
Información inducida por estructura para reenraizar búsqueda de Levin
Descubre cómo la información estructural permite reenraizar la búsqueda de árbol de Levin, logrando mayor escalabilidad y eficiencia en problemas complejos.
Descubre cómo la información estructural permite reenraizar la búsqueda de árbol de Levin, logrando mayor escalabilidad y eficiencia en problemas complejos.

Conoce PRISM, un marco basado en VLMs que cambia el diagnóstico interno por auditoría externa para neutralizar backdoors con tasa de éxito menor al 1%.
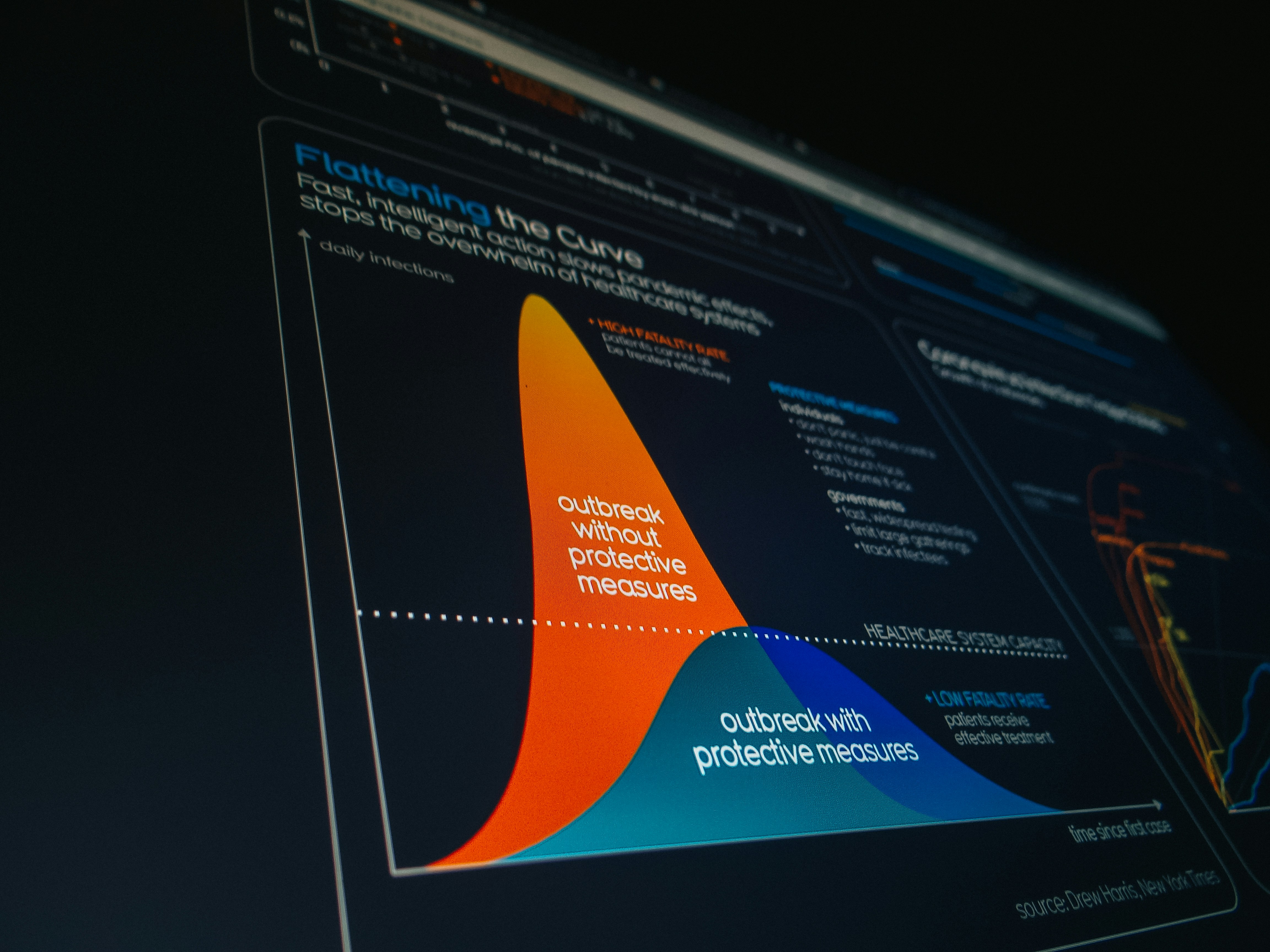
Descubre cómo el grokking en regresión ridge demuestra que la generalización tardía no es un fallo de deep learning. Aprende a controlarlo con hiperparámetros.
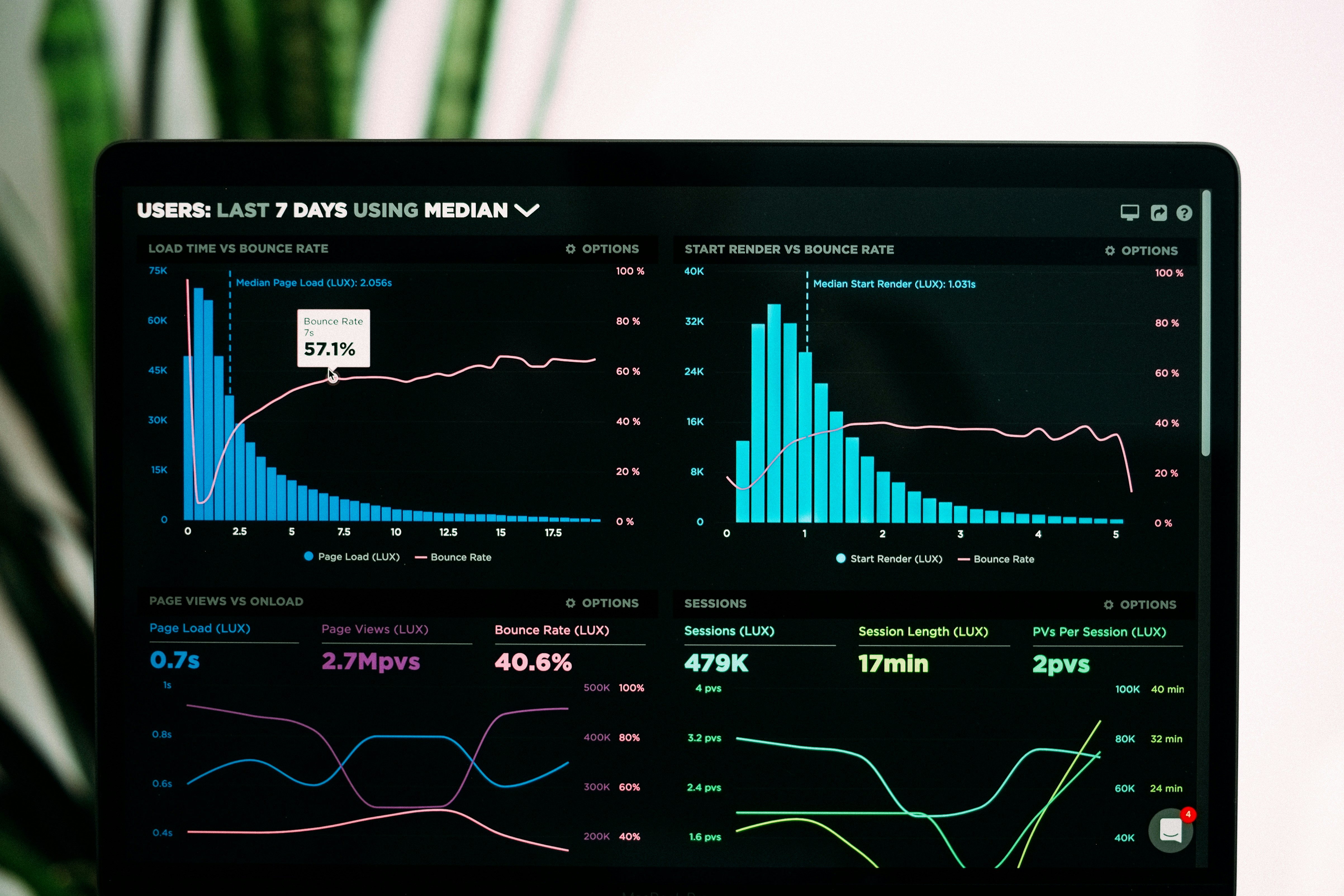
¿Más datos siempre mejoran el aprendizaje multitarea? Un nuevo estudio demuestra que no. Conoce los límites insuperables de la adaptación y el teorema de no-free-lunch.

