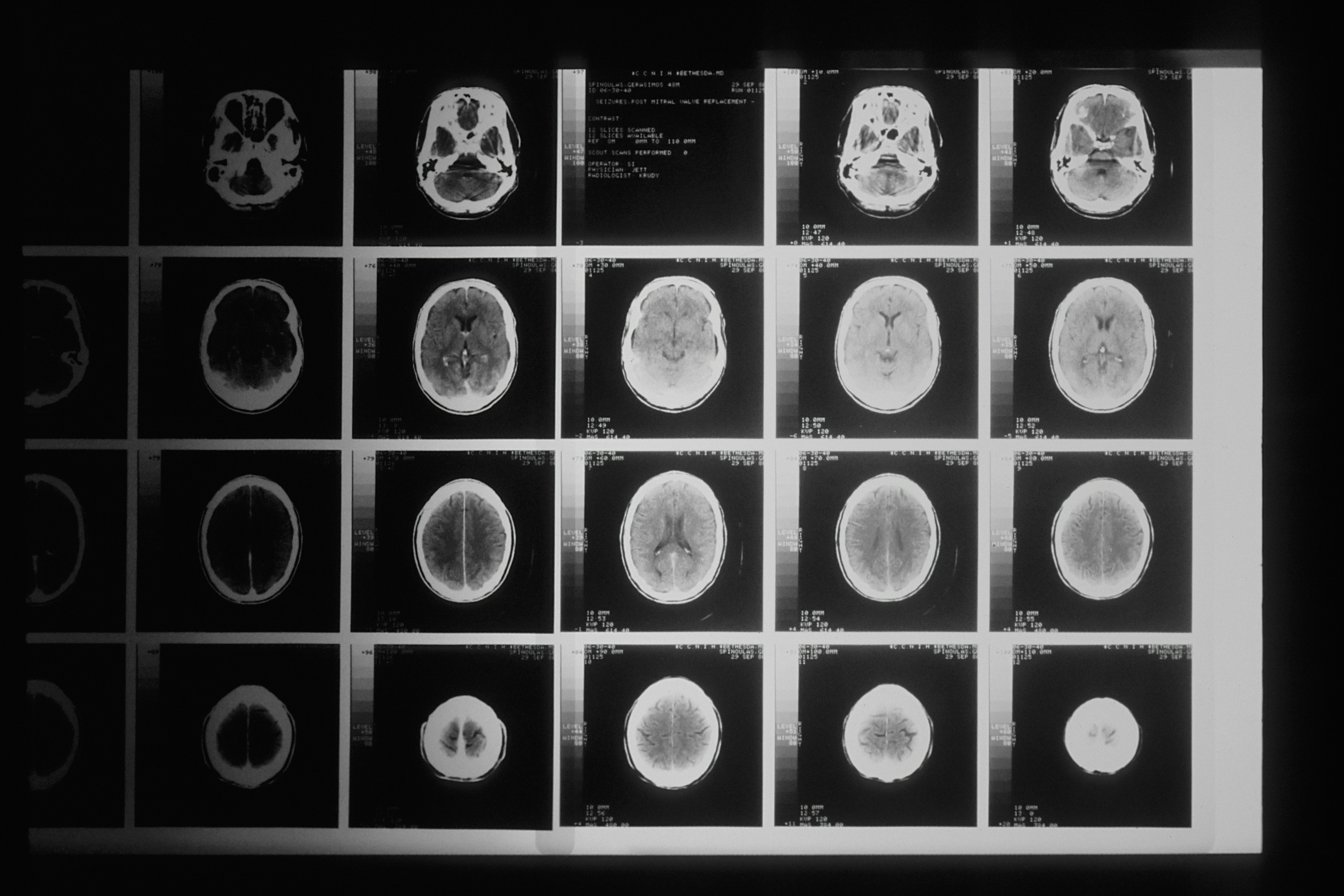
++nnU-Net: Escalando nnU-Net con aumento de datos basado en prefijo
El ++nnU-Net usa aumento de datos por registro para mejorar hasta un 22% la precisión en segmentación médica. Código abierto disponible.
El ++nnU-Net usa aumento de datos por registro para mejorar hasta un 22% la precisión en segmentación médica. Código abierto disponible.

Descubre EEG-TransNet, un modelo basado en Transformers que revoluciona el reconocimiento de emociones mediante señales EEG. Alta precisión y robustez.

ADAS introduce un descuento por atención en el muestreo paralelo, mejorando la calidad de modelos de difusión enmascarada sin entrenamiento adicional. Aumenta precisión en benchmarks hasta 10 puntos.

Descubre cómo el promedio geométrico de actualizaciones de objetivo duro estabiliza el Q-learning lineal. Un nuevo enfoque para mejorar el aprendizaje por refuerzo.

Descubre Pose-ICL, un nuevo método de IA que permite controlar la pose de objetos personalizados en generación de imágenes con alta precisión y consistencia.
¿Qué pistas usan los detectores de deepfake de voz? Descubre cómo analizan ambiente, fonemas y bordes de palabras para detectar audios falsos. Explicabilidad con IA.

Estructuras lineales locales en pesos y activaciones son recuperables pero evolucionan rápido, desafiando direcciones de tarea fijas. Estudio con GPT-2 y LoRA.

CPPO mejora la estabilidad y precisión del razonamiento en LLMs al superar las regiones de confianza uniformes. Nuevo enfoque de optimización.

Mejora la transparencia de la IA en redes con un novedoso marco de explicabilidad generativa que combina LLM y SHAP, logrando un 97.5% de corrección y mayor utilidad.

CPPO mejora el razonamiento de LLM al reemplazar la confianza uniforme por divergencia de prefijo acumulativa. Mayor estabilidad y precisión.

Descubre cómo AuRA internaliza la comprensión del audio en LLMs mediante LoRA, superando a sistemas en cascada con mayor eficiencia y precisión.

RoboNaldo logra tiros de fútbol humanoide precisos y potentes con RL curricular. Error reducido 48.6% y velocidad 2.96x.

Descubre RoboNaldo, un novedoso marco de RL que logra disparos precisos y potentes en fútbol humanoide. Reduce el error un 48.6% y alcanza 13.10 m/s. ¡Lee más!

Descubre TRACE, un marco que optimiza la asignación de presupuesto de rollout en RL agente, mejorando el contraste de recompensas y la eficiencia en benchmarks.

Descubre cómo TRACE asigna presupuesto de rollout a nodos prometedores en RL agente multi-turno, mejorando contraste de recompensas y rendimiento.

Descubre cómo PCAF revoluciona el modelado de lenguaje con memoria dispersa paralela, logrando mayor velocidad y eficiencia que transformers tradicionales. ¡Lee más!
GraphAE usa representaciones ocultas del RM para estimar ventajas con grafos. Mejora el RLHF hasta +6.3 en Arena-Hard.

Descubre cómo GraphAE aprovecha las representaciones ocultas del modelo de recompensa para una estimación de ventajas más precisa en RLHF, mejorando rendimiento hasta +8.27 en AlpacaEval.

El método DGF elimina el suavizado excesivo en pronósticos de series temporales, preservando cambios bruscos y modos dinámicos. Mejora precisión y consistencia.

Descubre cómo Dirichlet-Guided Group Forecasting reduce el sobre-suavizado en series temporales, mejorando precisión y diversidad en predicciones multimodales.