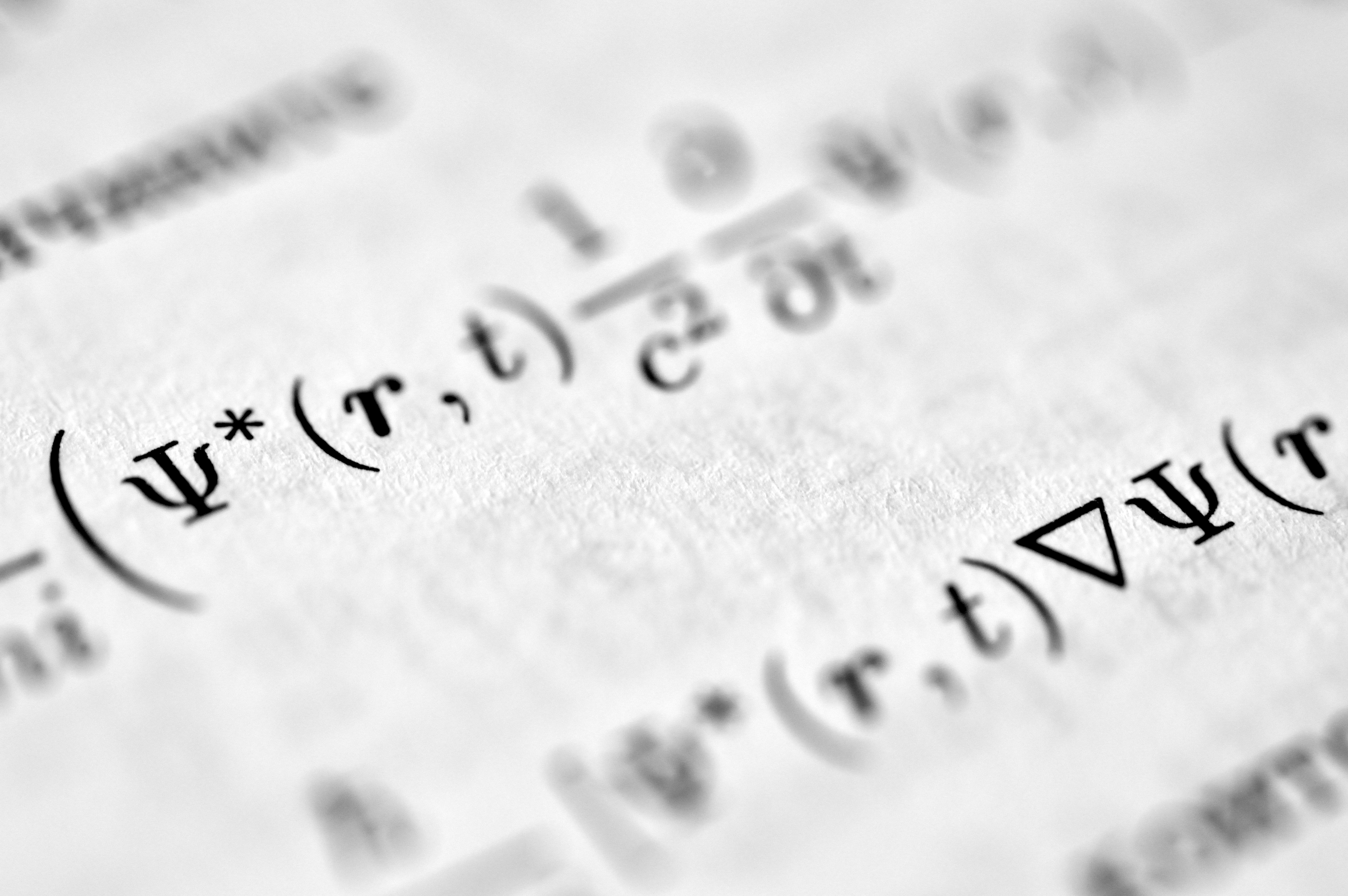
SeSE: Cuantificación de incertidumbre en LLMs basada en teoría estructural
Aprende cómo SeSE cuantifica la incertidumbre en LLMs usando teoría estructural para evitar alucinaciones. Mejora la fiabilidad de tus modelos.
Aprende cómo SeSE cuantifica la incertidumbre en LLMs usando teoría estructural para evitar alucinaciones. Mejora la fiabilidad de tus modelos.

Descubre cómo Phantom Transfer envenena datos y evade todas las defensas conocidas. Aprende por qué fallan las defensas actuales.

CNPC combina redes neuronales con circuitos causales para intervenciones precisas, mejorando la exactitud en modelos de caja de conceptos. ¡Resultados superiores!

BAHSD: marco de destilación adaptativa para recomendación en caja negra que logra hasta un 4.98% de mejora sobre el profesor y un 80%+ en usuarios de cola larga. Plug-and-play.
AdaE-SAEA: algoritmo evolutivo con ensambles adaptativos y RL para equilibrar robustez y precisión. Mejora rendimiento en problemas reales.

Descubre cómo intervenir en el razonamiento latente de los LLM para mejorar su precisión sin actualizar parámetros. Guía basada en interpretabilidad.

Descubre VERA, un framework de inferencia variacional que genera prompts adversariales para identificar vulnerabilidades en LLMs sin reoptimización.

Alinea LLMs de caja negra en inferencia usando optimización restringida y teoría de juegos para balancear seguridad y utilidad.
CryoProt revoluciona el análisis de proteínas con IA: modela interacciones entre cajas en mapas crio-EM para predicciones precisas. Mejora hasta un 12%.

Descubre cómo los monitores constitucionales de caja negra detectan engaños en agentes LLM usando datos sintéticos. Resultados sobre generalización y límites.

Descubre cómo el conjunto de datos defectuoso de la ética provoca fallos en la IA y por qué necesitamos un nuevo modelo axiomático aditivo.

DiscourseFlip: un ataque de manipulación de opinión a nivel de discurso en RAG que evade defensas actuales. Conoce sus implicaciones.

Descubre TN-SHAP-G: calcula valores Shapley en gráficos usando redes de tensores, sin Monte Carlo. Explicabilidad eficiente para modelos complejos.
Descubre cómo la identificación del mejor brazo (BAI) mejora la optimización bayesiana en funciones multimodales, acelerando la convergencia al óptimo global.

Descubre cómo los Acordes Geométricos Latentes (LGC) optimizan ataques adversarios con alta fidelidad visual y mínimas perturbaciones. SSIM > 0.99 y LPIPS < 0.01.

¿Es suficiente la similitud semántica para destilar LLMs? Evaluamos indistinguibilidad conductual con adversarios y consultas acotadas. Resultados clave con Qwen y Llama.

Descubre cómo el apilamiento fiscal reduce tus impuestos y conserva más ingresos de alquiler. Estrategias legales para maximizar tu flujo de caja.
Añadí una caja negra de 71 líneas a mi agente Python y consulté una caída de $200 con DuckDB. Aprende a integrar y optimizar consultas.

<meta name=description content=KBF: El límite del conocimiento como huella para auditar modelos de lenguaje y APIs de caja negra. Descubre cómo esta técnica revela sesgos y limitaciones en sistemas de IA opacos.>

Capacitación de monitores deliberativos para detectar planes en caja negra. Aprende técnicas esenciales de interpretabilidad y seguridad en IA.