
Reduciendo la complejidad de modelos de deep learning para EEG en wearables
Aprende a reducir la complejidad de modelos de deep learning para EEG en wearables con cuantización y reducción de electrodos, manteniendo la precisión.
Aprende a reducir la complejidad de modelos de deep learning para EEG en wearables con cuantización y reducción de electrodos, manteniendo la precisión.

Descubre cómo TWLA, mediante cuantización post-entrenamiento, reduce el tamaño y acelera la inferencia de LLMs usando pesos ternarios y activaciones de 4 bits.

TWLA permite cuantizar LLMs a pesos ternarios y activaciones de 4 bits, reduciendo el costo de inferencia sin perder precisión.

Descubre ReSET, un método que mejora la precisión de modelos de razonamiento en NVFP4 mediante escalado de temperatura por pasos, con hasta 2.5x de aceleración en decodificación.

¿Quieres ejecutar modelos de lenguaje como 70B en tu PC con solo 8GB de VRAM? Descubre técnicas de cuantización y optimización en esta guía práctica.

Descubre cómo SPEAR recupera hasta 75% de la brecha de calidad en cuantización de LLMs, con mínimo overhead y latencia estable. Ideal para despliegues eficientes.

Descubre q-PDGD, un método primal-dual cuantizado que logra convergencia lineal en optimización distribuida con gradientes estocásticos y comunicación de bits limitados.

Descubre cómo combinar aprendizaje federado, privacidad diferencial y cuantización INT8 para detectar anomalías en ECG en dispositivos edge, manteniendo alta precisión. ¡Lee más!
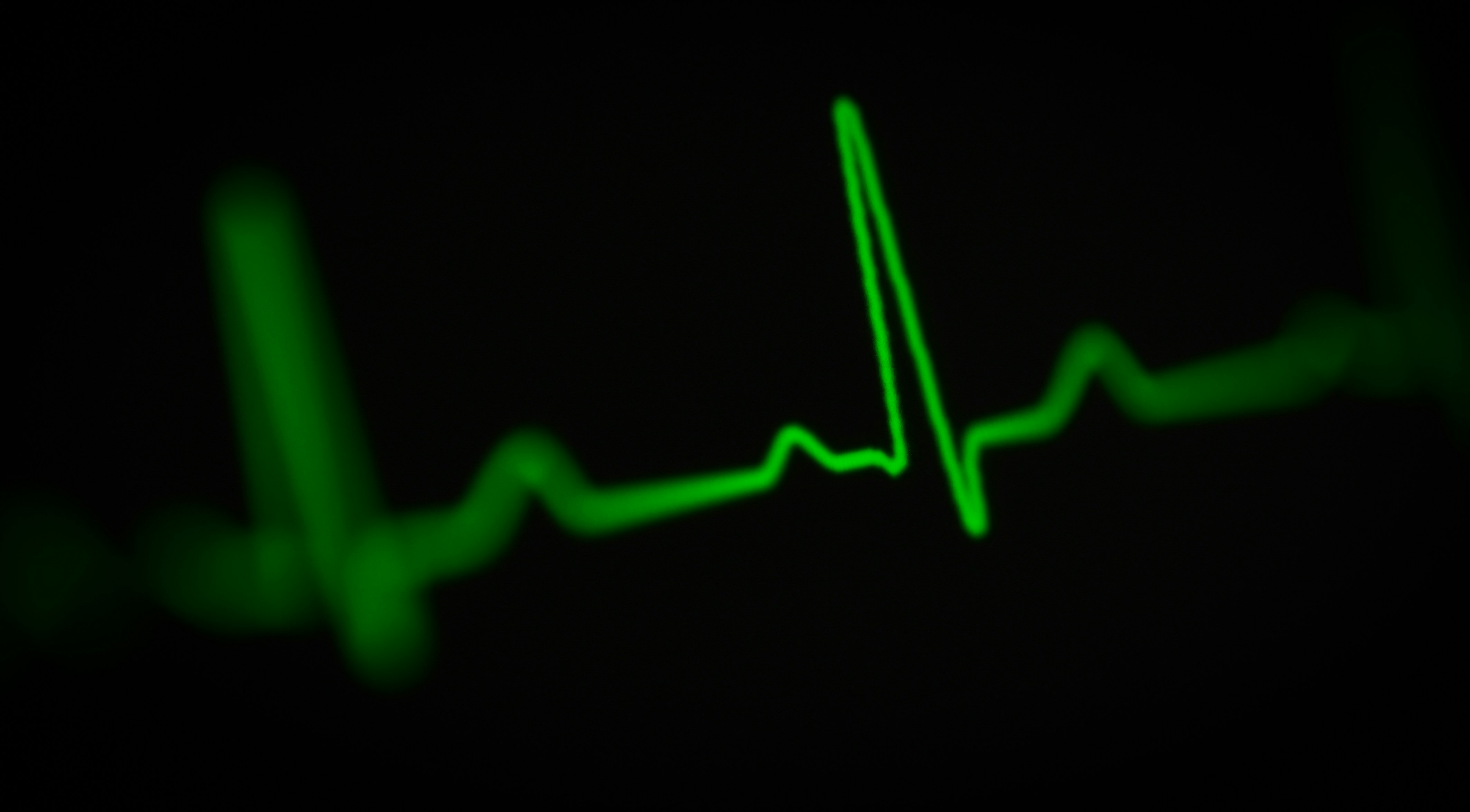
Aprende cómo un sistema federado con autoencoder, privacidad diferencial y cuantización INT8 detecta anomalías en ECG en edge, cumpliendo GDPR.

Descubre VQLC, alternativa escalable al clustering para descubrir conceptos en LLMs con alta coherencia.

Descubre cómo cuantizar Ideogram 4.0 a INT8 y GGUF para GPUs Ampere, manteniendo la calidad FP8 y mejorando el rendimiento.
Descubre cómo la cuantización limita la recuperación top-k en bases de datos vectoriales. Un estudio teórico revela que la dimensión y precisión deben crecer con el corpus.

Descubre cómo la cuantización de caché KV puede destruir la alineación de seguridad en LLMs y cómo PCR recupera hasta un 97% del daño en solo 35 minutos.
Descubre LC-QAT, un método innovador que logra cuantización de 2 bits para LLMs con solo 0.1% de datos, superando a otras técnicas. ¡Optimiza tus modelos!

Descubre PiSO, un algoritmo que calcula escalas óptimas de cuantización para LLMs. Mejora perplejidad y precisión en tus modelos.

Optimiza la generación de imágenes por IA con enrutamiento consciente del coste. Equilibra calidad y recursos en modelos de difusión. ¡Descubre cómo!

GRAU: unidad de activación reconfigurable que reduce costos de hardware hasta un 90% en aceleradores de redes neuronales, soportando cuantización mixta y funciones no lineales.

Descubre SinkRec: modelo que mitiga el hundimiento semántico en recomendaciones de secuencias largas con memoria condicionada y redes delta. Eficiente.

Descubre cómo optimizar cuantizadores minimizando el error cuadrático medio y controlando la distribución de salida para comunicación y anonimización.

SpectrumKV optimiza la transferencia de caché KV con precisión mixta por token, reduciendo el TTFT hasta un 62%. ¡Mejora el rendimiento de tus LLM!