
Estimación de incertidumbre con distribuciones de varianza controlada
Nueva técnica para cuantificar la incertidumbre en redes neuronales usando la varianza de las predicciones. Ideal para aplicaciones críticas.
Nueva técnica para cuantificar la incertidumbre en redes neuronales usando la varianza de las predicciones. Ideal para aplicaciones críticas.

Descubre ParDef, una defensa generalizada que protege redes profundas contra ataques a parámetros dispersos, continuos y estructurados sin perder rendimiento.

¿Modelos incorrectos en inferencia basada en simulación? FMCPE usa flow matching para corregir estimaciones con datos de calibración. Mejora tu precisión.

Descubre EmaQ y EmaQ-LT: cuantificación precisa para redes neuronales con dominios múltiples y desbalance, mejorando la eficiencia en dispositivos limitados.
STaR-Quant mejora la cuantificación de baja precisión en DLLMs, logrando 1.69x aceleración y 3.14x ahorro de memoria sobre FP16. Descubre cómo optimizar tu modelo.

MC-GLM cuantifica incertidumbre post hoc a nivel de instancia en detección de objetos para conducción autónoma. Sin reentrenamiento, eficiente y paralelizable.

Los Flow Learners alinean dinámica continua con IA para transformar la simulación de PDEs y cuantificar incertidumbre.

Aprende cómo la autoevaluación por clusters permite a los LLMs medir su incertidumbre con solo dos muestras, mejorando la confiabilidad de sus respuestas.
Descubre cómo ReaLM usa cuantificación residual para alinear embeddings de grafos de conocimiento con LLMs, logrando rendimiento estado del arte.
Aprende cómo SeSE cuantifica la incertidumbre en LLMs usando teoría estructural para evitar alucinaciones. Mejora la fiabilidad de tus modelos.

Descubre Qift: un método de cuantificación sin cero para pesos de 2 bits que mejora la precisión y eficiencia en inferencia de LLM rotados. Simple y sin entrenamiento.

Reduce errores en razonamiento con KVarN. Cuantificación KV de 2 bits que optimiza la memoria y mejora el rendimiento en modelos de lenguaje.

Descubre OASIS, la arquitectura LUT que acelera la inferencia de LLM un 3x con cuantificación dual, reduciendo la pérdida de precisión a solo 1.98%.

Mejora la predicción de clima extremo con NTK-UQ: intervalos 31-37% más precisos, adaptativos y sin reentrenamiento.

Descubre SVE: incertidumbre calibrada en modelos fundacionales con solo 1% de parámetros extra.
Evaluamos 13 métodos de cuantificación de incertidumbre en clasificación de radiografías de tórax, desenredando incertidumbres epistémicas y aleatorias.

Descubre cómo HUVR+SIREN logra mayor fidelidad en terrenos de alta resolución sin almacenamiento extra. Benchmark revela claves.
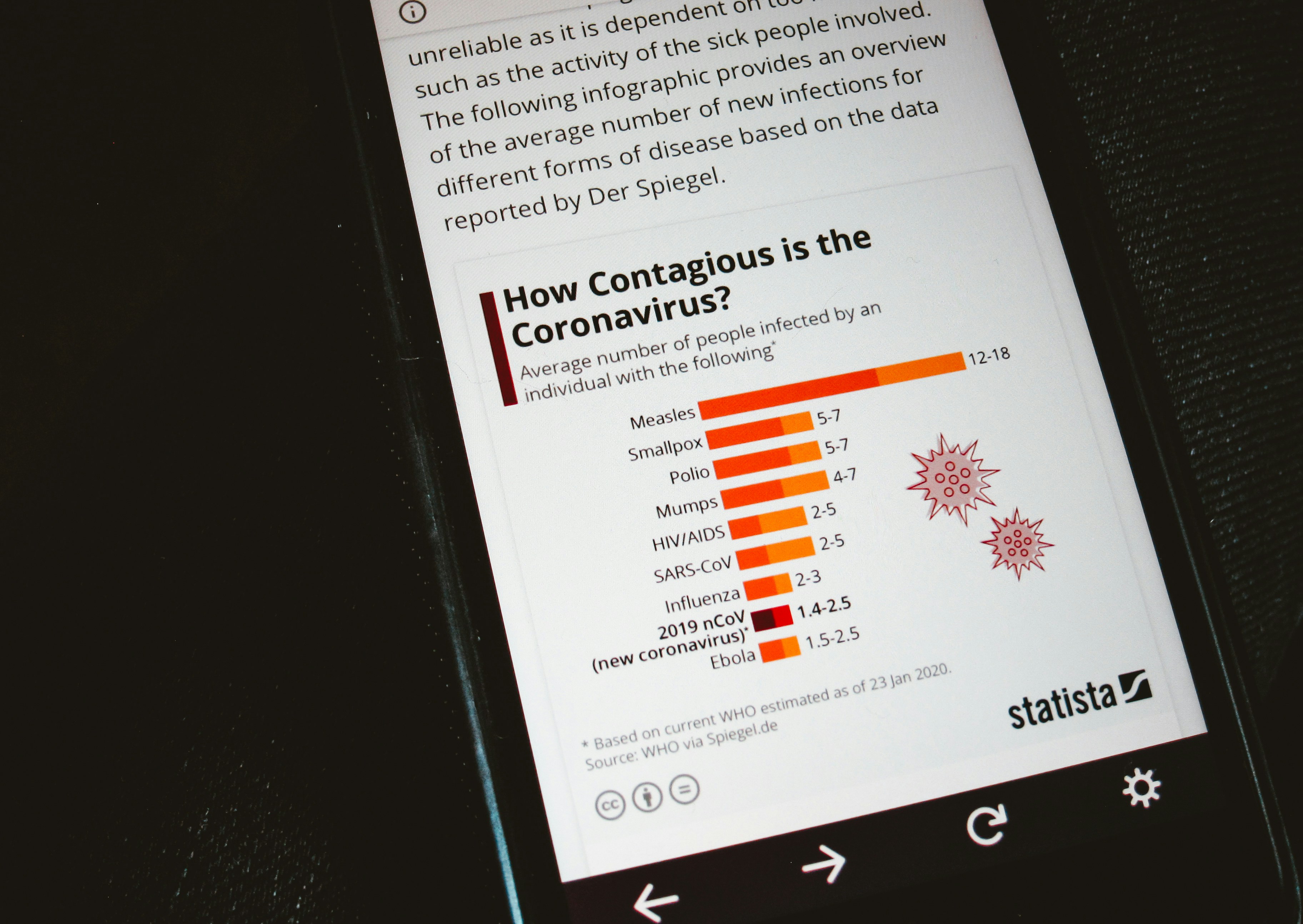
Nuevo método de predicción conformal online sin parámetros para cobertura justa por grupos en entornos cambiantes. ¡Mejora la fiabilidad de tus modelos!

Descubre cómo TabPFN y los Procesos Gaussianos cuantifican la incertidumbre en regresión. Resultados clave para datos escasos y complejos.

Descubre cómo cuantificar la incertidumbre en efectos causales usando procesos gaussianos. Método con momentos posteriores cerrados y calibración práctica.