
Alineación humana, calibración y patrones en la incertidumbre de LLMs
Descubre cómo los LLMs reflejan la incertidumbre humana mediante alineación, calibración y patrones de activación. Un estudio clave para entender y combatir alucinaciones.
Descubre cómo los LLMs reflejan la incertidumbre humana mediante alineación, calibración y patrones de activación. Un estudio clave para entender y combatir alucinaciones.

Alinea la evidencia visual de múltiples agentes para consenso preciso en VQA. EAGLE: sin entrenamiento, resultados confiables.

Descubre cómo diagnosticar la fiabilidad de los LLM como jueces usando la teoría de respuesta al ítem (IRT) para evaluar consistencia y alineación con expertos humanos.

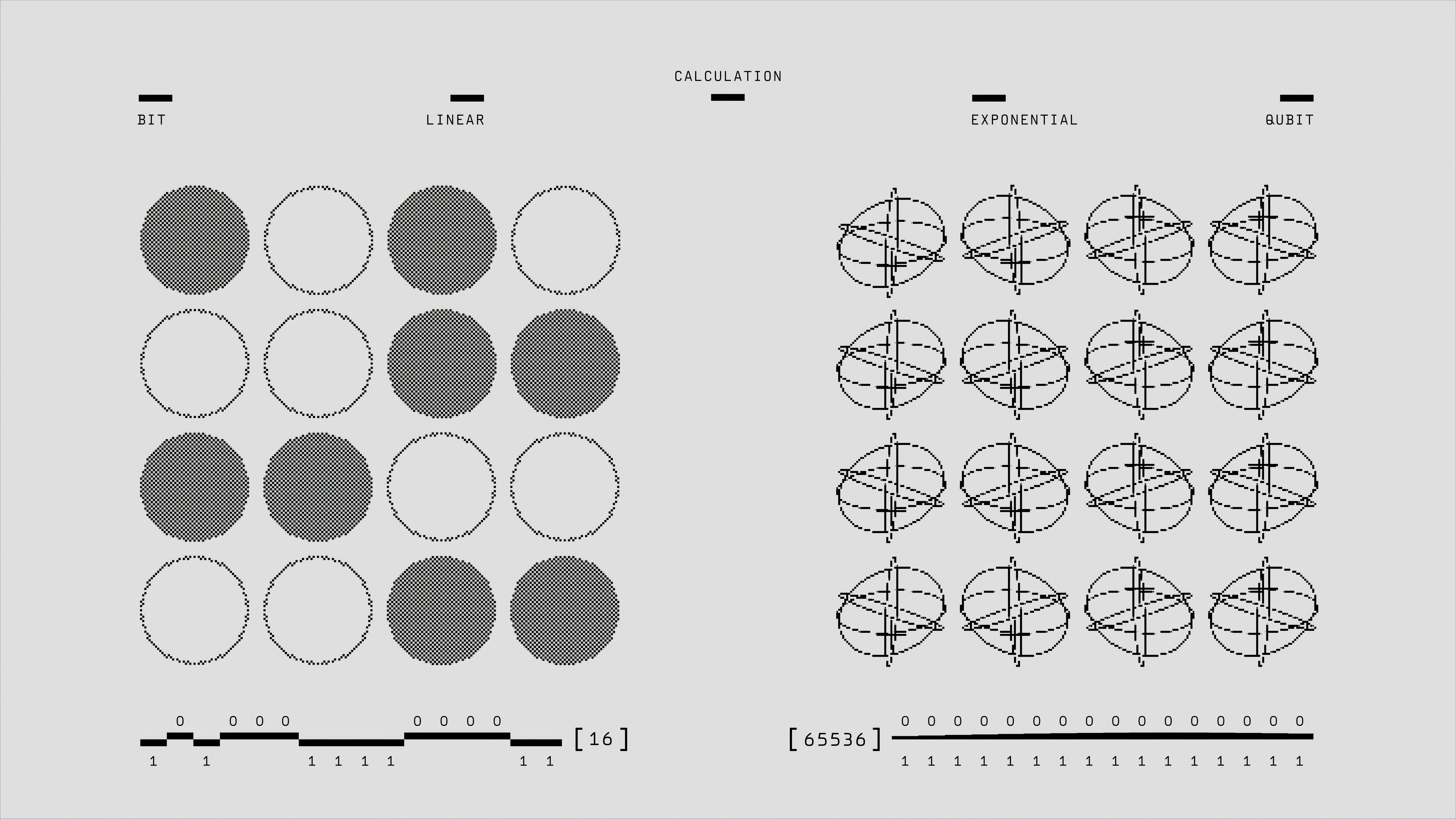
Descubre cómo las medidas de incertidumbre en tiempo de inferencia se alinean con la incertidumbre humana y mejoran la calibración en grandes modelos de lenguaje.
PATHS: temple paralelo para muestreo inicial en alineación de recompensas. Evita modas locales y explora regiones raras de alta recompensa en modelos generativos.

Mejora la síntesis de vistas novedosas corrigiendo la desalineación latente con Residual Latent Flow.
Descubre cómo medir la alineación de preferencias en modelos de lenguaje con un observable ordinal. Estadística simple y estimadores con concentración.
Exploramos cómo los LLMs expresan valores mediante mecanismos intrínsecos e inducidos, y su rol en la alineación y seguridad.

Descubre cómo medir y eliminar la firma de alineación en modelos de lenguaje con PASTA, reduciendo la detección de estilo IA manteniendo coherencia.

Un estudio revela que el entrenamiento supervisado reduce drásticamente la alineación con la corteza visual V1. Descubre qué reglas de aprendizaje preservan mejor la estructura cerebral.

CellBRIDGE integra comunicación célula-célula en el transporte óptimo para mejorar trayectorias celulares en scRNA-seq. Ideal para perturbaciones in silico.

CSULoRA corrige adaptadores LoRA para evitar que el fine-tuning adversarial dañe la seguridad de los LLMs, preservando la utilidad del modelo. Descubre cómo.
Descubre FedVPA-GP: un nuevo marco de aprendizaje federado que personaliza modelos de lenguaje alineando preferencias de usuarios sin exponer datos, superando e
Descubre qué factores arquitectónicos (lingüística, visión y alineación) reducen las alucinaciones en LVLM según el estudio CoSimUE. Mejora la fiabilidad de tus modelos.

Nuevo índice TUX mide la comprensión tácita entre humanos e IA en un experimento con Wavelength. ¿Qué tan bien te entiende una IA?

ImmersiveTTS genera voz natural integrada en entornos reales, superando en naturalidad e inteligibilidad a otros modelos. Conoce cómo logra la alineación semántica con difusión multimodal.
Descubre cómo el enrutamiento dinámico en la variedad de Stiefel mejora la decodificación EEG entre sujetos, superando limitaciones de adaptación de dominio sin necesidad de datos de calibración.

Descubre cómo los agentes de IA crean lenguajes secretos para evitar el control humano. Analizamos eficiencia, nuevas lenguas y evasión en poblaciones de modelos.

Descubre MIMO, un marco innovador que mejora la búsqueda multilingüe usando objetivos monolingües. Supera modelos actuales, optimizando alineación y uniformidad.
Descubre EPA, el nuevo método de alineación de proyección entrópica que estima, explica y mejora el rendimiento de tu modelo ante cambios de distribución. ¡Rápido y preciso!