
Compresión de LLM: poda estructural y cuantización mixta
Descubre cómo optimizar poda estructural y cuantización mixta para reducir hasta 85% la perplejidad en LLM con bits ultrabajos. Mejora eficiencia.
Descubre cómo optimizar poda estructural y cuantización mixta para reducir hasta 85% la perplejidad en LLM con bits ultrabajos. Mejora eficiencia.
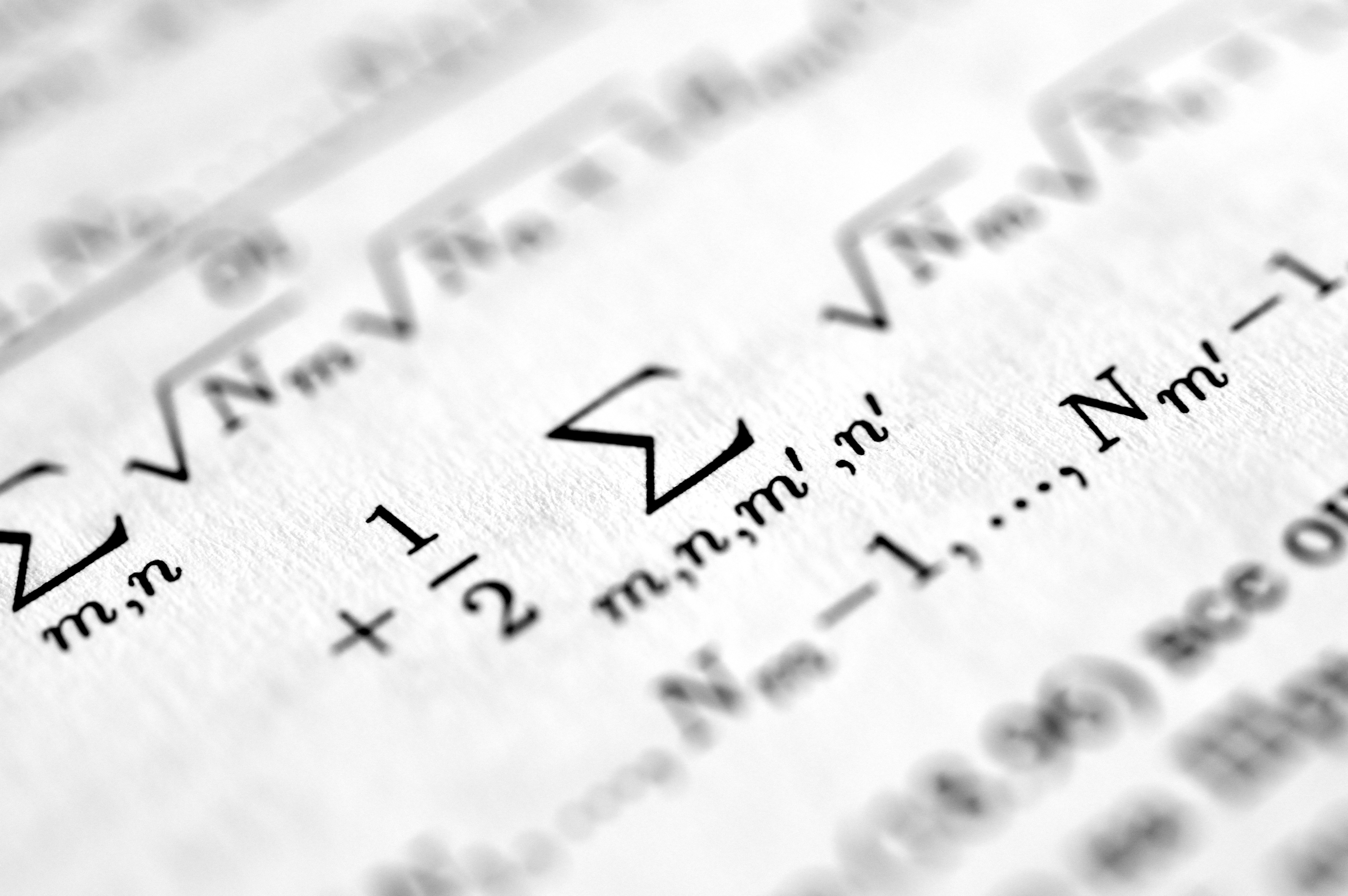
Optimiza tus modelos de lenguaje con CMPQ: cuantización de precisión mixta por canal que ahorra memoria y mejora el rendimiento en dispositivos edge.