
Q-Delta: Más allá de la evolución asociativa clave-valor
Descubre Q-Delta, regla delta que integra errores de predicción clave-consulta en evolución de estado, mejorando eficiencia y precisión en atención lineal.
Descubre Q-Delta, regla delta que integra errores de predicción clave-consulta en evolución de estado, mejorando eficiencia y precisión en atención lineal.
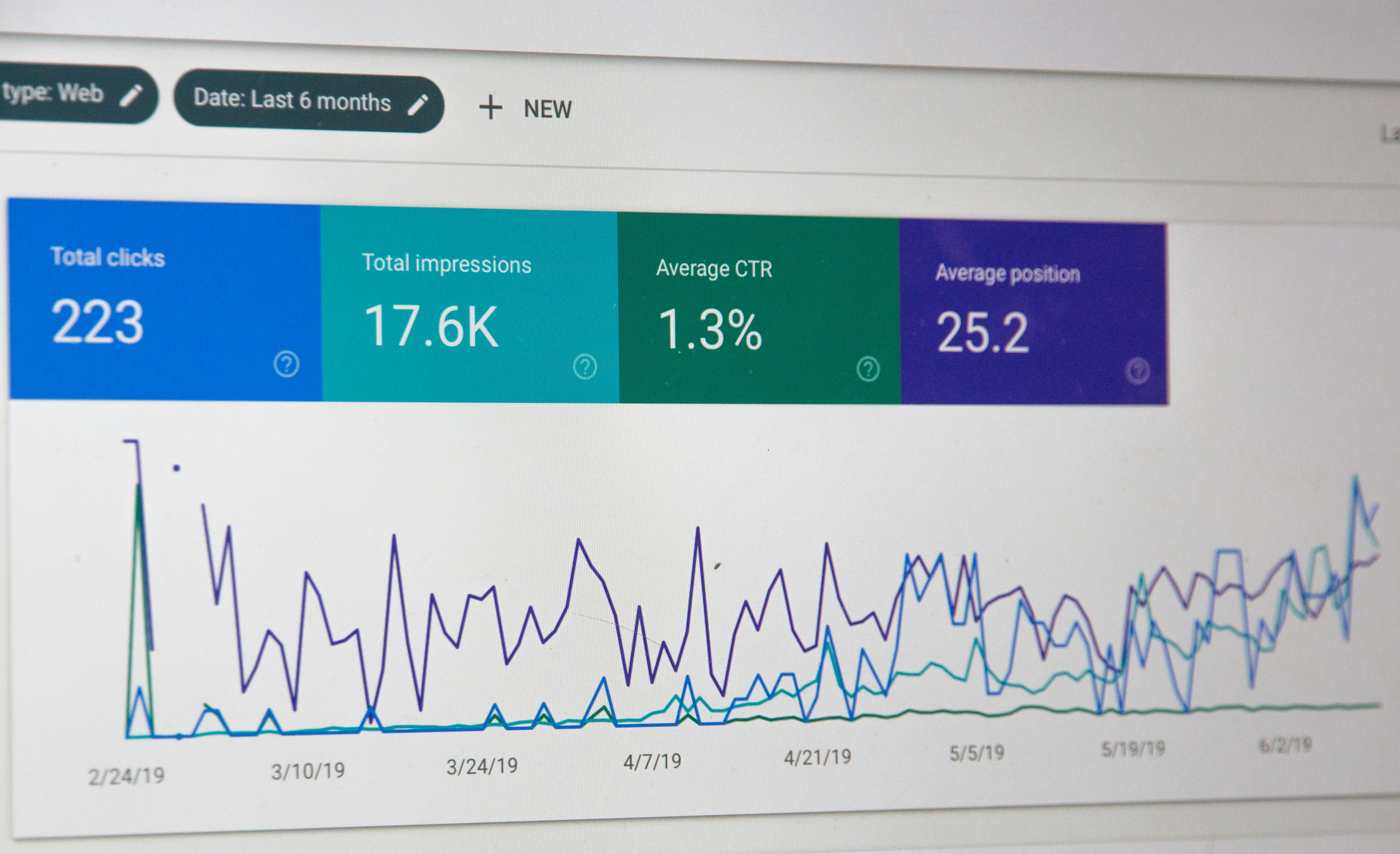
Revoluciona tu marketing con Rider Graph de Lyft: audiencias reales, anuncios precisos. Aumenta la eficiencia de tu inversión.

GLM-5.2 de Z.ai supera a GPT-5.5 en programación a largo plazo con 1/6 del costo. Arquitectura IndexShare y licencia MIT.

Adjunta hasta 1 GB de metadatos por objeto con S3 Annotations. Consulta en Athena y optimiza flujos de IA. ¡Empieza hoy!

¿Cansado de hacer stash y cambiar de rama? Los git worktrees te permiten trabajar en paralelo sin perder el foco. Descubre cómo.
Descubre cómo un oráculo de atención reduce el coste de prefill en modelos híbridos de contexto largo, manteniendo calidad y acelerando inferencia hasta 1.93x.

FlashMemory-DeepSeek-V4 comprime el caché KV al 13.5% usando Atención Dispersa Anticipada. Mejora tu inferencia de LLMs sin sacrificar precisión. ¡Conoce más!
El 'context rot' hace obsoletos los archivos de configuración de IA. Descubre cómo herramientas de documentación tradicionales pueden detectarlo.

GraphQL y MCP: arquitectura semántica para agentes IA, protege microservicios y reduce costos de tokens consultando solo el contexto exacto.

