MiniMax Sparse Attention: eficiencia en contexto largo
Descubre cómo MiniMax Sparse Attention (MSA) reduce 28.4 veces el cómputo de atención en contextos de 1M tokens, logrando aceleraciones de hasta 14.2x en prefill y 7.6x en decoding en GPUs H800.
Descubre cómo MiniMax Sparse Attention (MSA) reduce 28.4 veces el cómputo de atención en contextos de 1M tokens, logrando aceleraciones de hasta 14.2x en prefill y 7.6x en decoding en GPUs H800.

Descubre BASENet, una red de mejora de voz que alcanza 3.55 PESQ con solo 0.83M parámetros, ideal para streaming en dispositivos limitados.

Descubre cómo la verificación por bloques acelera las difusiones especulativas hasta un 6.3% sin entrenamiento adicional. Optimiza inferencia de modelos de IA.

Metodología 'Agentes hasta el fondo' para construir agentes AI personalizados. Aprende prototype, harvest y agent-tests-agent. Ideal para desarrolladores.

Descubre DiffusionGemma, el modelo de texto por difusión que genera bloques de 256 tokens en paralelo. Más rápido, bidireccional y ajustable en GPUs de consumo. Ideal para desarrolladores.

Mejora el rendimiento de transformers profundos con WAV v1: routing residual multirresolución que reduce pérdida en 48 capas.

SERNF: ajuste fino eficiente de políticas diestras en robótica real. Usa flujos normalizantes y críticos por bloques para adaptación estable con pocas muestras.
![MAGE: El bloque All-[MASK] sabe dónde mirar en difusión por bloques LLM](https://images.unsplash.com/photo-1664526936810-ec0856d31b92?ixid=M3w4MzI5MzV8MHwxfHNlYXJjaHwxfHxzcGFyc2UlMjBhdHRlbnRpb24lMjBibG9jayUyMGRpZmZ1c2lvbiUyMG1vZGVsfGVufDB8fHx8MTc4MDkxMDA3NHww&ixlib=rb-4.1.0)
Con MAGE, la atención dispersa acelera hasta 6.82x la inferencia en contexto largo sin pérdida de precisión.
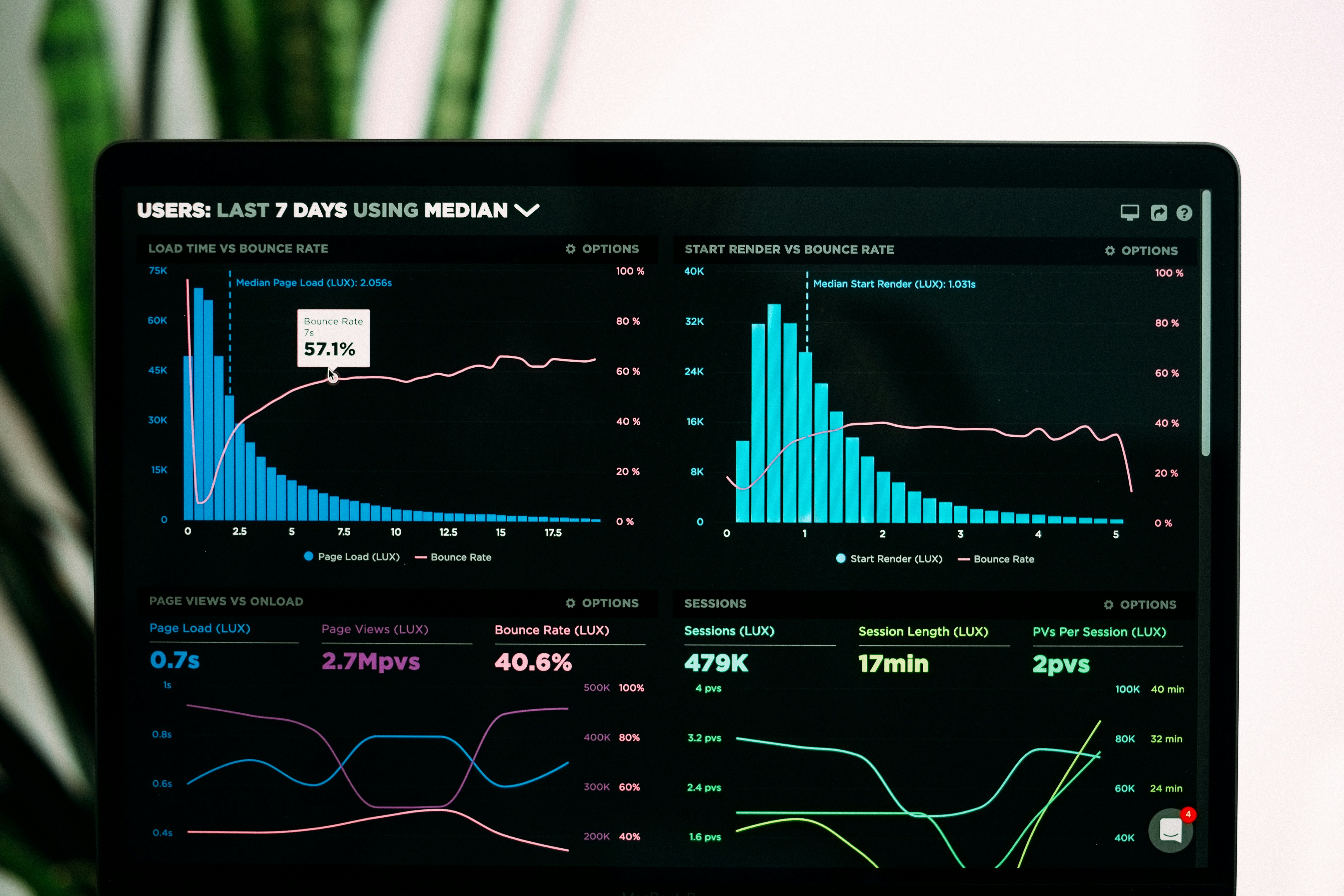
Descubre cómo el modelado de residuos mejora la compresión de datos científicos un 30-60%. LBRC y NGLR para alta fidelidad.

