
Inversión óptima de matrices con multiplicación para atención lineal cuantizada
Aceleración 5x en atención lineal en NPU con inversión de matrices solo multiplicación, reduciendo 20% sobrecarga sin perder precisión.
Aceleración 5x en atención lineal en NPU con inversión de matrices solo multiplicación, reduciendo 20% sobrecarga sin perder precisión.
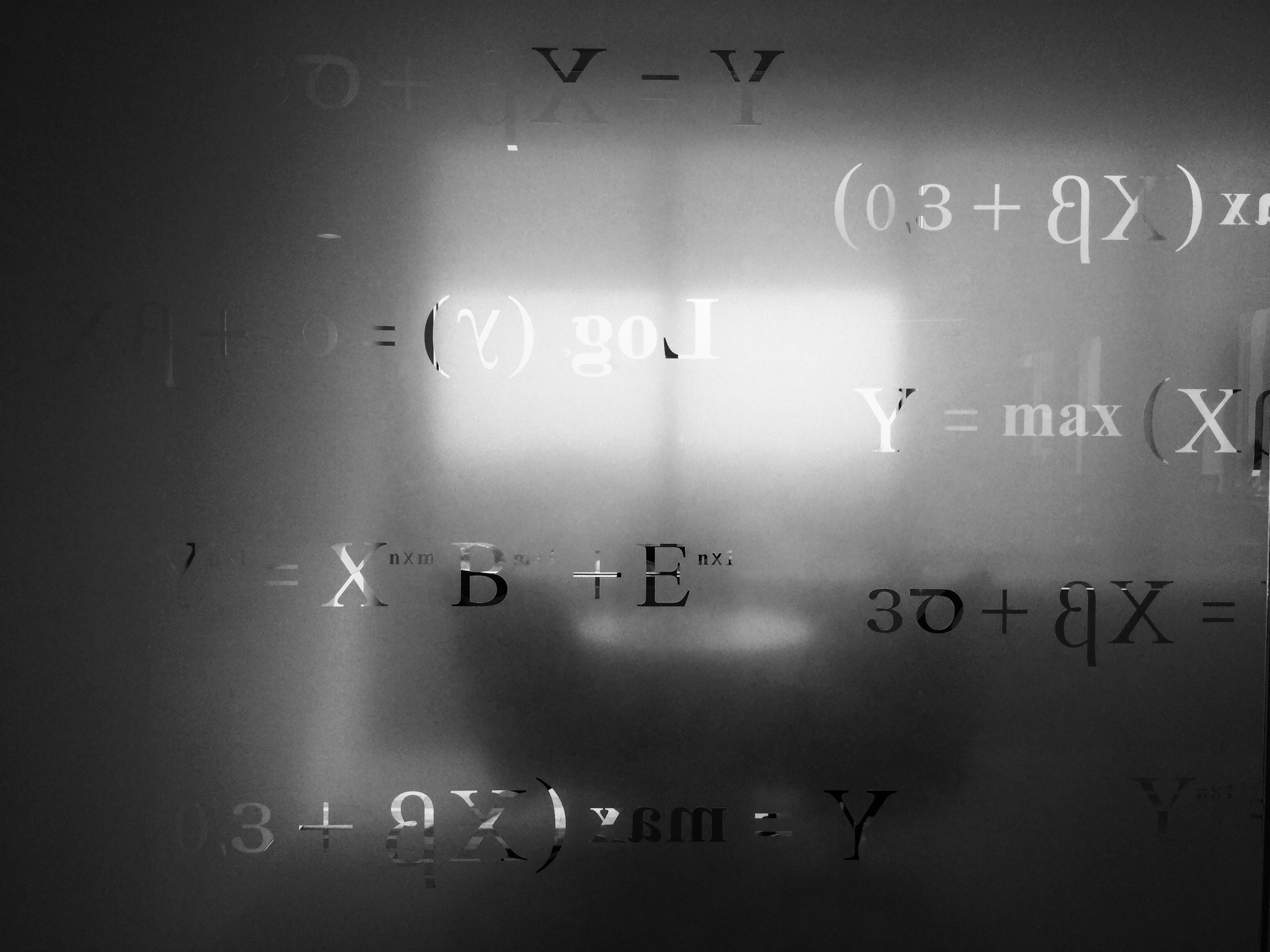
STaR-Quant mejora la cuantificación de baja precisión en DLLMs, logrando 1.69x aceleración y 3.14x ahorro de memoria sobre FP16. Descubre cómo optimizar tu modelo.

WUSH mejora la cuantización de LLMs hasta +2.8 puntos en W4A4. Transformaciones adaptativas casi óptimas para despliegue eficiente en GPU.

Descubre cómo LASER logra una aceleración 2.3x en modelos visión-lenguaje con baja precisión, usando SVD consciente de pérdida y asignación de rango.

