
Optimalidad asintótica de Thompson Sampling para bandidos aversos al riesgo
Un algoritmo de Thompson Sampling no paramétrico logra optimalidad asintótica en bandidos aversos al riesgo con recompensas subgaussianas.
Un algoritmo de Thompson Sampling no paramétrico logra optimalidad asintótica en bandidos aversos al riesgo con recompensas subgaussianas.

Aprende cómo la factorización CP y la doble proyección mejoran la estimación de cargas factoriales en series temporales tensoriales de alta dimensión.

Descubre cómo las distribuciones Gaussianas en Transformers simplifican su dinámica y revelan condiciones de estabilidad y alcanzabilidad.
Descubre cómo la universalidad gaussiana se rompe en la minimización de riesgo empírico de alta dimensión y sus implicaciones para el aprendizaje automático

Descubre cómo eliminar sesgos en modelos de caja negra para una estimación semiparamétrica más precisa. Nuevo método que supera al Double Machine Learning clásico.

El algoritmo MNEM elimina el sesgo en mezclas gaussianas con datos heterogéneos y etiquetado parcial. Ideal para aprendizaje federado descentralizado.

Aprende cómo Generative Augmented Inference (GAI) combina datos de IA y humanos para una inferencia causal más precisa, reduciendo errores y mejorando intervalos de confianza.

Descubre cómo los nuevos límites pseudoespectrales revelan amplificación transitoria en gradiente acoplado. Clave para optimización bilevel y adversarial.

Descubre la relación asintótica entre capacidades de redes neuronales reales y complejas en espacios complejos usando la fórmula HCIZ.
Descubre cómo la profundidad del razonamiento en cadena afecta la generalización en modelos de lenguaje. Teoría asintótica y fases de mejora exponencial.

Descubre cómo la truncación balanceada con cuadratura Hermite simétrica permite aprender sistemas dinámicos lineales a partir de datos de derivadas, preservando estabilidad y hermiticidad.

Descubre los nuevos límites de convergencia no asintóticos para Engression y Reverse Markov Engression. Resultados casi óptimos para aprendizaje de distribuciones condicionales con redes profundas.

Descubre pruebas privadas casi óptimas para hipótesis simples y MLR con privacidad diferencial gaussiana. Resultados comparables a pruebas no privadas.
Aproxima divergencias-f con estadísticos de rango. Método rank-statistic para alta dimensión usando proyecciones aleatorias. Eficiente y validado.

Descubre cómo una gaussiana aproxima iteraciones de SA con cotas de error explícitas y tasas de convergencia óptimas, validado con simulaciones.

¿Cuándo confiar en el promedio bayesiano sobre árboles? Descubre las garantías teóricas y umbrales racionales con prior Catalan-Exponencial.
Descubre cómo el marco de Lyapunov permite analizar la convergencia en tiempo finito de algoritmos estocásticos como Q-learning y SGD. Ideal para IA y RL.
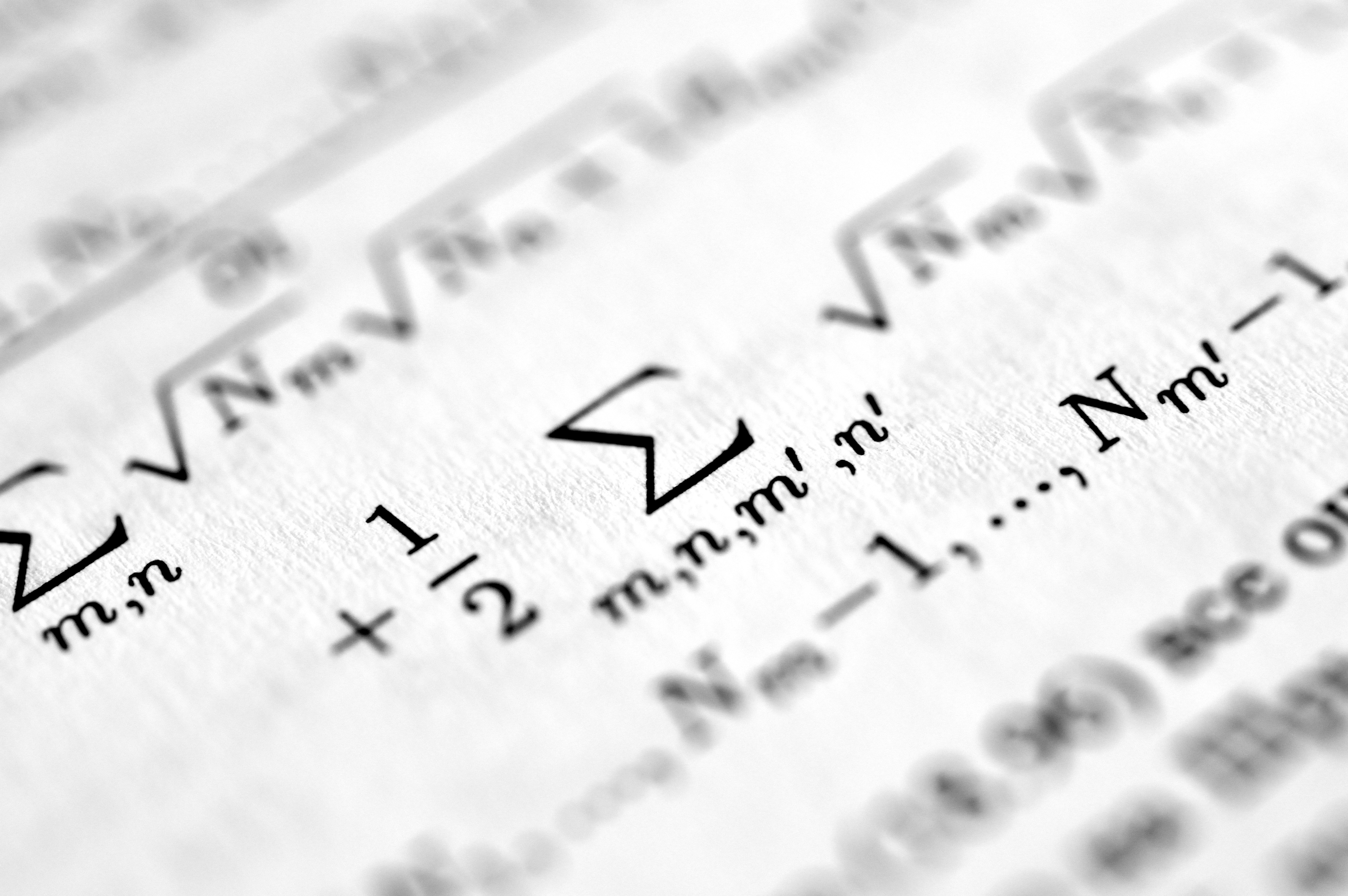
Descubre cómo las funciones de Lyapunov permiten analizar la convergencia finita de algoritmos estocásticos en aprendizaje automático y refuerzo.
Método de muestreo de orden cero con reducción de varianza para distribuciones no log-cóncavas. Aplicado a problemas inversos con garantías de convergencia.