
Minería de trayectorias para automatizar SKILL.md en agentes informáticos
Minería de trayectorias de interacción genera bibliotecas de habilidades legibles para agentes informáticos, aunque no mejora significativamente las políticas
Minería de trayectorias de interacción genera bibliotecas de habilidades legibles para agentes informáticos, aunque no mejora significativamente las políticas

Descubre cómo la dinámica de atención en Transformers profundos se modela con ecuaciones Vlasov, revelando clustering y evolución de tokens.
EQPO reduce la variabilidad en precisión entre grupos demográficos en diagnóstico clínico, incluso sin etiquetas demográficas, mediante aprendizaje equitativo.

Descubre cómo la percolación crítica genera datos sintéticos jerárquicos y fractales para evaluar la interpretabilidad de redes neuronales. Modelo analítico y
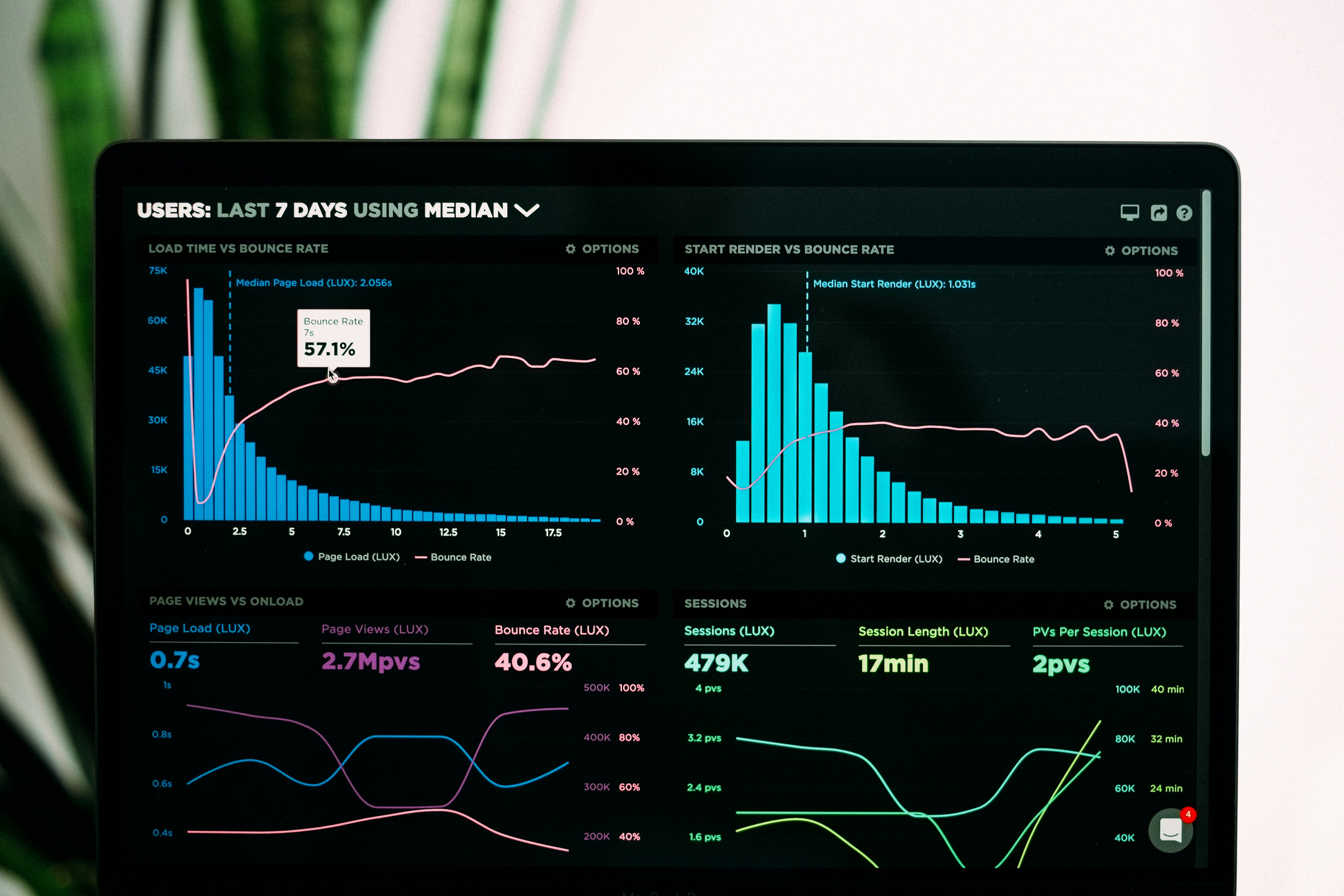
Descubre cómo aplicar el Consenso Monte Carlo Variacional en modelos de mezcla bayesianos para aprendizaje federado con datos de salud. Optimiza privacidad y

Descubre ProfiLLM: perfiles de usuario con IA optimizan el despacho de viajes, logrando +6.14% en AUC y +4.35% en GMV.

