendizaje multimodal mediante clustering no supervisado, logrando F1 >0.7 incluso con >50% de datos
Descubre los desafíos y benchmarks en segmentación de imágenes médicas con métodos U-Net, Transformer y SAM. Guía para investigadores y profesionales.

Descubre cómo un enfoque feminista y colaborativo busca reparar el trabajo con datos para la seguridad en línea, redefiniendo la responsabilidad en la IA.

Comparativa de estrategias de generación de preguntas para razonamiento procedimental. La generación estricta TMK logra 96.5% de preguntas fundamentadas.

Plataforma que integra OCR para convertir fórmulas a LaTeX, facilitando la colaboración y generando datasets para entrenar IA en razonamiento matemático.

Descubre SDQM, la métrica que evalúa la calidad de datos sintéticos para detección de objetos sin necesidad de entrenar modelos. Ahorra tiempo y recursos.
Aprende cómo DeMix diagnostica errores mixtos en datos de entrenamiento usando vectores de influencia. Logra un 22.61% más de precisión en limpieza de datos.

Descubre RCAP, un algoritmo de poda dinámica que mantiene alta precisión en clases minoritarias usando solo el 10% de los datos. ¡Acelera tu entrenamiento!

GraspLLM combina LLMs y aprendizaje contrastivo para generalizar sin entrenamiento en múltiples datasets de grafos textuales. Logra rendimiento superior zero-shot.

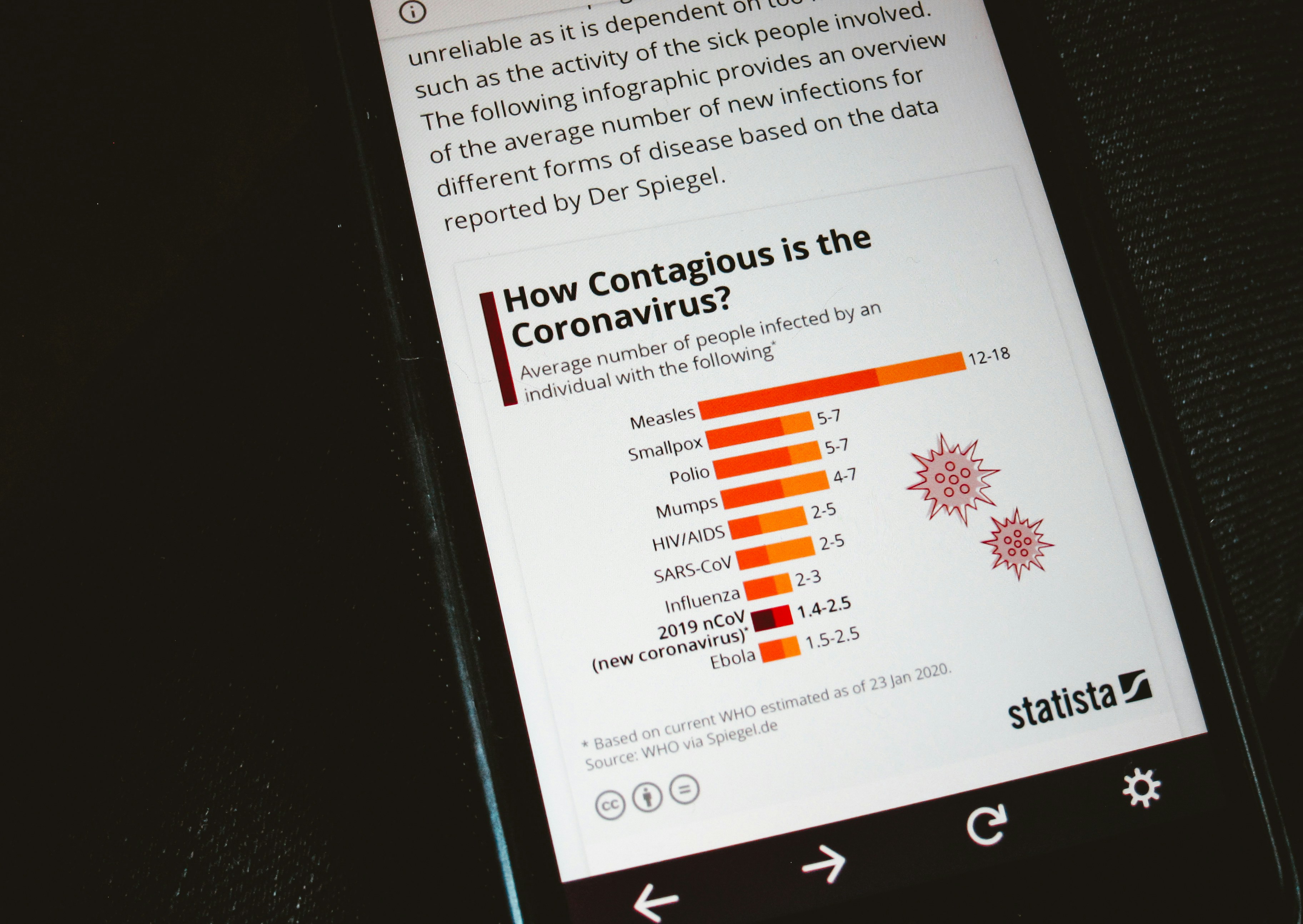
Un análisis de 39 datasets de voz deepfake revela graves carencias de metadatos demográficos y superposición de fuentes, comprometiendo la equidad y la validez de los detectores.

Descubre EEVEE, marco de aprendizaje de prompts en tiempo de prueba para agentes LLM que maneja múltiples datasets y mejora el rendimiento hasta un 48%

Descubre Multi-PixMo, un conjunto de datos multilingüe para entrenar modelos de lenguaje visual. Mejora el rendimiento en 5 idiomas europeos con benchmarks traducidos. ¡Optimiza tu VLM!