
SPEAR: Recuperación adaptativa post-cuantización para servir LLMs eficientes
Descubre cómo SPEAR recupera hasta 75% de la brecha de calidad en cuantización de LLMs, con mínimo overhead y latencia estable. Ideal para despliegues eficientes.
Descubre cómo SPEAR recupera hasta 75% de la brecha de calidad en cuantización de LLMs, con mínimo overhead y latencia estable. Ideal para despliegues eficientes.
Descubre cómo la cuantización limita la recuperación top-k en bases de datos vectoriales. Un estudio teórico revela que la dimensión y precisión deben crecer con el corpus.

GRAU: unidad de activación reconfigurable que reduce costos de hardware hasta un 90% en aceleradores de redes neuronales, soportando cuantización mixta y funciones no lineales.

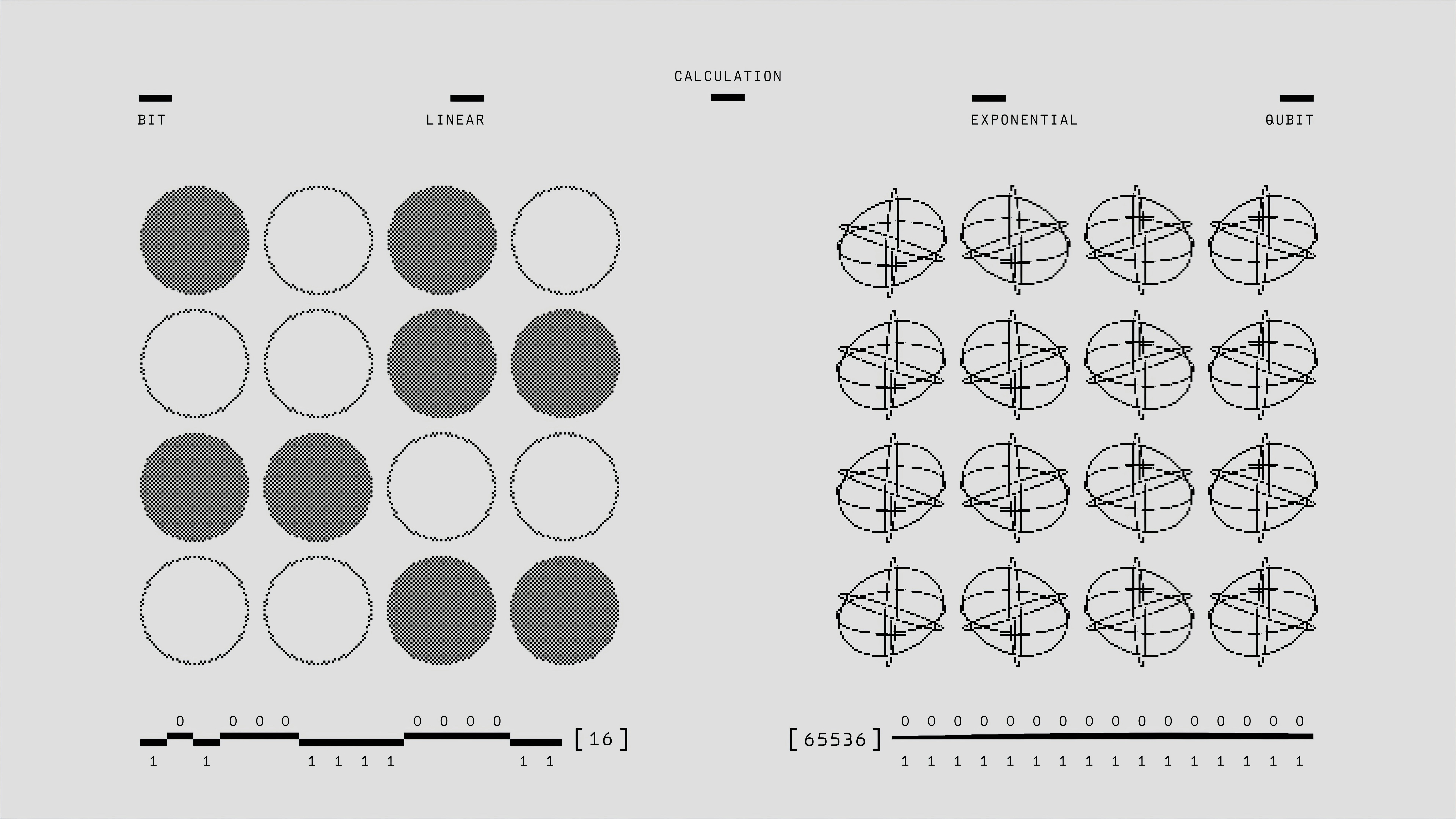
Nuevo método de compilación cuántica que integra detección de errores para aumentar hasta un 68% la probabilidad de éxito en algoritmos cuánticos tempranos tolerantes a fallos.

Descubre cómo la corrección de errores cuánticos mantiene viva la información frágil para el machine learning. Aprende los fundamentos para escalar la IA cuántica.

Los modelos de lenguaje mejoran la compresión de audio sin pérdida. Trilobyte permite compresión a 24 bits, superando a FLAC en 8 y 16 bits.

Descubre los nombres de las PDU en cada capa del modelo OSI: Datos, Segmento, Paquete, Trama y Bits. Mejora tu comunicación técnica en redes.

Descubre LiftQuant: cuantización continua de LLM que permite comprimir modelos de 70B a tan solo 2.4 bits, ajustándose perfectamente a tu memoria GPU.

Descubre por qué el parcheo adaptativo en series temporales no siempre supera al uniforme bien ajustado. Un estudio revela condiciones y umbrales clave.

Recover-LoRA recupera hasta 95% de precisión en modelos de 2 bits usando adaptación de bajo rango y destilación con solo 10k datos sintéticos.

Recover-LoRA recupera hasta un 95% de precisión en modelos de lenguaje cuantizados a 2 bits usando destilación de conocimiento con datos sintéticos. Ideal para despliegue en edge.

Descubre RAVQ-HoloNet, método de compresión holográfica que reduce hasta 33% la tasa de bits y mejora calidad. Ideal para AR/VR de alta fidelidad.

Descubre AlphaQ, un método sin calibración que asigna bits a expertos en MoE basado en la pesadez espectral. Logra compresión 4x con precisión casi total.

Descubre MorphoQuant, un marco de cuantización que mantiene la precisión en modelos omni-modales con solo 4 bits, superando a modelos de 16 bits en ScienceQA.

Descubre Qift: un método de cuantificación sin cero para pesos de 2 bits que mejora la precisión y eficiencia en inferencia de LLM rotados. Simple y sin entrenamiento.

Reduce errores en razonamiento con KVarN. Cuantificación KV de 2 bits que optimiza la memoria y mejora el rendimiento en modelos de lenguaje.

EntQuant comprime modelos de 70B parámetros en solo 10 minutos sin datos de calibración, alcanzando SOTA en compresión extrema a 2 bits con codificación de entropía.

Microsoft presenta Majorana 2, un chip cuántico topológico con qubits 1000 veces más fiables. Un hito hacia la computación cuántica útil.

Descubre cómo los límites de error basados en la complejidad de Rademacher permiten controlar la generalización en computación cuántica de reservorios, incluso con escalamiento exponencial de qubits.

Descubre ChWDTA, un nuevo modelo que combina CNN y transformer con wavelets para lograr reducciones BD-rate de hasta 22% en compresión de imágenes.