Exploramos el debate entre entusiastas y escépticos de la IA en programación, la importancia del contexto y la lucha por la descentralización.

Descubre cómo la programación agentica con LLM-as-Code resuelve la explosión de tokens y alucinaciones de control, mejorando la fiabilidad de agentes de IA.

MMLongEmbed: el primer benchmark para evaluar modelos de embeddings multimodales en escenarios de contexto largo. Descubre sus hallazgos clave.

EnvShip-Bench ofrece un benchmark unificado con datos AIS y contexto ambiental para predecir trayectorias de buques. ¡Mejora la seguridad marítima!
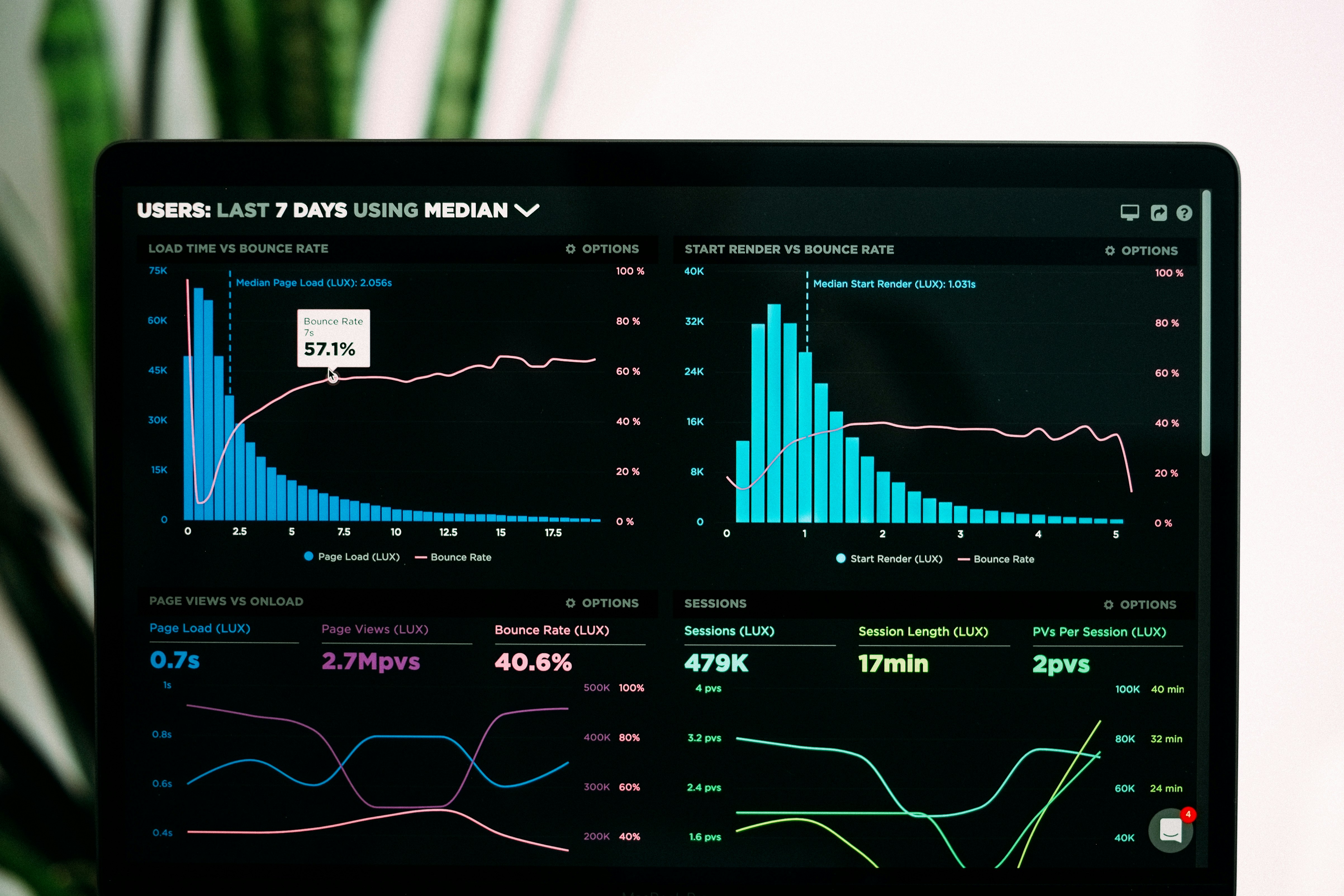
M-CTX acelera 226x la construcción de contexto espacial para análisis de trayectorias, reduciendo de 17 días a 1.8 horas. Exacto y escalable.

Descubre cómo mezclas de subespacios comprimen la comunicación un 95% para entrenar modelos de lenguaje con contextos de 100K tokens, incluso en redes lentas.

Zero Trust no basta para la IA agente. Descubre los nuevos vectores de ataque y cómo extender la seguridad a acciones, contexto y razonamiento.

Descubre por qué la capa de memoria IA será clave para SaaS en 5 años: mejora productividad, personalización y retención. Prepárate para el futuro.

Descubre por qué la capa de memoria IA será esencial para las empresas SaaS en los próximos 5 años. Mejora productividad, personalización y retención. ¡No te

La clave del futuro de la IA no son modelos más inteligentes, sino una mejor coordinación. Conoce Contorium: infraestructura para sistemas que colaboran.

Descubre cómo los LLMs generan verdad fundamental sintética para clasificar emociones en audio VR. Supera limitaciones de etiquetado manual. ¡Descúbrelo!