
Anthropic presenta Claude Fable 5: un modelo seguro y potente
Anthropic presenta Claude Fable 5: modelo seguro con salvaguardas, retención de datos 30 días y precios reducidos. Supera benchmarks.
Anthropic presenta Claude Fable 5: modelo seguro con salvaguardas, retención de datos 30 días y precios reducidos. Supera benchmarks.

Descubre Multi-PixMo, un conjunto de datos multilingüe para entrenar modelos de lenguaje visual. Mejora el rendimiento en 5 idiomas europeos con benchmarks traducidos. ¡Optimiza tu VLM!

Descubre cómo SySRs reduce costos al evaluar LLMs, aprovechando la similitud entre modelos para identificar el mejor sin desperdiciar recursos.

Descubre cómo redes ultracompactas de solo 3K parámetros saturan benchmarks de EEG y por qué las métricas de reconstrucción no predicen utilidad en BCI.
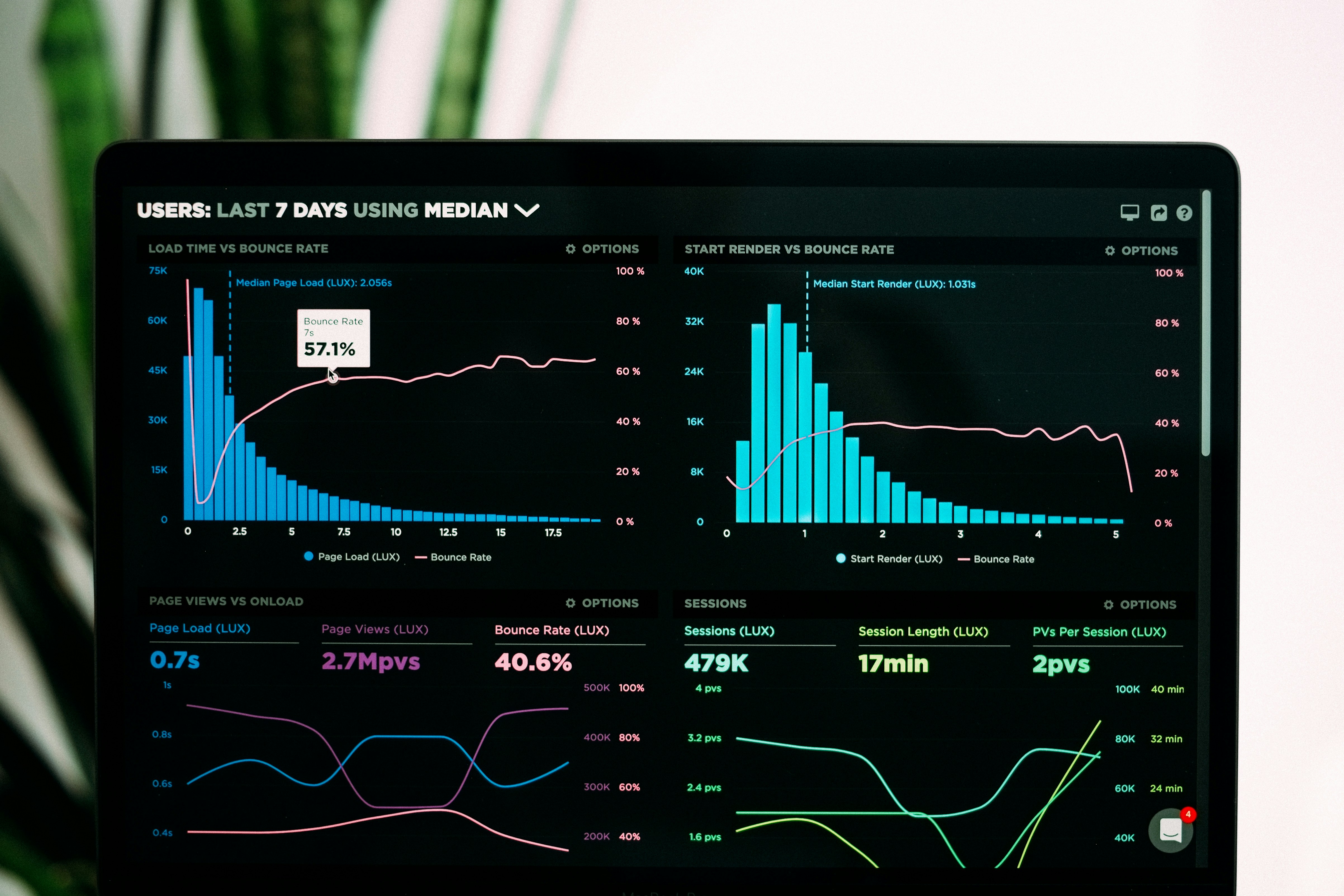
Descubre los nuevos conjuntos de datos de arXiv y GitHub para predecir citas y forks a partir de interacciones tempranas. Una base empírica para el forecasting lead-lag.