Nuevos límites inferiores de primer orden para optimización no convexa suave de alto orden. Resultados óptimos para Hessianas y terceras derivadas Lipschitz.

Descubre QuBLAST, un framework que reduce el tamaño de LLMs hasta un 45% mediante cuantización por bloques y escalado de activaciones, sin perder rendimiento.

Descubre cómo un nuevo algoritmo espectral logra recuperación parcial y consistencia débil en el modelo HSBM no uniforme para detección de comunidades en hipergrafos.
Descubre cómo recuperar comunidades exactas en hipergrafos no uniformes con algoritmos óptimos. Un umbral preciso incluso si las capas individuales fallan.

Descubre DECA, el ajuste fino completo descentralizado para LLMs con Adam por bloques y datos no IID.

Descubre DECA: ajuste fino completo descentralizado de LLMs en datos no IID. Eficiente y rápido. ¡Infórmate!

Descubre cómo PipeDream logra convergencia en entrenamiento distribuido con un nuevo análisis teórico no convexo. Comparativa con LocalSGD.

Descubre TreeFlash: acelera la decodificación especulativa con aproximación autorregresiva paralela. Logra un 12% más de eficiencia y 9% más de velocidad.
Descubre ParaBlock: una técnica innovadora que acelera el aprendizaje federado de grandes modelos de lenguaje al paralelizar comunicación y computación, manteniendo el rendimiento.

Descubre cómo la atención causal dispersa por bloques puede desconectar tokens adyacentes y cómo reparar los bordes con una solución eficiente.
Descubre cómo bsBSLMM mejora la predicción de expresión génica usando bloques LD y anotaciones. Resultados superiores en TWAS y GWAS.