
Seguridad en LLMs caja negra: Alineación mediante optimización restringida
Alinea LLMs de caja negra en inferencia usando optimización restringida y teoría de juegos para balancear seguridad y utilidad.
Alinea LLMs de caja negra en inferencia usando optimización restringida y teoría de juegos para balancear seguridad y utilidad.

FIRM alinea LLMs con múltiples objetivos eficientemente y en privado usando aprendizaje federado. Mejora equilibrio entre utilidad e inocuidad.

Descubre cómo la alineación semántica revoluciona la interpretabilidad en modelos de series temporales profundos, mejorando la confianza y la toma de decisiones.

Descubre cómo NeVA alinea valores en LLMs con edición neuronal, evitando fugas indeseadas. Control fino sin reentrenamiento.

MASCOT mejora consistencia y diálogo en agentes multi-sistema, evitando redundancias. Descubre su optimización bi-nivel para compañeros socio-colaborativos.
La alineación entre texto y audio en modelos omni permite transferir ataques de jailbreak, aumentando riesgos de seguridad. Descubre cómo.

Aprende cómo la distribución de fuente condicional optimizada en Flow Matching acelera la convergencia hasta 3x y mejora la calidad en generación texto-imagen.

Descubre los primeros pasos para modernizar aplicaciones legacy: alinear objetivos, mapear procesos y elegir tecnología. Reduce costos y riesgos con Q2BSTUDIO.

Descubre cómo COLLIE guía el aprendizaje de habilidades diversas y seguras usando un espacio latente semántico, sin modelos extra y con feedback humano mínimo.
Descubre cómo los LLM muestran una honestidad excesiva incluso cuando hay conflicto de intereses, según un nuevo benchmark basado en teoría de juegos.

Descubre RDA, un agente basado en VLM que diseña recompensas semánticas para robots. Logra políticas alineadas con instrucciones humanas en manipulación.

G2LoRA: marco que combina gradiente ortogonal y aprendizaje continuo para evitar el olvido catastrófico en grafos textuales. ¡Pruébalo!
FedSAP cierra la brecha de alineación-madurez en aprendizaje federado con prototipos, logrando hasta 4 puntos en datos no-IID y se extiende a semi-supervisado.

Descubre cómo DrPO optimiza modelos generativos de un paso sin necesidad de gradientes de recompensa, mejorando la alineación y reduciendo el costo computacional.
Los modelos de recompensa en IA tienen sesgos. La recompensa mecánica los mitiga con pocos datos. Optimiza la alineación de modelos de lenguaje.

Un estudio analiza la alineación multimodal en SNIP para regresión simbólica. Descubre por qué no mejora durante la optimización y qué implica para el futuro.

RAUL: un marco multiobjetivo que elimina datos de entrenamiento sin perder precisión. Optimiza olvido y retención con alineación de referencia.

El Protocolo Consilium usa BFT para deliberación multi-IA: las personas cognitivas importan más que el modelo. Sesgos RLHF revelados. Costo: $217.
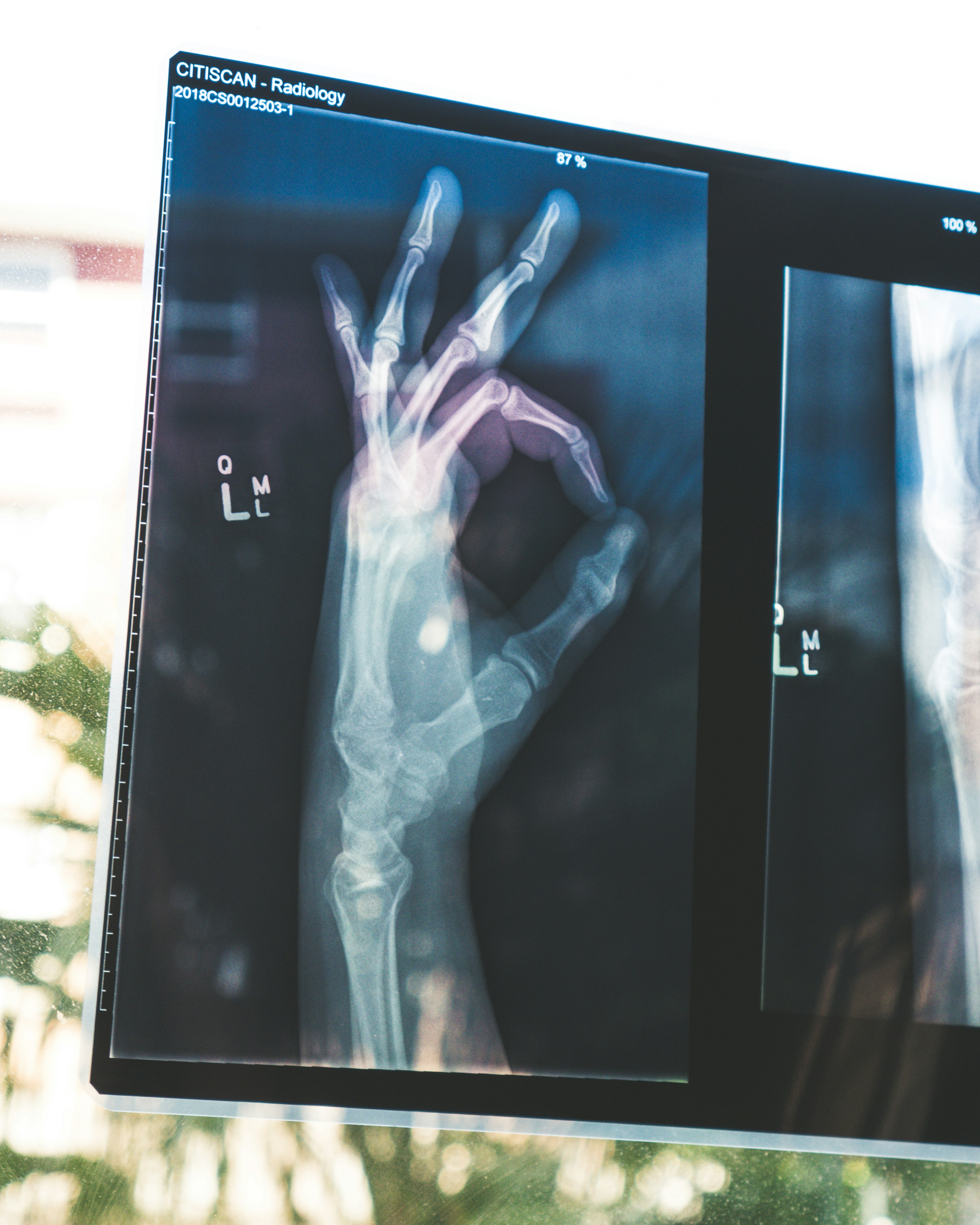
Los modelos de IA clínica pueden reidentificar pacientes al vincular radiografías con informes. Descubre cómo la privacidad diferencial reduce este riesgo.

Descubre cómo AdvCL reutiliza perturbaciones adversarias para estabilizar el aprendizaje continuo en LLMs, mejorando robustez y transferencia sin olvido.