Marco CEFR y Fuzzy C-Means automatiza evaluación Scratch, detecta cuello de botella B2 y guía rutas de aprendizaje.

Descubre cómo el algoritmo Perception permite clustering robusto con solo 10-30 semillas por clúster, sin ajuste de parámetros. Basado en detección de
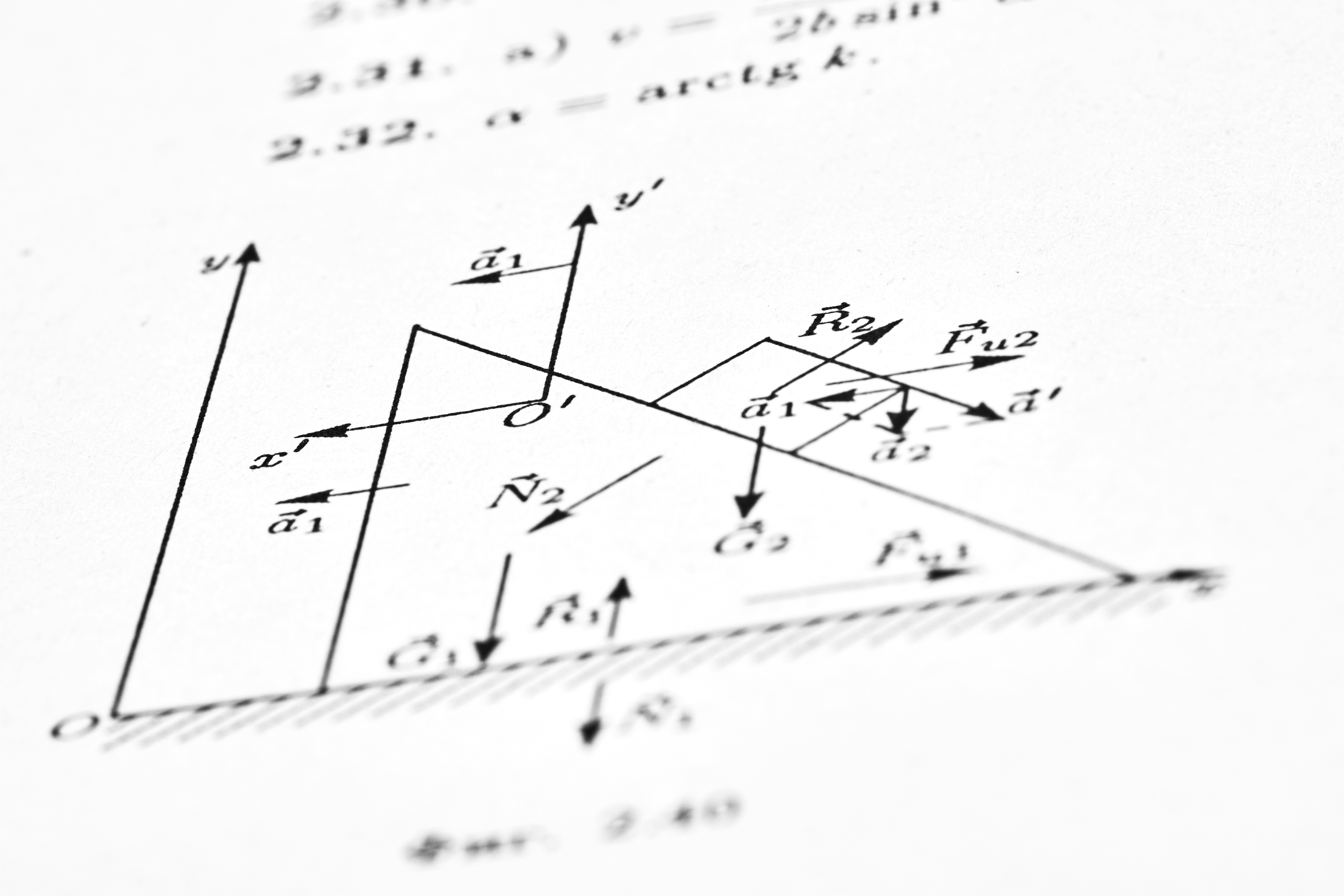
Descubre CAHP: poda de cabezas de atención basada en teoría de grafos que reduce parámetros sin ajuste manual, mejorando la eficiencia de los transformers.