GPTQ-intrinsic LoRA: mejora la cuantización de baja precisión con corrección de bajo rango. Algoritmo casi óptimo para modelos grandes.

GPTQ-intrinsic LoRA combina cuantización de baja precisión y adaptación de bajo rango para comprimir redes neuronales. Algoritmo sin entrenamiento mejora modelos como Qwen3 y DeiT.

Descubre GNMR, un controlador ligero que estabiliza el entrenamiento de modelos de lenguaje en baja precisión sin cambiar el formato numérico. Mejora la calidad y reduce costes.
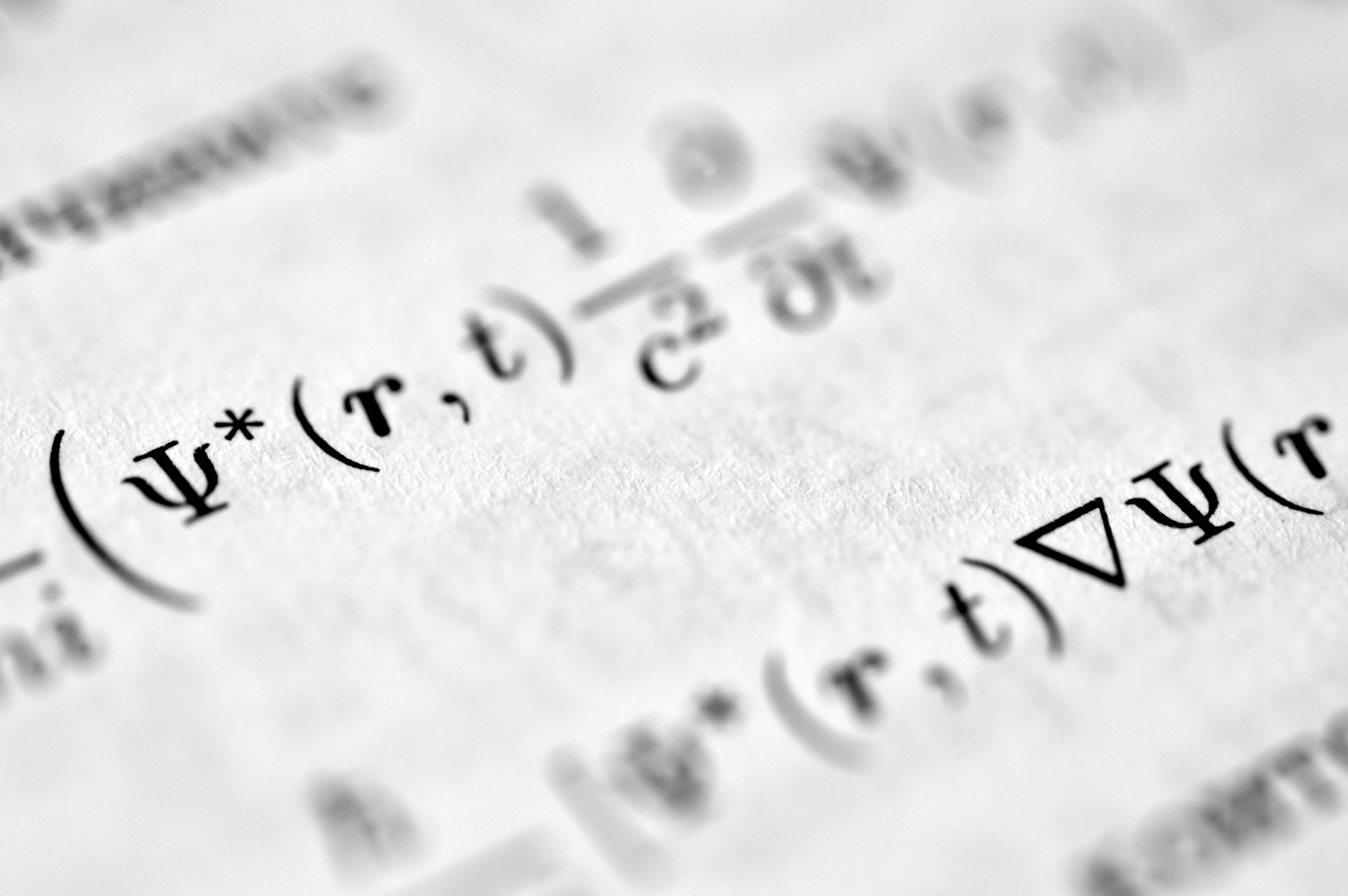
BitsMoE asigna bits inteligentemente en MoE LLM, logrando cuantización 2 bits con 27.83% más precisión, 12.3x más rápida y 1.76x más velocidad.

Descubre cómo optimizar modelos de video Wan2.2 con destilación y cuantización de baja precisión. ¡Mejor calidad, menos pasos!