
Optimización de Políticas con Restricciones de Utilidad
Descubre cómo la optimización de políticas con restricciones de utilidad permite entrenar agentes de RL más seguros y flexibles, superando a métodos tradicionales.
Descubre cómo la optimización de políticas con restricciones de utilidad permite entrenar agentes de RL más seguros y flexibles, superando a métodos tradicionales.

Descubre cómo la optimización con restricciones de utilidad mejora la seguridad en RL, permitiendo límites flexibles y mejor rendimiento sin coste extra.

Descubre cómo los procesos gaussianos multivista detectan texto generado por IA con alta precisión, incluso frente a ataques adversariales.

Aprende sobre el Deep Spectral Encoder, un modelo de aprendizaje profundo que usa operadores de transferencia latentes para sistemas dinámicos estocásticos, con

Nuevo enfoque con funciones de Lyapunov reduce la complejidad de muestreo en MDP débilmente acoplados, logrando rendimiento casi óptimo con recursos polinómicos.

Nuevo método de aprendizaje espectral: DSE mejora filtrado bayesiano y descomposición Koopman en sistemas estocásticos mediante operadores latentes.

Descubre cómo el análisis de Lyapunov permite aprender políticas casi óptimas en MDPs débilmente acoplados y bandidos inquietos con complejidad polinómica.

Blindaje compositivo basado en contratos garantiza seguridad en sistemas multiagente sin sacrificar eficiencia. Una técnica descentralizada para MARL.

Aprende cómo el blindaje por contratos permite seguridad determinista en aprendizaje multiagente descentralizado, optimizando la recompensa sin control centralizado.
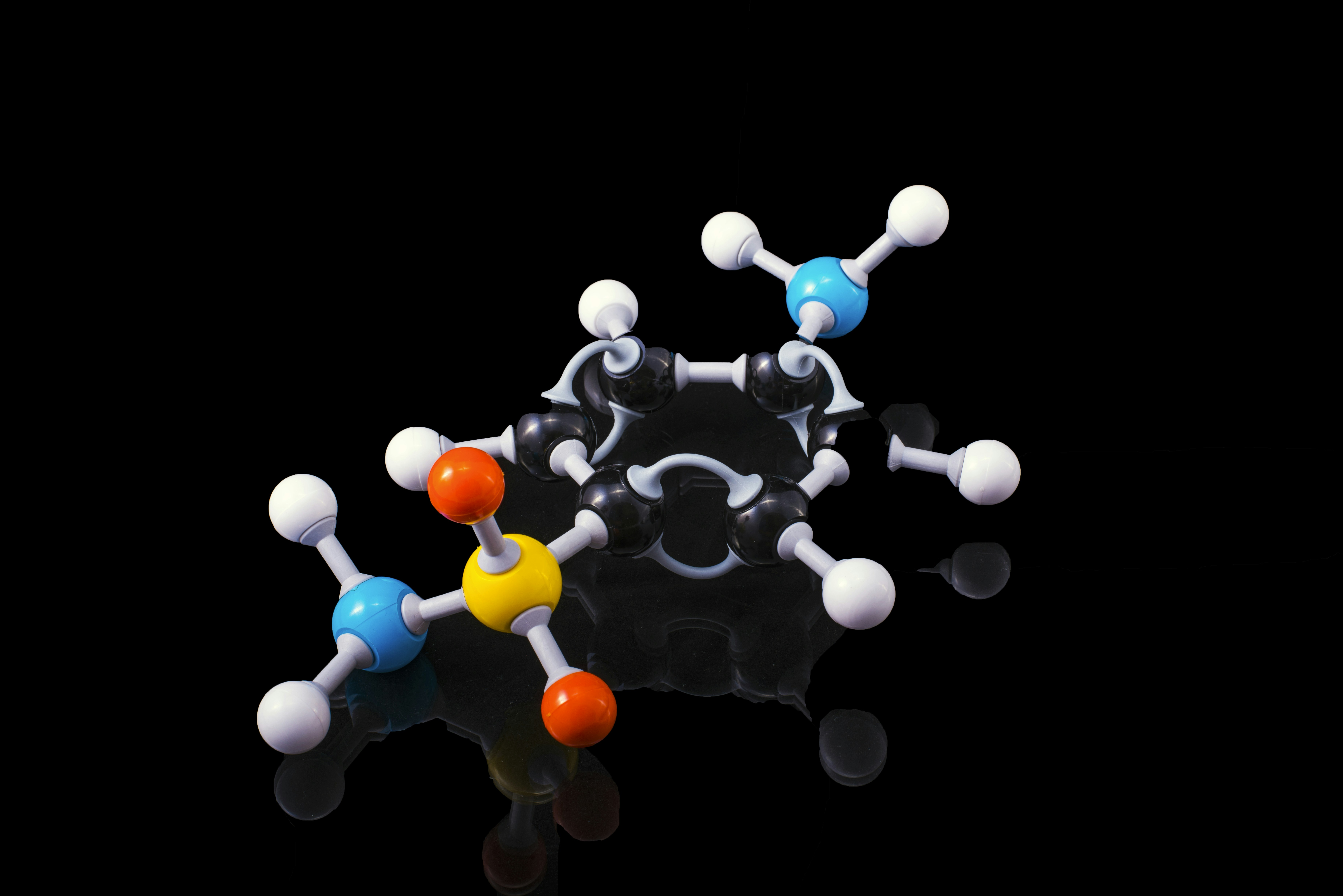
Mejora la predicción de afinidad proteína-ligando con RicciBind, que integra curvatura de Ricci y transporte óptimo para resultados más precisos.
Descubre cómo RicciBind mejora la predicción de afinidad proteína-ligando usando curvatura y transporte óptimo. Mayor precisión e interpretabilidad en el descubrimiento de fármacos.

Descubre CoMAG, un método que alinea contextos y modalidades en grafos atribuidos multimodales para mejorar predicciones y emparejamiento. ¡Resultados líderes!

CoMAG unifica grafos multimodales aprendiendo contextos adaptativos y alineando modalidades sin comprimir información. Logra estado del arte en predicción, matching y generación.

Zeta: optimizador con blanqueo dual que acelera el entrenamiento de modelos grandes, superando a Muon en convergencia y generalización.

Mejora tus pujas automatizadas con DRIVE: un innovador marco Transformer que separa la generación de acciones de la toma de decisiones. ¡Optimiza tu ROI!

DRIVE mejora pujas offline combinando recuperación de decisiones, evaluación de valor y Transformers. Aumenta tu ROI.

Mejora la estimación dinámica en entornos ruidosos con adaptación de ruido estructurado en filtros Bayesianos secuenciales y operadores latentes.
CPES predice afinidad proteína-ligando modelando flexibilidad molecular con curvatura de energía potencial. Mejora precisión e interpretabilidad.

Aprende cómo el método ORCA adapta modelos de series temporales en caja negra aprovechando el contexto de los errores para mejorar la precisión sin reentrenamiento.

El método IVRS combina redes neuronales y muestreo por rechazo para mejorar la inferencia bayesiana con aproximaciones posteriores precisas y un ELBO ajustado.