
Interpretación y control de un modelo TTS con autoencoders dispersos
Aprende cómo los autoencoders dispersos permiten interpretar y controlar un modelo de texto a voz: desde risas hasta género y velocidad.
Aprende cómo los autoencoders dispersos permiten interpretar y controlar un modelo de texto a voz: desde risas hasta género y velocidad.
Descubre cómo VFUSE utiliza autoencoders dispersos para detectar características virulentas en modelos de proteínas, mejorando la seguridad en el diseño.

Descubre cómo las Representaciones Reducidas Holográficas (HRR) revolucionan el desenredo de factores en redes neuronales. Resultados competitivos y robustez al ruido.
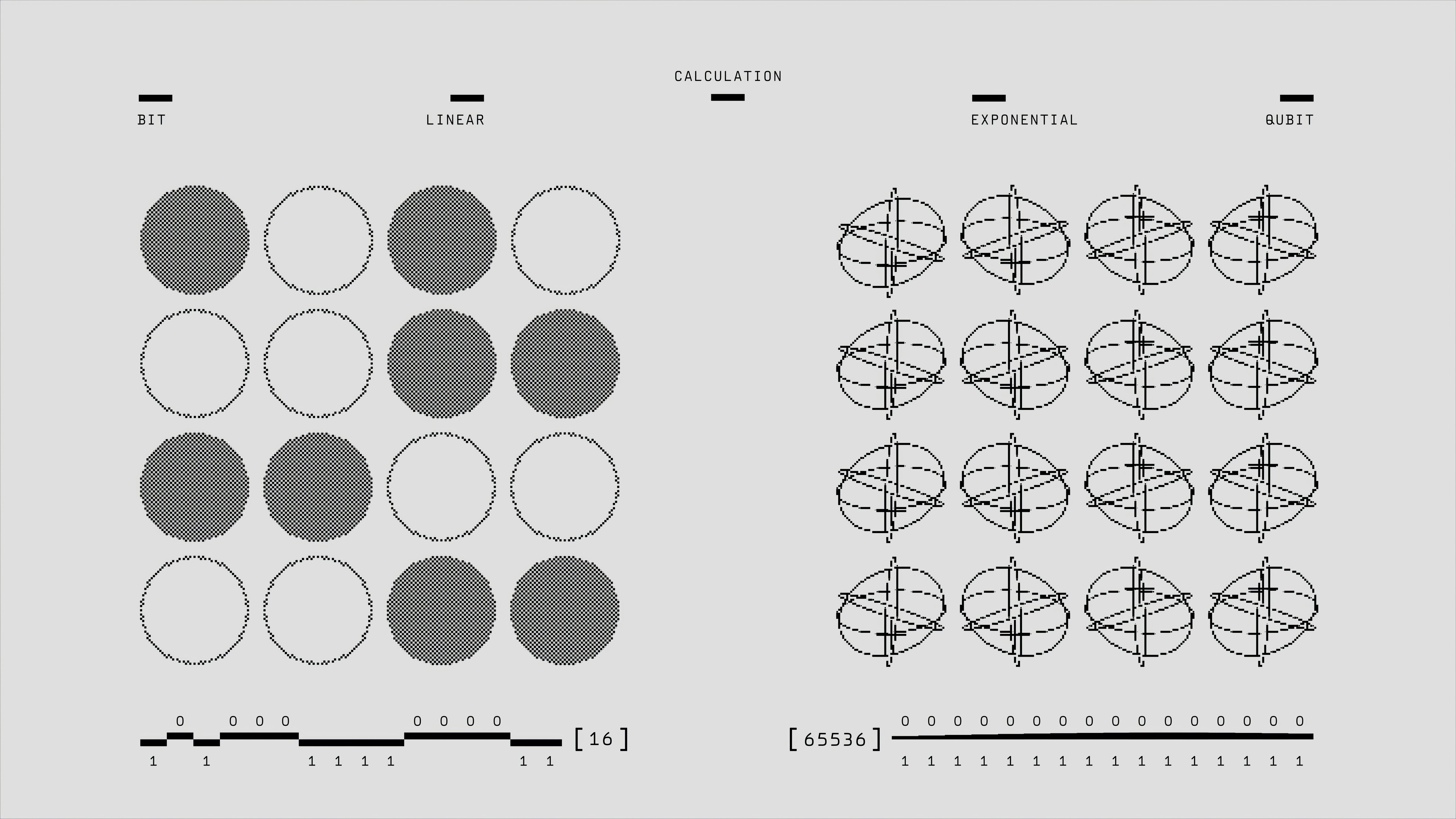
SAEExplainer optimiza la interpretación de características SAE usando preferencias guiadas por activación, reduciendo alucinaciones y mejorando causalidad.

Descubre cómo los autoencoders variacionales revelan la estructura de campo medio en sistemas complejos, físicos y neuronales. IA interpretable.
Transformer ligero estima transmisión y radiancia atmosférica en imágenes hiperespectrales LWIR, mejorando la compensación sin supervisión de ubicación.

Aprende a predecir los efectos secundarios del steering con autoencoders dispersos. Un estudio en GPT-2, Pythia, Gemma y Llama para optimizar tu intervención.

Descubre XAInomaly, un autoencoder contractivo explicable para detectar anomalías en tráfico O-RAN. Mejora la gestión con IA explicable.

Descubre Query Lens, un nuevo método que va más allá de Logit Lens para interpretar características de autoencoders dispersos, considerando efectos indirectos y la hipótesis del subespacio.

Descubre AE-YOLO, un nuevo modelo que combinando autoencoder y atención detecta defectos en aisladores con drones, logrando un mAP del 95.1%.

Mejora el rendimiento de transformers profundos con WAV v1: routing residual multirresolución que reduce pérdida en 48 capas.

Descubre cómo ViSAE usa circuitos de concepto inspirados en neurociencia para interpretar y guiar Vision Transformers, mejorando precisión y confianza.

El tamaño del cluster y el condicionamiento del hablante son clave para evitar mezcla de hablantes en vocoders multilingües. Descubre cómo.

Los modelos de lenguaje pueden resistir manipulaciones internas. Descubre cómo funciona la resistencia endógena y sus implicaciones para la seguridad.

Aprende a construir espacios latentes de VAE con topología prescrita, resolviendo el desajuste topológico y mejorando la calidad de reconstrucción en datos no euclidianos. Resultados superiores.

Descubre cómo el análisis de campo medio explica el entrenamiento de autoencoders no lineales con cuello de botella y su convergencia al óptimo.

Descubre cómo un autoencoder CNN separa mezclas espectrales en imágenes ATR-μFTIR de pinturas históricas, mejorando la interpretación sin supervisión.

Descubre cómo un marco neuronal separa información compartida y específica de múltiples sensores, permitiendo generación dirigida e inferencia cruzada. Ideal para IA y cloud.

Explora cómo la geometría revela el aprendizaje de conceptos en autoencoders dispersos y permite interpretar neuronas de forma clara.

Descubre cómo los modelos de difusión generalizan con representaciones equilibradas. Detecta memorización y edita sin entrenamiento.