
PolicyGuard: defensa adversarial en tiempo de prueba y por paso para RL
PolicyGuard defiende agentes de RL contra ataques backdoor en tiempo de prueba, usando procesos Gaussianos para detectar anomalías paso a paso. Resultados state-of-the-art.
PolicyGuard defiende agentes de RL contra ataques backdoor en tiempo de prueba, usando procesos Gaussianos para detectar anomalías paso a paso. Resultados state-of-the-art.

GRASP combina visión-lenguaje y planificación neuro-simbólica para agarre robótico con lenguaje natural. 73.3% de éxito sin entrenamiento. ¡Descúbrelo!
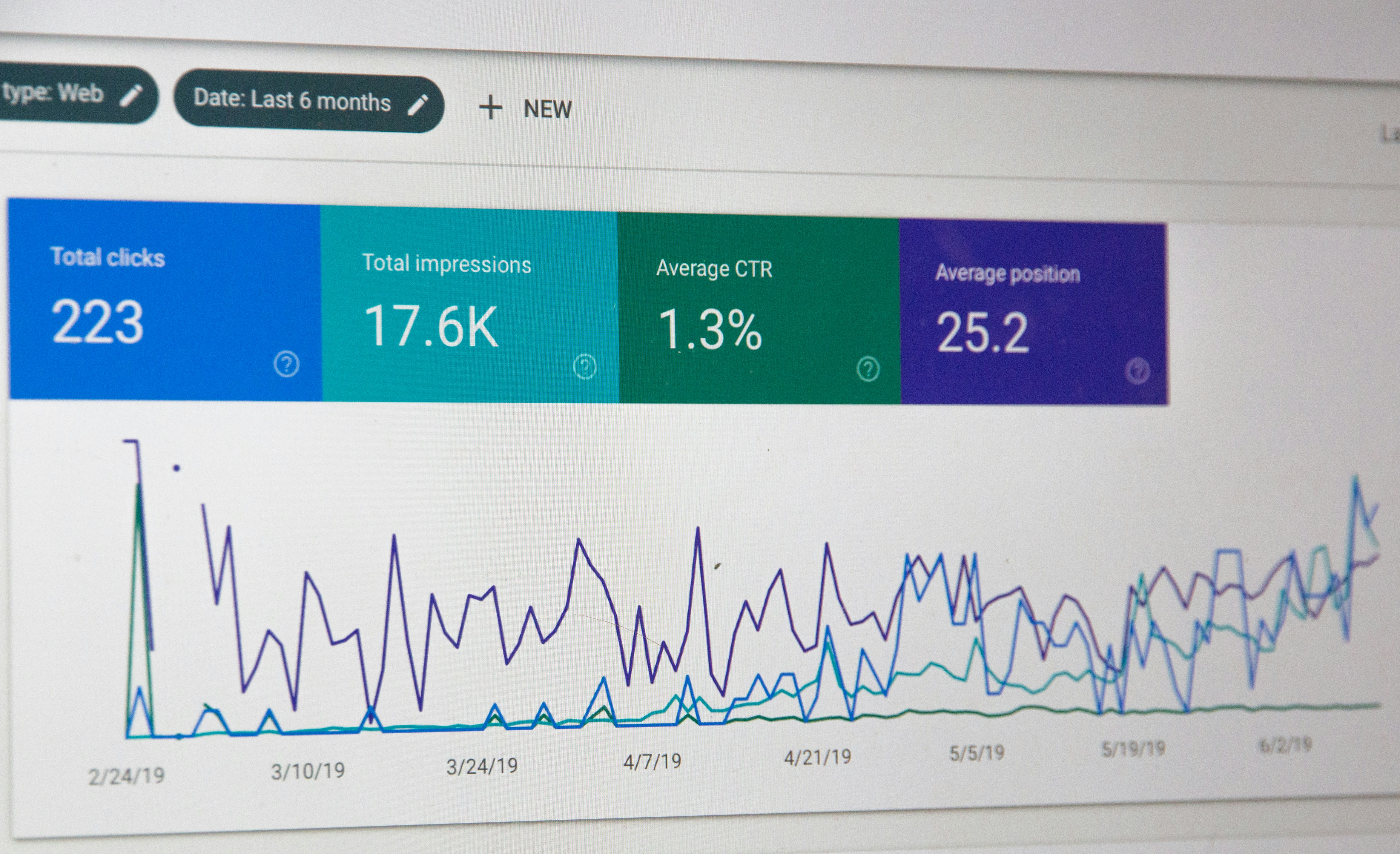
Descubre LoRA-Muon: optimiza fine-tuning con bajo rango, transfiere tasas de aprendizaje, supera líneas base densas. Eficiente en memoria.
Descubre Pipette: plataforma de simulación y aumento de datos para robótica en laboratorio húmedo. Mejora VLA de 44.1% a 74.7% con solo 30 demostraciones.

Aprendizaje automático analiza posturas ergonómicas en tiempo real con nubes de puntos 3D. Supera cámaras fijas y mejora seguridad laboral.

scLLM-DSC: un novedoso marco de clustering multimodal que aprovecha grandes modelos de lenguaje para mejorar la precisión en el análisis de células individuales.

Marco de machine learning para análisis en tiempo real de posturas ergonómicas usando nubes de puntos 3D. Clasificación personalizada para seguridad laboral.
CausalMoE, un modelo multimodal, revoluciona la detección causal de Granger usando expertos heterogéneos y patrones temporales, integrando LLMs y VLMs.

scLLM-DSC mejora el clustering de scRNA-seq integrando conocimiento de LLM y supera 11 métodos. Conoce este avance en bioinformática.

Descubre CausalMoE, el primer modelo fundacional multimodal que integra LLMs y VLMs para descubrimiento causal Granger preciso en series temporales complejas.
EA-WM verifica eventos en modelos de mundo para manipulación robótica a largo plazo. Mejora planificación y control con predicciones interpretables.

Descubre cómo TWLA, mediante cuantización post-entrenamiento, reduce el tamaño y acelera la inferencia de LLMs usando pesos ternarios y activaciones de 4 bits.

Descubre cómo la regulación emocional artificial mejora la clasificación de imágenes con deep learning, superando métodos previos en datasets CIFAR.

Descubre cómo la regulación emocional artificial supera modelos de deep learning en clasificación de imágenes, logrando el nuevo estado del arte en CIFAR.

El post-entrenamiento con RL activa selección y mejora de estrategias. Experimentos con Qwen-2.5 revelan mecanismos clave para escalar razonamiento.

Descubre cómo IVT enseña a modelos visión-lenguaje a corregir sus errores espaciales: precisión 82% y degradación 5x menor.

Robot humanoide se distingue de otros usando percepción propioceptiva-visual sin etiquetas. Crea modelo corporal 3D para navegación y evitar colisiones.

Descubre cómo PULSE, un clasificador bioacústico semisupervisado, supera a modelos generales en la identificación de cantos de ortópteros, mejorando el monitoreo ecológico.

Mejora el reconocimiento de voz disártrica con aprendizaje federado personalizado. Descubre estrategias que reducen el WER hasta un 4.73% relativo. ¡Protege la privacidad!
Descubre cómo ESE acelera pronósticos hasta 70x. Preciso, escalable y robusto para economía, salud, y más.