
Actúa como un investigador real: benchmarks para LLMs y agentes
Descubre AARRI-Bench, el benchmark que mide si los agentes de IA pueden pensar como investigadores humanos. El mejor modelo solo alcanza un 68.3% de éxito.
Descubre AARRI-Bench, el benchmark que mide si los agentes de IA pueden pensar como investigadores humanos. El mejor modelo solo alcanza un 68.3% de éxito.

Descubre cómo la arquitectura afecta la transferencia en redes implícitas. Estudio comparativo de SIREN, ReLU y Fourier para modelos científicos.

Descubre cómo la insuficiencia explicativa impulsa la creación de nuevas representaciones en IA, desde modelos del mundo hasta gemelos digitales. Una teoría que transforma el aprendizaje.
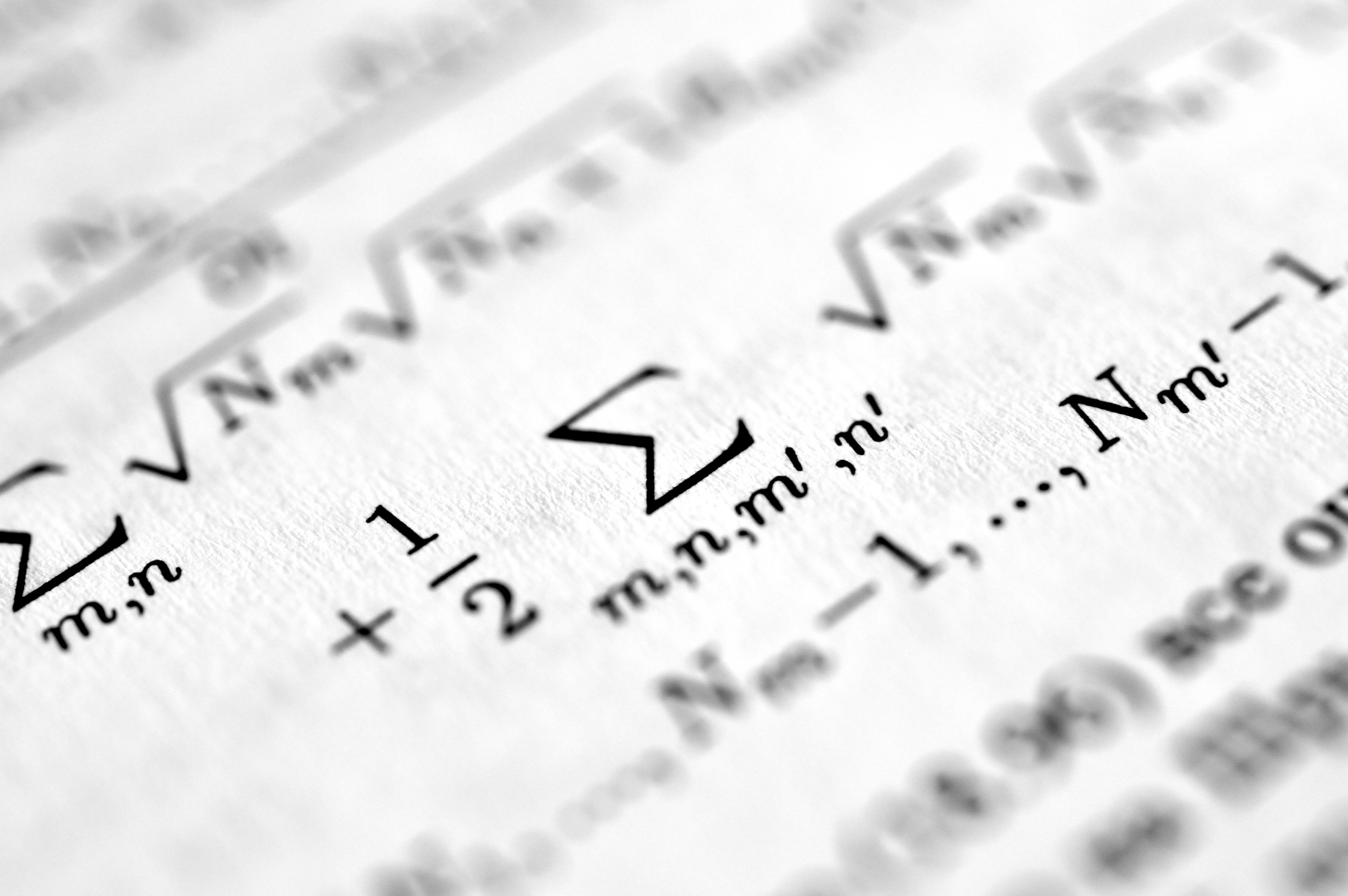
Descubre cómo Deflex, basado en cálculo lambda neuronal, extrae automáticamente fórmulas multiescala en sistemas complejos, superando a métodos tradicionales.

Deflex extrae automáticamente fórmulas multiescala en sistemas complejos con IA y cálculo lambda. Hasta 7 veces más eficiente.

Descubre cómo PaperFlow recomienda artículos científicos adaptándose a tus intereses cambiantes y flujo diario. Benchmark con 24 usuarios simulados y evaluación humana.

Descubre cómo un científico de IA curioso explora universos Flow-Lenia revelando dinámicas de ecosistemas autoorganizados. Un nuevo enfoque para sistemas complejos.

Nuevo enfoque de compresión aprendida con corrección residual reduce la tasa hasta un 60% y supera a SZ en alta fidelidad. ¡Descúbrelo!
Descubre cómo el modelado de residuos mejora la compresión de datos científicos un 30-60%. LBRC y NGLR para alta fidelidad.

Aprende cómo MechSim permite a los LLMs razonar sobre simuladores, logrando explicaciones transparentes y decisiones más fiables en entornos críticos.

Descubre cómo Sci-PRM, un modelo de recompensa consciente de herramientas, mejora la verificación científica en biología, química y física.

Descubre DistIL: aprendizaje por refuerzo con retroalimentación rica para razonamiento, código y matemáticas. ¡Lee más!

Descubre cómo DistIL optimiza el aprendizaje por refuerzo usando retroalimentación rica (trazas, correcciones, autoevaluación) para mejorar en razonamiento, código y matemáticas.

Descubre cómo Deliberate Evolution usa razonamiento agentico y memoria reflexiva para regresión simbólica eficiente con solo 40% de muestras. ¡Más con menos!

Descubre cómo el intercambio parcial de parámetros en regresión simbólica optimiza expresiones y reduce la necesidad de datos.

TadA-Bench ofrece un millón de variantes de proteínas para que la IA descubra rondas futuras en evolución dirigida. Acelera la ingeniería de proteínas con agentes.

¿Modelos complejos o estructuras? En IA, prioriza la identificación de estructuras para descubrimiento científico. Entiende la subdeterminación.

Descubre cómo el benchmark REL evalúa el razonamiento relacional en LLMs, revelando sus limitaciones en tareas de alta aridad en ciencias.
Descubre cómo democratizar el análisis predictivo y apoyar a los científicos de datos ciudadanos para tomar decisiones basadas en datos.

Un modelo explicable predice avances científicos analizando redes de conceptos con precisión superior. Clave para estrategias de I+D basadas en datos abiertos.