Descubre SCAN, un método avanzado que combina clustering multiescala para detectar anomalías en series temporales, superando limitaciones de modelos basados en

Descubre cómo la similitud estructural en grafos no siempre predice el rendimiento de algoritmos de caminos más cortos. Un estudio con Dijkstra, A* y más.
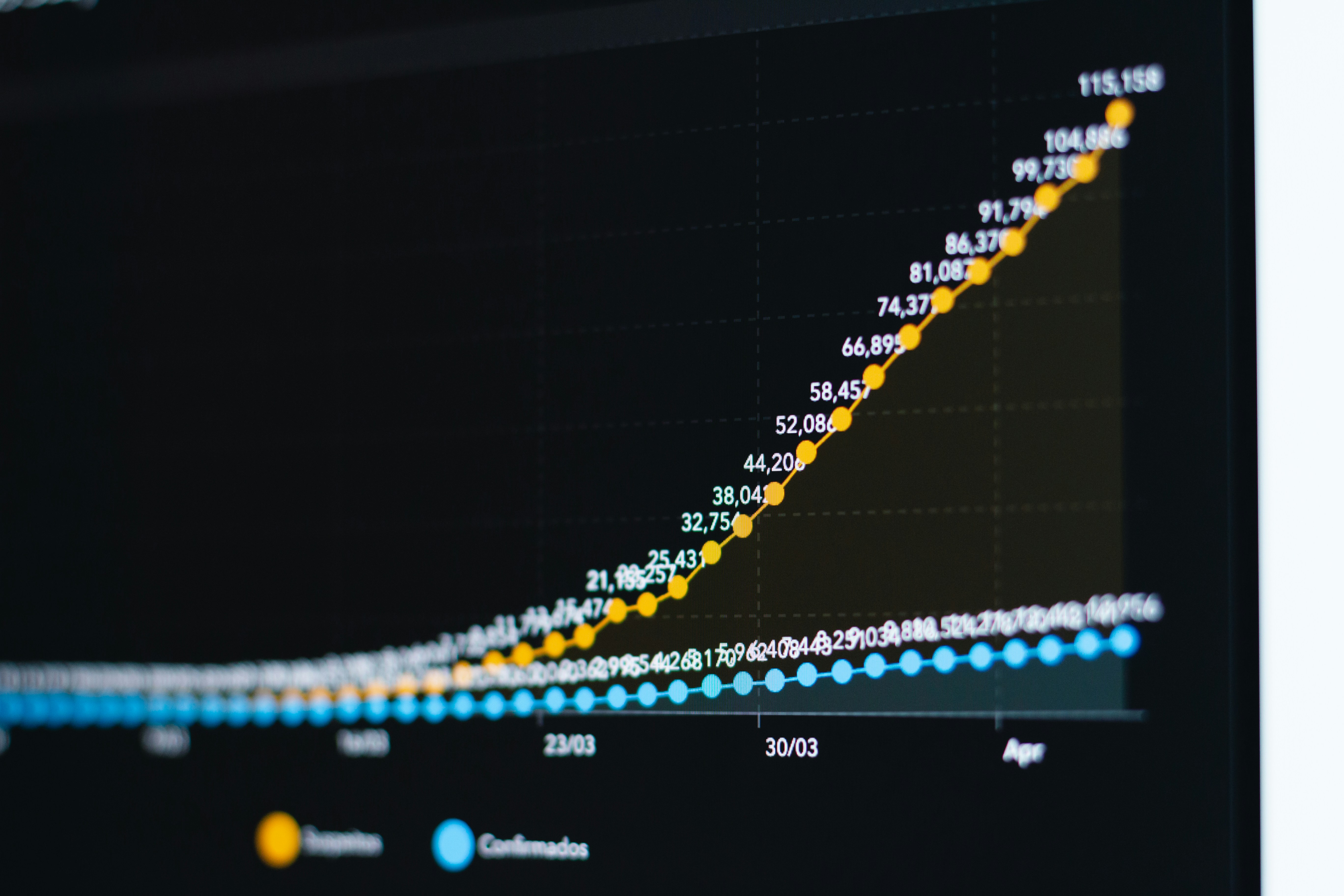
¿La similitud estructural de los grafos garantiza el rendimiento de Dijkstra, A* y otros? Este análisis de paisajes de instancias revela sorpresas.

FOSC-X extrae las mejores M soluciones de clustering globalmente óptimas desde jerarquías, incluso con límite de clústeres. Alternativas de alta calidad.
scGTN: nueva red siamesa transformer de grafos para clustering de scRNA-seq. Integra expresión génica y dependencias estructurales superando a métodos
Descubre cómo el clustering y el pruning reducen la complejidad en la fusión de datos causales, facilitando la identificación de efectos incluso con variables

Descubre cómo un nuevo método de clustering sin etiquetas cuantifica las interacciones sociales entre peatones, mejorando la predicción de trayectorias para
Descubre MGIL: aprendizaje inductivo global para completar grafos de conocimiento con predicción de enlaces de vanguardia.

Descubre cómo UL4M4 imputa modalidades faltantes en aprendizaje multimodal usando clustering no supervisado, logrando F1 >0.7 incluso con más del 50% de datos
Descubre cómo UL4M4 imputa embeddings faltantes en aprendizaje multimodal mediante clustering no supervisado, logrando F1 >0.7 incluso con >50% de datos
Descubre cómo la selección de datos basada en bajo rango supera al clustering tradicional. Nuevo método con garantías teóricas y mejor rendimiento en datasets