Descubre cómo los LLMs y agentes inteligentes automatizan la generación y optimización de kernels GPU, superando limitaciones humanas. Revisión exhaustiva de métodos, datasets y desafíos futuros.
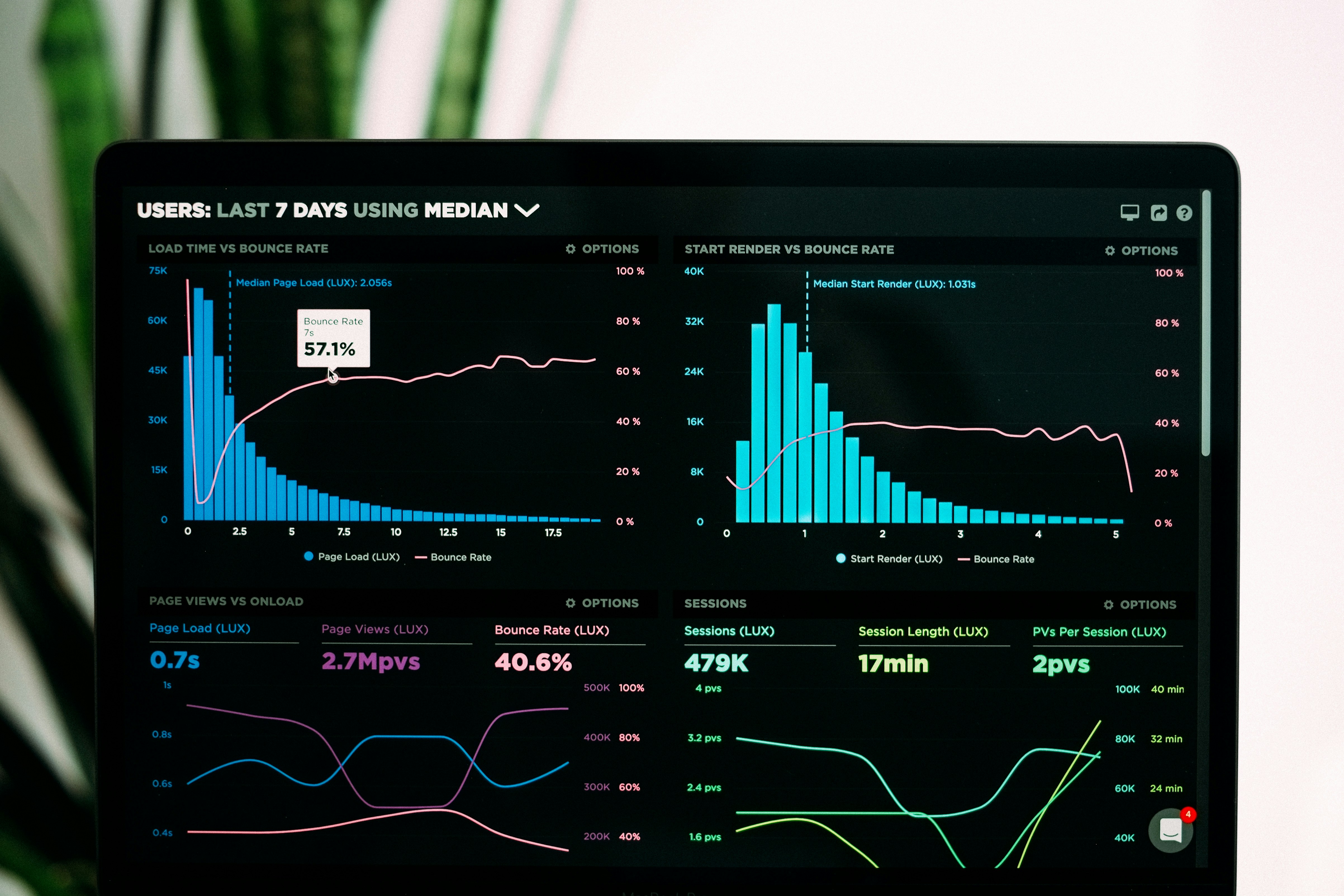
Descubre por qué el aprendizaje multitarea requiere un 30-40% de solapamiento de datos para que el análisis de gradientes sea fiable. Muchos benchmarks fallan.

Explora el estado del arte de las HGNN para detección de anomalías en ciberseguridad. Taxonomía, benchmarks y desafíos clave.
Este marco jerárquico construye intervalos de rango con garantías estadísticas para evaluar modelos en líderboards, manejando la incertidumbre entre tareas.
Descubre phepy, un benchmark visual para evaluar detectores OOD, y las mejoras como t-poking y ponderación que afinan la frontera ID-OOD.

