
GPO: Aprendizaje de pasos críticos para mejorar razonamiento LLM
GPO identifica pasos críticos en el razonamiento de LLMs y optimiza el aprendizaje. Mejora el rendimiento con esta estrategia de fine-tuning.
GPO identifica pasos críticos en el razonamiento de LLMs y optimiza el aprendizaje. Mejora el rendimiento con esta estrategia de fine-tuning.

¿Tu IA solo responde? Descubre el modelo de madurez para pasar de chatbots a agentes autónomos que ejecutan acciones. Aprende los 4 niveles, gobernanza y KPIs.
Las calificaciones no cuentan toda la historia. Descubre cómo la IA transforma las notas en diagnósticos precisos del aprendizaje.

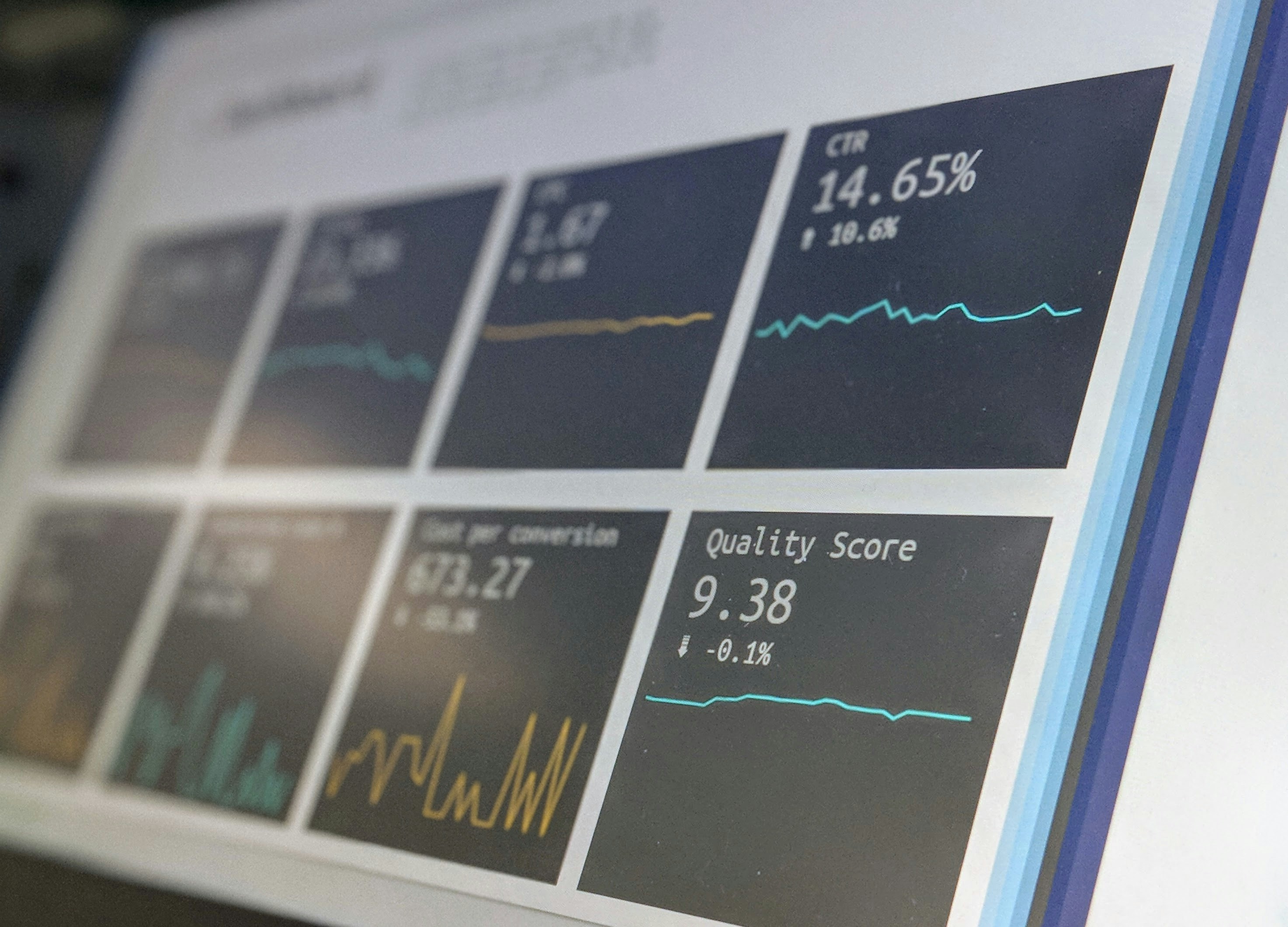
Las mejores prácticas de automatización de procesos se integran con IA para lograr una automatización inteligente, segura y alineada con tus objetivos.

¿Cuánta capacitación necesitas para aplicar mejores prácticas de automatización? Q2BSTUDIO te ofrece programas personalizados con microlearning y certificación.

Descubre cómo Ultralytics democratiza la visión IA con YOLO, permitiendo a desarrolladores y empresas implementar visión por computadora de forma sencilla.

Descubre los 24 episodios más recientes sobre IA, cloud, ciberseguridad y startups. ¡No te pierdas las tendencias del 11 de junio!

La inteligencia artificial potencia el SaaS: mejora eficiencia, toma de decisiones y experiencia del cliente. Conoce ejemplos clave de startups.

Descubre cómo un socio de transformación digital puede modernizar tus procesos. Accede a guías, casos de éxito y una sesión sin compromiso con Q2BSTUDIO.

Q2BSTUDIO integra herramientas de IA en la transformación digital para automatizar procesos, mejorar gobernanza y acelerar la innovación.

Descubre las novedades de OpenCV 5: mejoras en rendimiento, nuevo motor DNN, soporte ONNX y más. Aprende cómo instalar y aprovechar esta potente librería.

Aprende a entrenar un modelo de puntuación robusto en la era de la IA. Metodología estructurada para comparar, probar estabilidad y seleccionar el mejor score.

Descubre cómo la asistencia predictiva de la IA altera la compresión exploratoria, reduciendo la movilidad cognitiva y generando histéresis. Implicaciones para el aprendizaje y desarrollo.

Un estudio revela que el ajuste fino con razonamiento sintético empeora la predicción de Alzheimer, a pesar de razonamientos precisos. Descubre por qué.

DiRL: marco de RL que distingue razonamiento de memorización en LLMs, mejorando exploración y resultados en benchmarks.

ReflectiChain integra LLMs y RL para cerrar la brecha epistémica en cadenas de suministro, mejorando un 33% la consistencia racional y mostrando comportamiento antifrágil bajo presión.

Descubre cómo la inferencia activa optimiza tratamientos oncológicos personalizados, mejorando la eficacia bajo restricciones reales de medición y presupuesto.

Descubre cómo el ajuste fino con LoRA y NEFTune potencia el rendimiento de DeepSeek-R1-8B en reconocimiento de entidades financieras, alcanzando un F1 de 0.912.

Descubre el marco unificado: RL, trading de alta frecuencia y teoría de juegos con análisis multimodal. Mejoras del 31% en predicción y 23% en carteras.

Descubre cómo las redes bayesianas y de Markov modelan la incertidumbre estructurada. Una guía intuitiva para entender estos modelos probabilísticos en IA.