
Aprendizaje en todas partes: IA con restricciones puntuales
Descubre el aprendizaje en todas partes: IA con restricciones puntuales mejora generalización mediante dualidad.
Descubre el aprendizaje en todas partes: IA con restricciones puntuales mejora generalización mediante dualidad.

Analizamos cómo la codificación de etiquetas (one-hot) afecta el colapso neuronal en redes, con foco en el sesgo del clasificador y la pérdida MSE.

CSLR logra entre 3.9 y 5.6 puntos de mejora en aprendizaje continuo federado con privacidad diferencial. Optimiza NLP sin compartir datos.

Nuevo método SAMN elimina hiperparámetros en reescalado adaptativo monótono para colas largas. Resultados SOTA en benchmarks.

Descubre cómo un clasificador basado en LLMs optimiza la escucha activa en triaje legal, mejorando la precisión con preguntas de seguimiento generadas por IA.
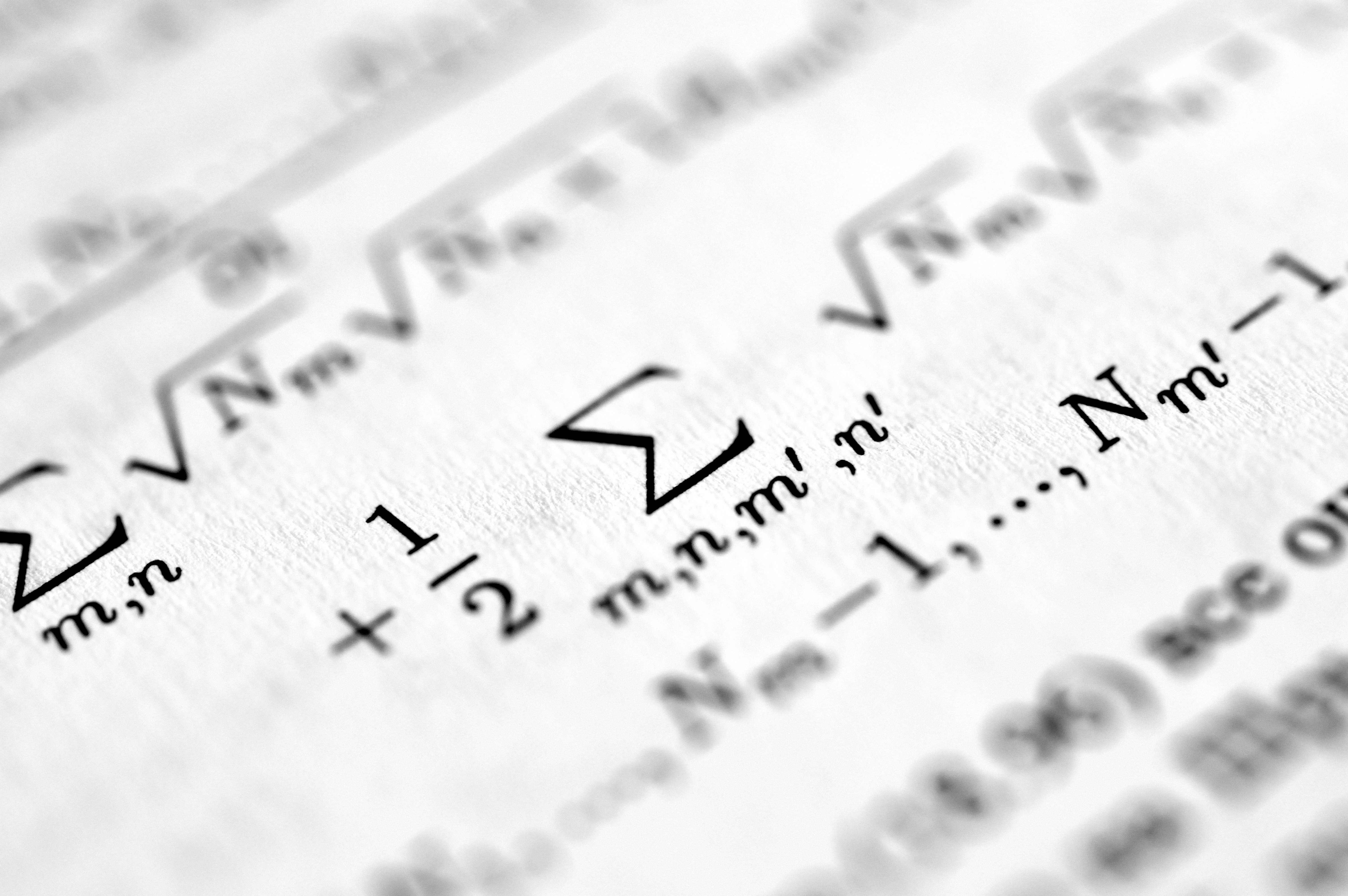
KACE: un novedoso método que separa almacenamiento y uso del conocimiento, logrando un 62.2% de precisión en AIME 2025. Ideal para mejorar razonamiento matemático en IA.

Descubre GCAN, modelo de atención contrafactual para diagnóstico explicable del deterioro cognitivo usando conectomas multimodales. Preciso y transparente.
CLSP-REQA integra evaluación de calidad EEG en tiempo real para predecir convulsiones con alta precisión, superando métodos previos sin adaptación de dominio. ¡Aprende cómo!

Descubre cómo Belief2-Attention mejora la atención en visión usando dos componentes para clasificación y segmentación.

Descubre Planktonzilla-17M, el dataset más grande de imágenes de plancton. Mejora la clasificación de especies con IA y supera a modelos base como BioCLIP.

DAStatFormer, transformador híbrido, logra 99.4% de precisión en clasificación DAS con menos parámetros. Ideal para monitoreo.

Descubre los modelos Hoeffding de cuello de botella conceptual: explicabilidad no lineal y robusta para imágenes aéreas.

LLMs y EEG comparten un eje de valencia. La saturación limita la supervisión. Descubre cómo un ensamble mejoró un 10.5% la precisión en FACED.

¿Puede una IA optimizada como ChurnNet superar a los métodos clásicos de machine learning? Descubre los resultados en nuestra comparativa.

Nuevo método de clasificación guiada por puntuación detecta depresión con EEG sin aumentación de datos, mejorando precisión.

Con HASTE, el entrenamiento disperso dinámico consciente del hardware logra hasta 25x de aceleración en backpropagation para clasificación multi-etiqueta extrema.

Descubre cómo los modelos multimodales superan a los LLM en clasificación de documentos visuales. La información visual es clave. Resultados RVL-CDIP.

Descubre CEAR: mejora la robustez adversarial certificada en DNNs usando ensambles con ruido y votación. Superior en MNIST, CIFAR10 y TinyImageNet.

UR-JEPA logra un 0.83% más de precisión que LeJEPA en Inet10 con menor varianza, y produce representaciones geométricamente distintas.

GJDNet mejora la robustez de GNNs frente a ataques con representaciones y decisiones disentangled. Aísla perturbaciones y estabiliza fronteras de decisión en grafos diversos.