
Poda de redes neuronales profundas mediante la distribución de Marchenko-Pastur
Poda de redes profundas con distribución Marchenko-Pastur: precisión mantenida con mínimo ajuste fino. Resultados en ImageNet con ViT y CNNs.
Poda de redes profundas con distribución Marchenko-Pastur: precisión mantenida con mínimo ajuste fino. Resultados en ImageNet con ViT y CNNs.

Descubre cómo la atención causal dispersa por bloques puede desconectar tokens adyacentes y cómo reparar los bordes con una solución eficiente.

Descubre cómo nuestro algoritmo adaptativo multifidelidad reduce hasta 30 veces los costos de generación de datos en química cuántica, mejorando la eficiencia del machine learning.

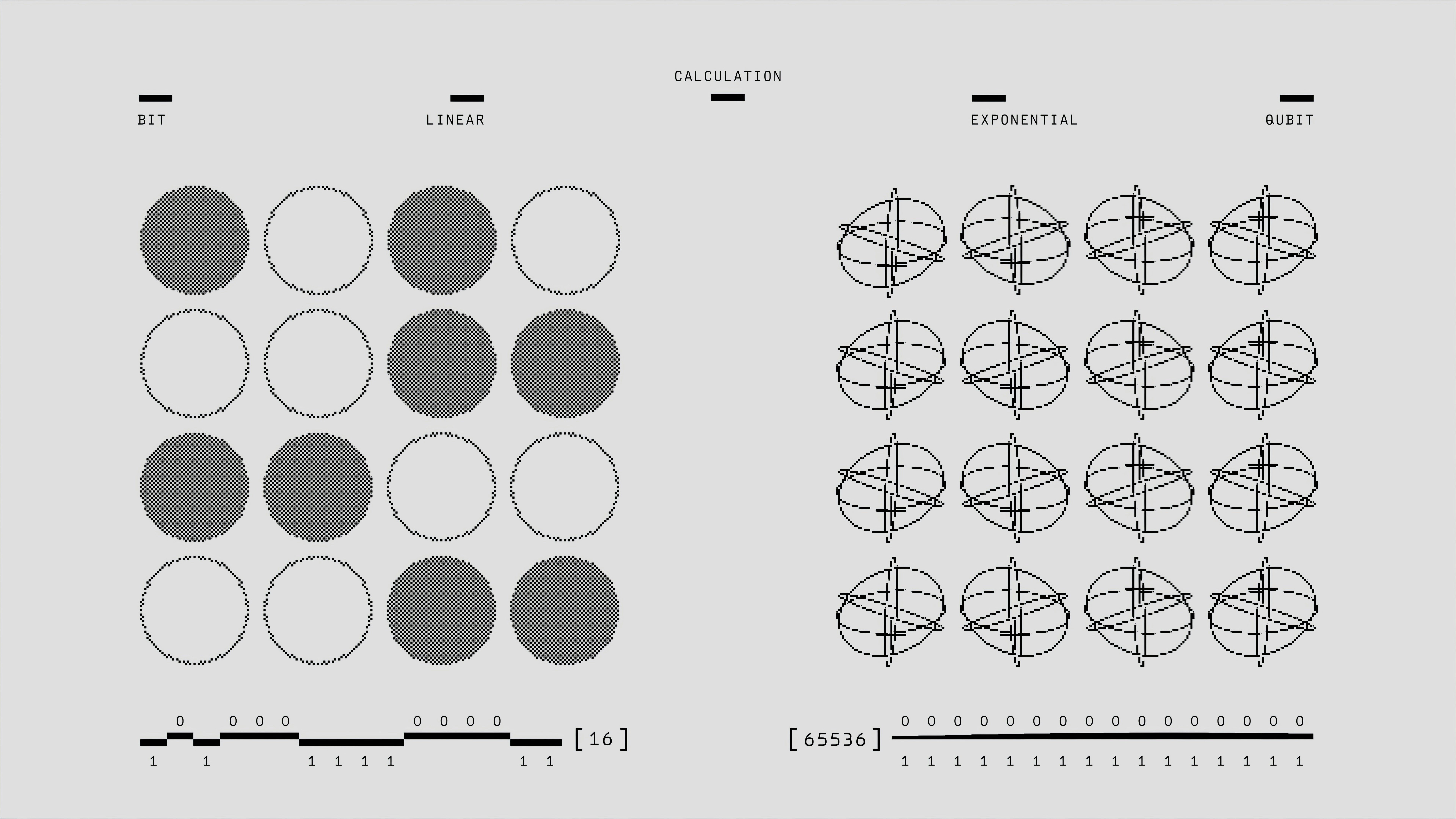
Descubre cómo JF-HPO optimiza hiperparámetros en RL para LLMs, logrando hasta 14.9x más eficiencia y mejoras de rendimiento del 5.8% al 111.6%.

SLAT: recorte adaptativo por segmentos reduce un 50% la longitud del razonamiento CoT sin perder precisión.

Descubre cómo la curvatura de grafos permite podar redes neuronales sin perder precisión. Técnica innovadora basada en Ollivier-Ricci para identificar conexiones clave.

Descubre cómo L2G-Net revoluciona las GNN espectrales con factorizaciones de Cauchy, escalando a grafos grandes con pocos parámetros.

Descubre MENO: el nuevo marco que mejora operadores neurales con MeanFlow para predicciones precisas en sistemas dinámicos, con hasta 14x más rapidez que DDIM.

Descubre IAPO: asigna ventajas a cada token según información mutua. Reduce razonamiento hasta 36% sin perder precisión. Optimiza tus modelos de lenguaje.

PECKER: método eficiente de desaprendizaje para modelos de difusión. Reduce el tiempo de entrenamiento y mejora el borrado selectivo de conocimiento.

Descubre MAVEN-T, un innovador marco de destilación reforzada que logra predicción de trayectorias multiagente en tiempo real con 6.2x menos parámetros y 3.7x más velocidad en Jetson Orin.
Descubre cómo el muestreo ponderado eficiente con modelos generativos de puntuación logra aceleraciones de 1.2x a 4.7x sin entrenamiento adicional, ideal para IA generativa.

MLPM, moderador ligero basado en prototipos latentes multicapa, mejora la seguridad de LLMs sin sacrificar eficiencia. Ideal para despliegues personalizados.

Descubre cómo el Subnetwork Data Parallelism reduce el uso de memoria en un 28-60% al entrenar modelos de IA, manteniendo el rendimiento. ¡Optimiza tu entrenamiento distribuido!

Descubre GPhyT, el primer modelo fundacional de física que aprende dinámicas complejas sin ecuaciones, superando a arquitecturas especializadas en múltiples dominios.

En TRMs, el razonamiento latente actúa como operador de mejora de política. Con RL y difusión, reducimos 18x los pasos.

C-GSPN: codificador de visión que iguala a ViT con 15% menos parámetros, mejora segmentación +2.1% y ofrece 4x de aceleración. ¡Conócelo!

Descubre SyNGLER, un marco eficiente para generar redes sintéticas realistas preservando esparcidad y grado de nodos. Bajo costo computacional.
Descubre un algoritmo práctico y óptimo para bandits contextuales lineales con O(log log T) actualizaciones. Máximo rendimiento con mínima complejidad.

Descubre cómo el muestreo directo de pares reduce costos computacionales en pérdida por pares, manteniendo precisión. Técnicas basadas en teoría de encuestas para IA escalable.