Ejecutar dos LLMs en una Mini PC suena bien, pero los benchmarks revelan un cuello de botella de memoria que lo hace contraproducente.
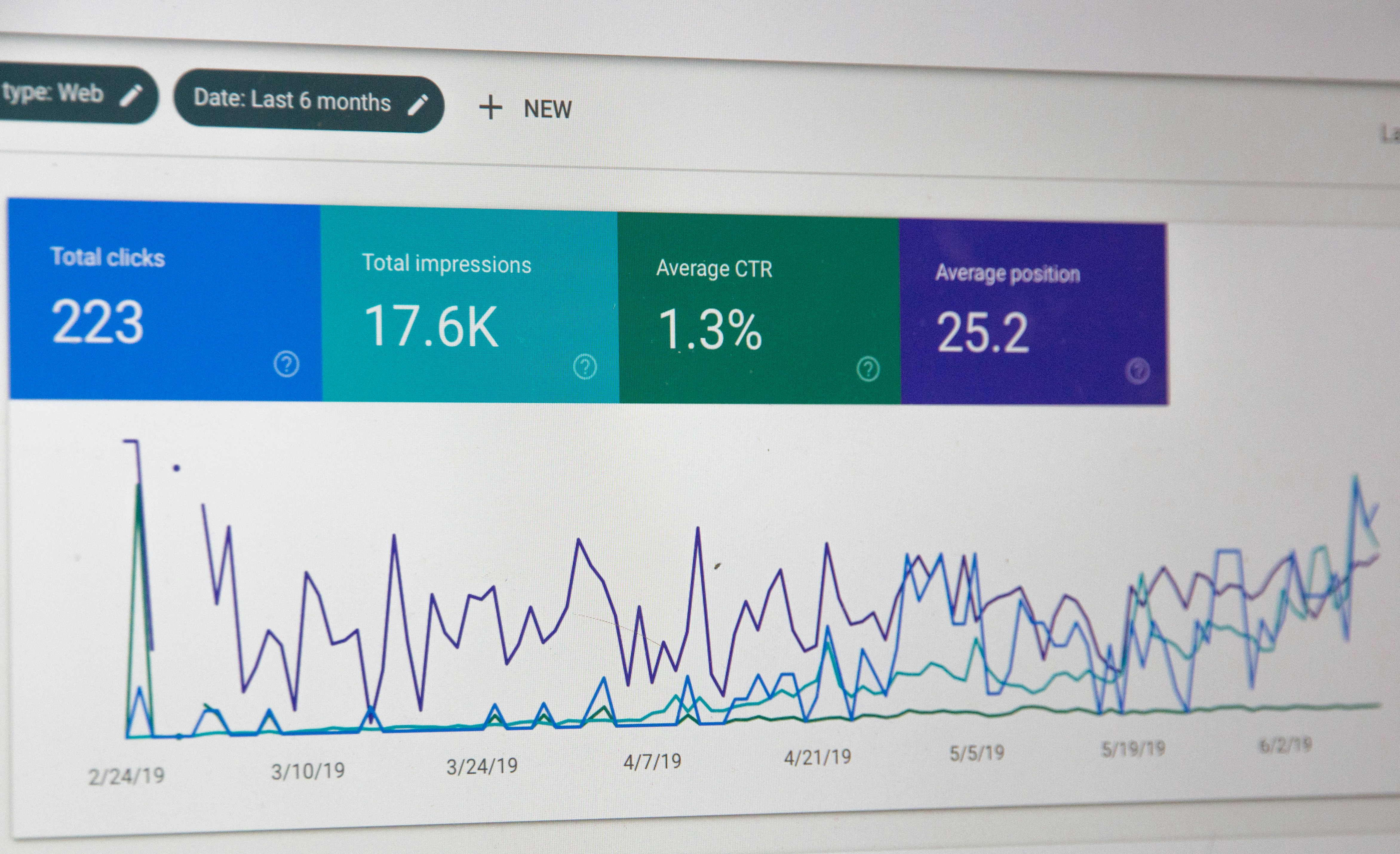
Descubre cómo extraer computables de benchmarks para obtener evidencia semántica inspeccionable y superar limitaciones del razonamiento textual.

Descubre cómo la inferencia colaborativa edge-to-server reduce el costo de comunicación en modelos VLM sin sacrificar precisión. Optimiza tu infraestructura con transmisión selectiva.

