
Reward Hacking en Agentes de Lenguaje: Revisitando Gridworlds de Seguridad
Aprende cómo el reward hacking engaña a los agentes de lenguaje y por qué el RL no lo soluciona. Estudio basado en Gridworlds de seguridad.
Aprende cómo el reward hacking engaña a los agentes de lenguaje y por qué el RL no lo soluciona. Estudio basado en Gridworlds de seguridad.

Descubre cómo distinguir si la deriva en las evaluaciones de LLM se debe al sistema o al juez automático con un método de atribución válido en todo momento.

Descubre cómo la programación justa de tokens y la valoración privada de datos mejoran la QoS y la privacidad en redes agénticas multimodales.

Descubre cómo ARVRE combina recuperación agéntica y aprendizaje por refuerzo para generar problemas de física complejos, novedosos y solucionables.

Los benchmarks asumen que los estudiantes seguirán el andamiaje, pero en la práctica lo evaden. Descubre el desajuste entre teoría y realidad en tutores de IA.

STRIDE mejora el RLVR con estimación discriminativa: asigna créditos precisos a patrones estratégicos. ¡Optimiza el razonamiento de tu IA!

Auditoría revela que el 28.5% de tareas en RL de código son hackeables. Descubre cómo endurecerlas con un juez LLM.

Un estudio revela que los cachalotes tienen un doble nivel: ritmos de clics forman codas, y estas se combinan en secuencias. ¿Estructura similar al lenguaje?

RecourseBench: marco modular y reproducible para evaluar recursos algorítmicos. Integra 28 métodos con tests automáticos. ¡Prueba su interfaz web!

Descubre cómo el pensamiento visual con grounding mejora el razonamiento de modelos de IA, vinculando pensamientos a regiones de imagen para mayor precisión.

VibeThinker-3B demuestra que modelos pequeños pueden alcanzar rendimiento de vanguardia en razonamiento verificable, superando a sistemas mucho mayores.
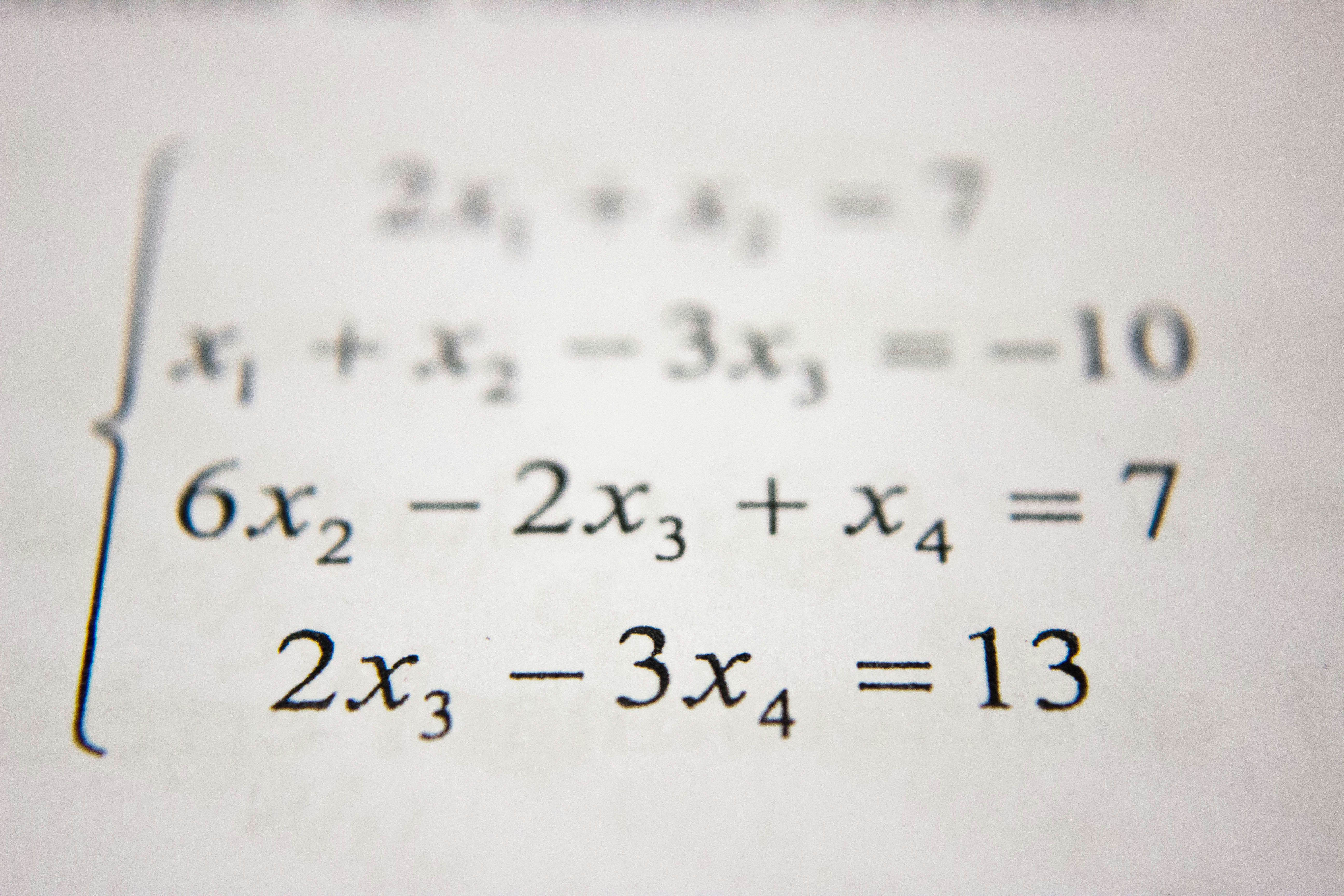
Descubre por qué los datos de alta recompensa dañan el razonamiento matemático en modelos pequeños y cómo la alineación de estilo mejora la destilación.

Descubre PAL-Bench, un benchmark controlado para reconstruir perfiles e identidades sociales a partir de álbumes personales con evidencia auditada. Ideal para

¿Cómo saber si las representaciones de un sensor son correctas? Descubre el método OQ-TSAE que preserva distinciones de escena y suprime variaciones molestas.
AdaSTORM revoluciona el razonamiento en grafos dinámicos: escala LLMs a miles de nodos con más del 90% de precisión sin herramientas externas.

Descubre cómo la inyección de guía por fase optimiza la recuperación de interrupciones en líneas de ensamblaje usando MAPPO recurrente.

Descubre cómo MHL usa LLMs para crear reglas clínicas transparentes y auditables, superando el desbalance y la evolución de datos en salud.

Descubre cómo la inyección de guía por fases mejora la recuperación de interrupciones en líneas de montaje usando MAPPO recurrente. Reduce tiempos anormales y
Descubre MHL, un marco basado en LLM que genera reglas de decisión clínicas interpretables y auditables, con rendimiento comparable a métodos estado del arte

MGIL aplica aprendizaje inductivo en grafos de modelo para mejorar la predicción de enlaces, logrando representaciones globales precisas.