
Algoritmo de gradiente no monótono para NMF simétrica y clustering
Algoritmo SNMPBB: gradiente no monótono para NMF simétrica. 6x más rápido que alternativas y superior en clustering de grafos. ¡Optimiza!
Algoritmo SNMPBB: gradiente no monótono para NMF simétrica. 6x más rápido que alternativas y superior en clustering de grafos. ¡Optimiza!

Descubre cómo integrar datos clínicos multimodales con ML mejora la predicción de recurrencia del cáncer de mama.

MASC ofrece desaprendizaje rápido a gran escala para modelos de lenguaje, sin reentrenamiento. Mejora la eficiencia y preserva la utilidad. ¡Conoce el método!

Arquitecturas jerárquicas RBF-KAN y RBF-SKAN para aproximación multidimensional y aprendizaje de campos aleatorios. Reduce la maldición de la dimensionalidad.

Descubre cómo el método LPCD burla a los atacantes 'camaleón' que cambian tácticas en streaming, usando desacoplamiento contrafáctico para evaluar riesgos.
Descubre BYORn, método que protege modelos visión-lenguaje durante fine-tuning contra ataques backdoor, mejorando robustez.
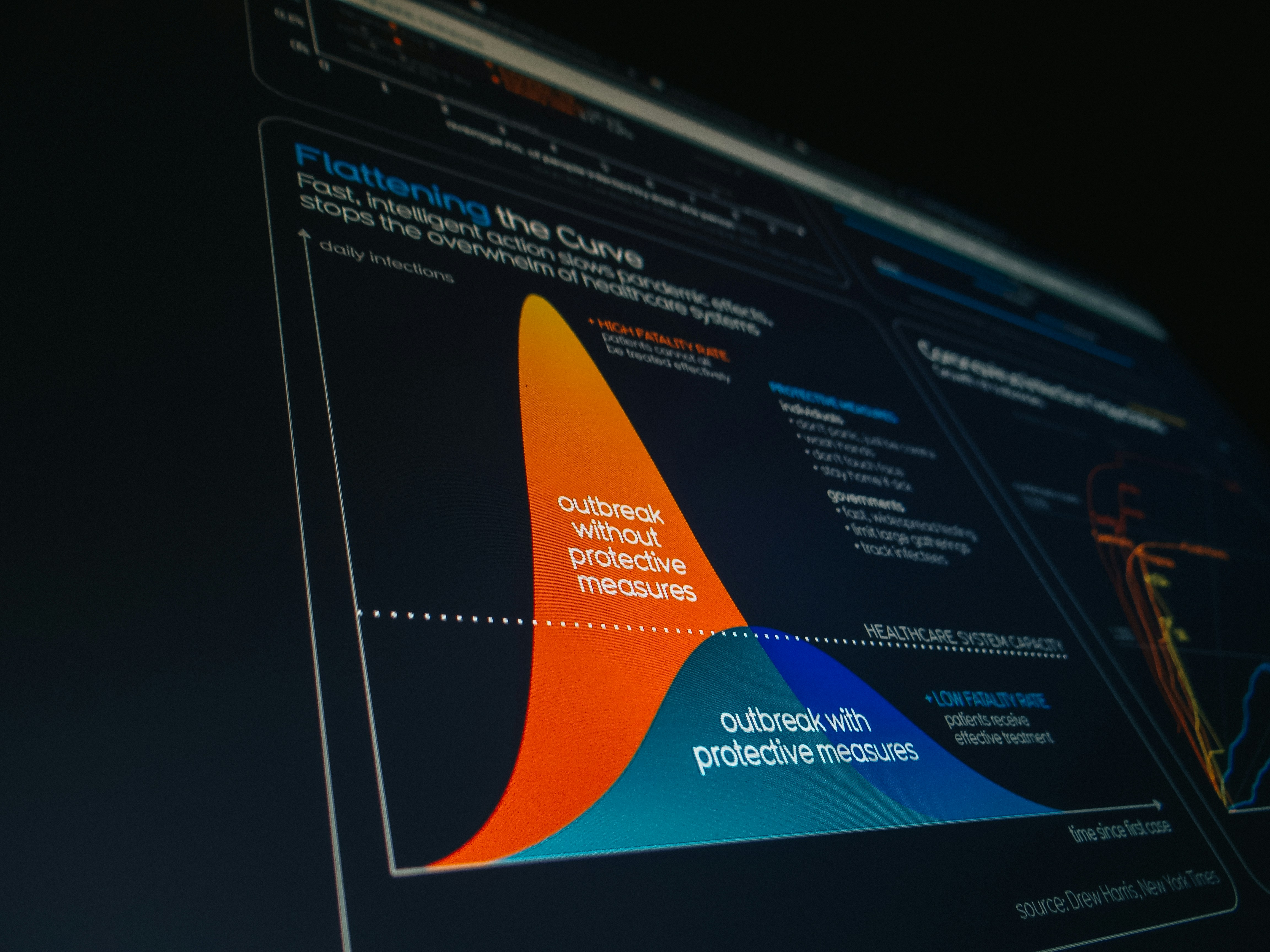
Descubre cómo FTPL se adapta a la curvatura en optimización online, logrando desde O(√T) hasta O(log T) de regret sin conocer la curvatura por adelantado.

Descubre cómo las redes neuronales aprenden representaciones espectrales de grupos, convergencia demostrable a irreducibles y compresión de bajo rango.

CoughSense clasifica tos en 5 enfermedades con 82.3% de precisión usando Whisper y aprendizaje contrastivo. Descubre cómo supera el desbalance de clases.

Descubre cómo la Destilación de Confusión (CD) mejora el aprendizaje de modelos sin profesor, superando a otros métodos en CIFAR-100.

CoughSense clasifica tos en 5 enfermedades con 82.3% precisión. Descubre atención activa en Whisper y fusión dual.

Descubre el fenómeno de rotación del conjunto correcto en RLVR, donde modelos olvidan problemas resueltos. Conoce REMIND, una técnica que mejora la retención sin costo adicional.

Analizamos el aprendizaje de características en destilación de conocimiento y presentamos Confusion Distillation, una auto-destilación eficiente que supera a otros métodos en 1.2%.

FGRPO: fine-tuning privado de modelos de lenguaje con agregación adaptativa en datos no IID. Mejora el razonamiento sin exponer datos.
El aprendizaje por refuerzo profundo optimiza la estimulación de implantes epirretinianos para generar imágenes claras. Un avance para restaurar la visión.

¿RLVR olvida lo que aprendió? Descubre la rotación del conjunto correcto y cómo Remind lo corrige sin coste. Mejora tus modelos.

TiWeaver optimiza el pronóstico multivariante mediante parcheo contextual y manejo de datos irregulares. Logra hasta un 25% más de precisión.

FGRPO optimiza modelos de razonamiento con agregación adaptativa en datos no IID, preservando privacidad.

Descubre cómo el algoritmo LG-ND optimiza el ancho neuronal para proxies ACOPF, reduciendo neuronas hasta 10 veces y garantizando verificación formal en sistemas críticos.

Genera ejemplos sintéticos sin ejecución para mitigar alucinaciones en autocompletado. +18.8 EM en Delulu.