¿Los modelos de lenguaje pequeños realmente aprenden de sus errores? Un estudio revela que solo mejoran un 4.4% y que más razonamiento puede empeorarlos.
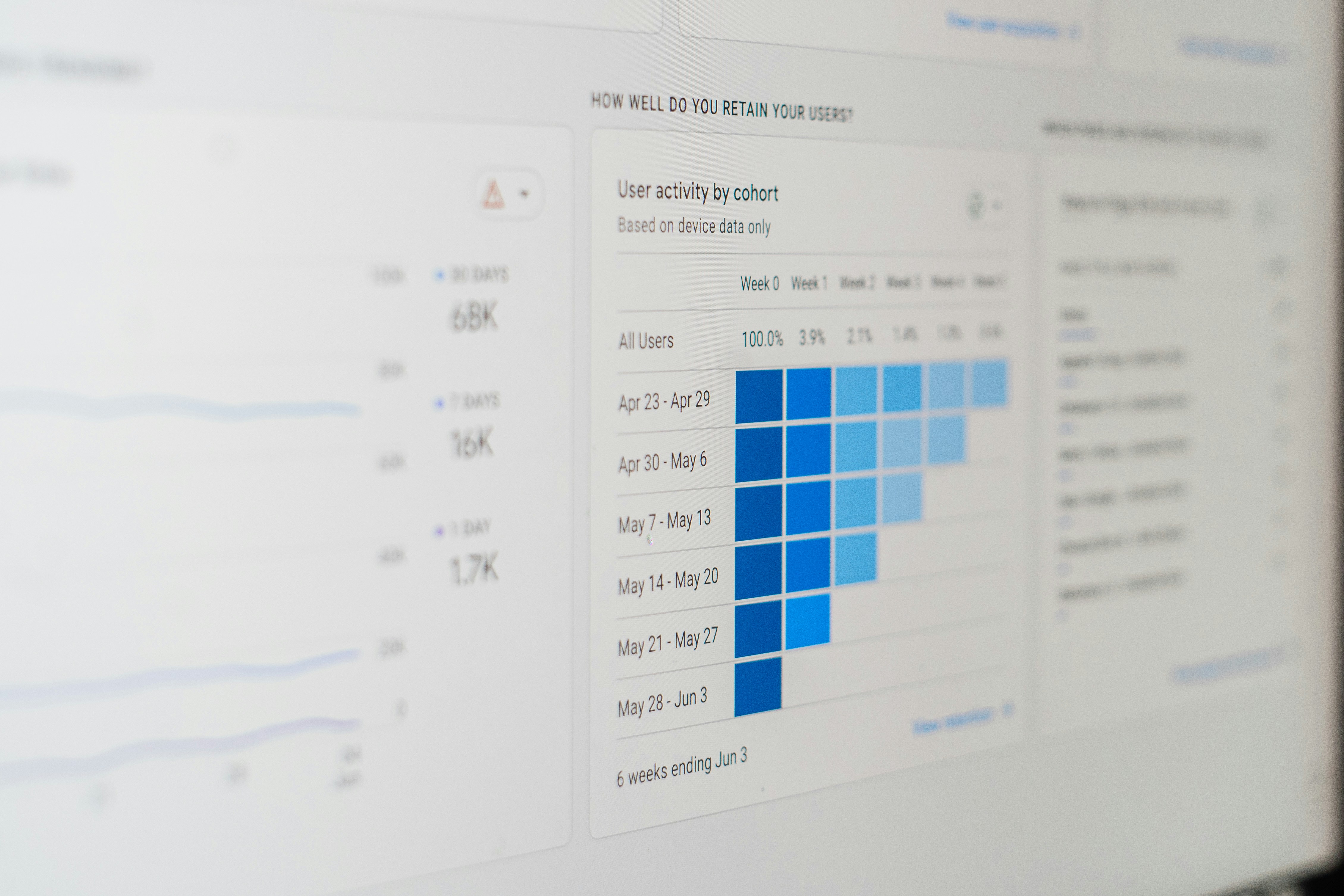
Descubre PIPE-Cypher: genera benchmarks personalizados para Text2Cypher en grafos empresariales. Ideal para equipos de IA.

Las comparaciones por pares con Elo generan rankings de precisión casi perfectos en modelos de IA, minimizando sesgos de estilo y juez. ¡Descúbrelo!

Evaluation Cards: una capa interpretativa que mejora la transparencia y comparabilidad en reportes de evaluación de IA, con análisis de más de 100 mil resultados.

Descubre ABLE: representa y compara LLMs con atribuciones de gradientes sin entrenamiento. Ideal para selección de modelos y auditoría de seguridad.

El post-entrenamiento actual de LLMs es en realidad un ajuste fino masivo. ¿Estamos retrocediendo a métodos antiguos? Descúbrelo.

Descubre cómo el fine-tuning de Whisper logra 25.6% WER en alemán suizo, evitando contaminación de benchmarks. Un análisis honesto con 13.8% cWER y modelos públicos.