Descubre cómo redes neuronales equivariantes identificables garantizan equivarianza por capas. Un hallazgo clave para entender simetrías en IA.

Descubre SVE: incertidumbre calibrada en modelos fundacionales con solo 1% de parámetros extra.

Optimiza el ajuste fino de modelos grandes con adaptadores Kronecker. Conoce CDKA, una nueva técnica que mejora la capacidad y eficiencia mediante el diseño estratégico de componentes.

¿Son realmente efectivos los modelos de lenguaje tabulares? Nuestra reevaluación de Tabula-8B muestra que la generalización se debe a artefactos de evaluación, no a aprendizaje real.

Descubre el aprendizaje supervisado como compresión con pérdida: análisis de bloque finito para generalización y complejidad de muestra.

Descubre cómo TACO comprime datasets tabulares en espacio latente, logrando hasta 94x más rapidez y 97% menos memoria sin perder rendimiento.
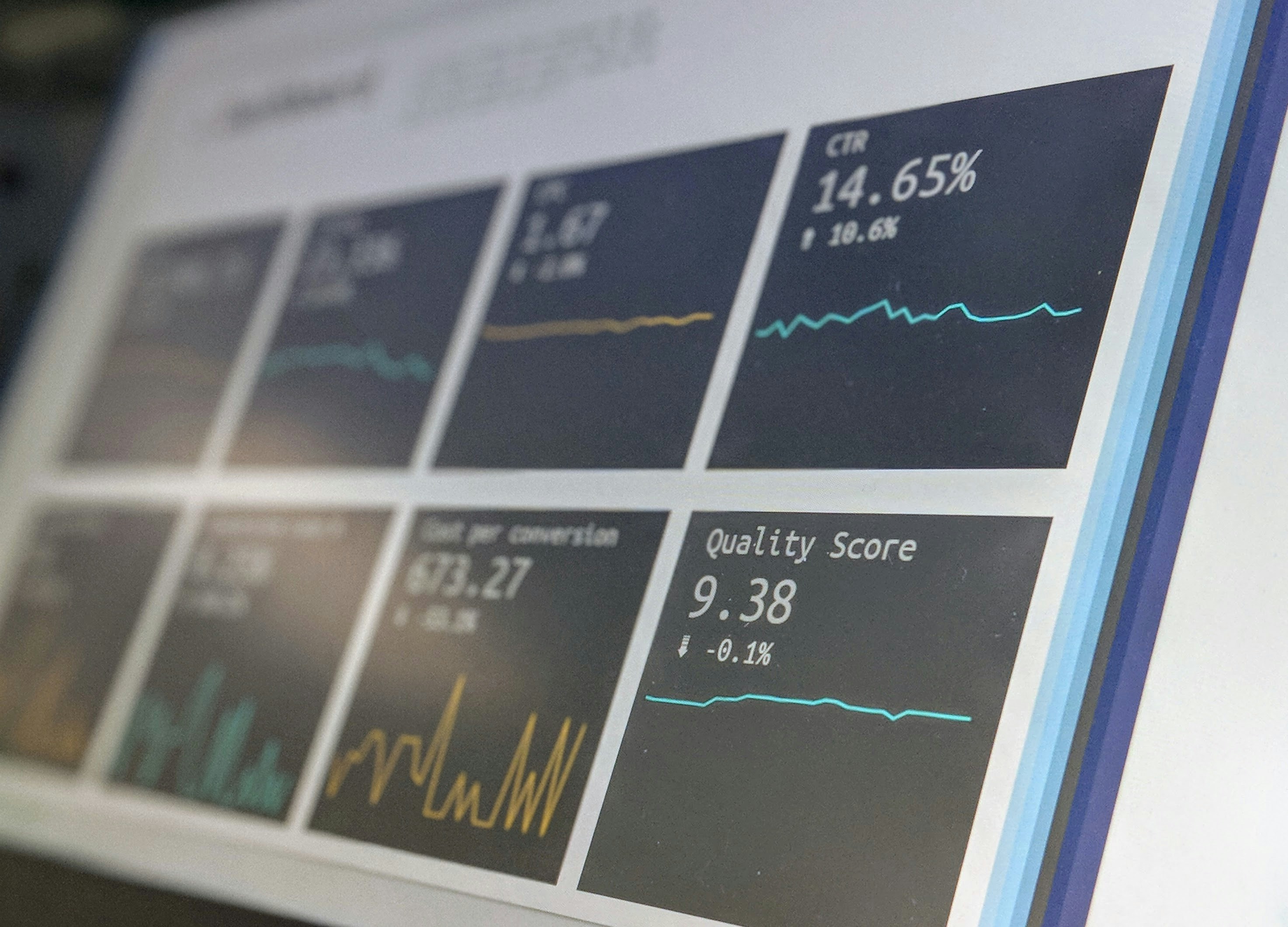
Logra decisiones justas en clasificación binaria con puntuaciones calibradas usando un algoritmo de post-procesamiento que garantiza suficiencia.

Descubre cómo L2G-Net revoluciona las GNN espectrales con factorizaciones de Cauchy, escalando a grafos grandes con pocos parámetros.

Descubre MENO: el nuevo marco que mejora operadores neurales con MeanFlow para predicciones precisas en sistemas dinámicos, con hasta 14x más rapidez que DDIM.

Aprende cómo la regresión local Fréchet predice curvas en variedades Riemannianas, aplicada al campo magnético terrestre con datos del satélite MAGSAT.

Descubre por qué los kernels cuánticos escalares limitan el potencial de la IA cuántica y cómo los kernels operador-valorados pueden revolucionar el aprendizaje estructurado.

Descubre cómo las redes neuronales simplécticas preservan la estructura hamiltoniana en modelos reducidos, logrando simulaciones precisas y estables a largo plazo.

Cómo los gradientes estocásticos convergen con parámetros nuisance. Ortogonalidad de Neyman y actualizaciones ortogonalizadas para optimización robusta.

Descubre cómo el aprendizaje espectral consciente del resultado mejora la regresión IV incluso con desalineación espectral.

Analizamos la propagación de errores en modelos de difusión con datos sintéticos. Primeras cotas inferiores de divergencia y regímenes de deriva.

Optimiza LLMs con GradMem: escribe contexto en memoria mediante descenso de gradiente en tiempo de prueba, reduciendo la necesidad de grandes cachés.