Aceleración optimización bayesiana multiobjetivo vía gradientes predictivos
Acelera la optimización bayesiana multiobjetivo con gradientes predictivos. Descubre cómo lograr convergencia más rápida al conjunto de Pareto.
Acelera la optimización bayesiana multiobjetivo con gradientes predictivos. Descubre cómo lograr convergencia más rápida al conjunto de Pareto.

Descubre MG-ADSGD, algoritmo que acelera la optimización descentralizada con SGD, mejorando comunicación y convergencia para problemas fuertemente convexos.

MG-ADSGD acelera la optimización descentralizada con comunicación eficiente, logrando la mejor complejidad comunicacional para problemas fuertemente convexos.

El estimador M de Tyler presenta una transición de fase abrupta en DS-SNR=1. Descubre su comportamiento crítico para la recuperación robusta de subespacios.

Descubre cómo la reparametrización relativa optimiza la convergencia en modelos singulares como GMM y redes neuronales. Teoría y experimentos.
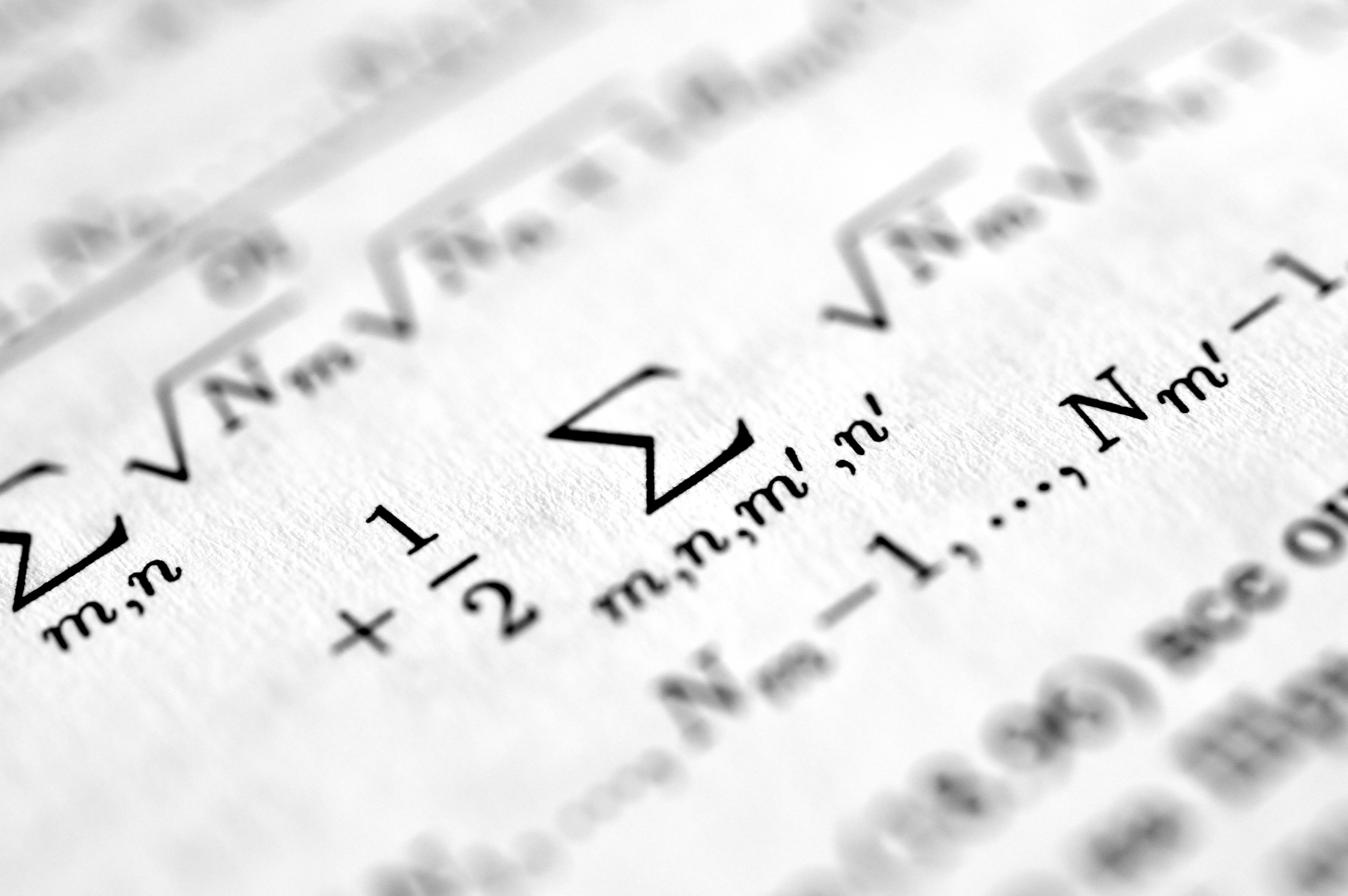
Descubre cómo AdaGrad, RMSProp y Adam se modelan con ecuaciones integro-diferenciales. Un nuevo enfoque teórico para optimizadores adaptativos.

LoRA-DA mejora la precisión y estabilidad del fine-tuning con inicialización consciente de datos. Descubre cómo el análisis asintótico optimiza la adaptación de bajo rango.

Descubre por qué los LLM generan programas repetitivos: un estudio revela que el 87% de las mutaciones vuelven a formas previas. ¿Cómo evitarlo?

HyperLoRA elimina sesgos de agregación y retrasos en inicialización, logrando convergencia más rápida y personalización robusta en modelos fundacionales.

Descubre cómo TD(0) con aproximación lineal logra una convergencia rápida y robusta, con tasa óptima de 1/k y sin depender del menor autovalor. Ideal para aprendizaje por refuerzo.
Blade: inversión bayesiana sin derivadas con priors de difusión. Partículas interactuantes para posteriores precisos y calibrados en dinámica de fluidos.
Análisis de la convergencia del gradient boosting multicalibrado: garantías computacionales y experimentos en datos reales. Léelo ahora.

Descubre cómo escapar eficientemente de puntos de silla en funciones no convexas con suavidad generalizada. Nuevos resultados de convergencia para métodos de primer orden.

Descubre cómo mejorar el rendimiento promedio de algoritmos de optimización manteniendo garantías de convergencia lineal. Aplicaciones en IA y control predictivo.
El descriptor F-Transform de dos canales caracteriza trayectorias tempranas en correlación iterada con alta precisión y baja dimensionalidad.
Nuevo estimador consistente para el parámetro subgaussiano. Tasas de convergencia óptimas y aplicación en enriquecimiento GO. ¡Mejora tus pruebas de permutación!

Aprende cómo las redes neuronales con activaciones suaves mitigan la maldición de la dimensionalidad, garantizando convergencia uniforme y robustez en regresión. ¡Entra!

El nuevo algoritmo RT-PG reutiliza trayectorias off-policy para acelerar la convergencia en métodos de gradientes de política, mejorando la eficiencia muestral.

El algoritmo MNEM elimina el sesgo en mezclas gaussianas con datos heterogéneos y etiquetado parcial. Ideal para aprendizaje federado descentralizado.
Descubre cómo un nuevo framework de codificador/decodificador preserva la geometría de los datos, acelerando la convergencia en modelos generativos latentes.