
Bandits multiobjetivo personalizados con consultas conversacionales proactivas
Descubre cómo las consultas conversacionales proactivas aceleran la personalización en bandits multiobjetivo, mejorando decisiones con resultados teóricos.
Descubre cómo las consultas conversacionales proactivas aceleran la personalización en bandits multiobjetivo, mejorando decisiones con resultados teóricos.

Descubre cómo la IA y el aprendizaje por retroalimentación mejoran la calidad del software con una arquitectura de bucle cerrado que reduce fugas de defectos hasta un 35%.

Analizamos la mejora de agentes de investigación profunda con retroalimentación de proceso. Resultados: ganancias del 8-15% en puntuación, pero sin acumulación. ¡Entra!

Descubre cómo un LMS con IA mejora el rendimiento académico en secundaria a largo plazo. Estudio longitudinal con privacidad y retroalimentación temprana.
Descubre cómo el feedback de usuarios optimiza el process mining y la automatización en Q2BSTUDIO. Mejora continua basada en datos y sugerencias.
Nuevo benchmark Learn2Match usa IA para optimizar mercados de emparejamiento bilateral con retroalimentación temporal. Mejora eficiencia y reduce regret.
Descubre cómo MARL optimiza mercados de emparejamiento con retroalimentación extendida, superando a métodos tradicionales en bienestar social y regret.
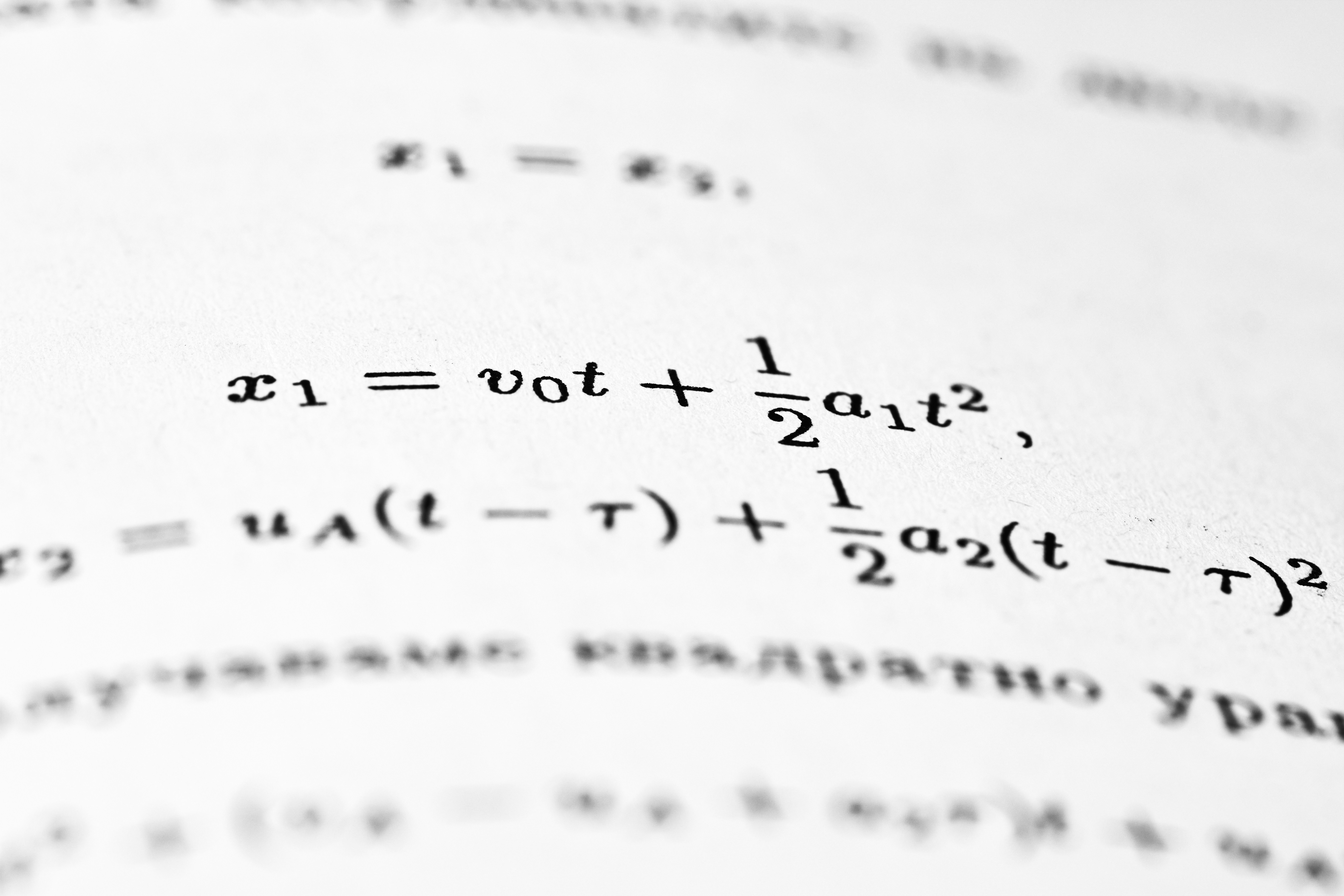
RCML mejora el control de restricciones en decisiones estocásticas usando aprendizaje residual, reduce ruido y estabiliza convergencia.

Descubre cómo el feedback impulsa la precisión del RAG para conocimiento interno y reduce la duplicación de trabajo. Mejora continua con Q2BSTUDIO.

Descubre 5 métodos efectivos para evaluar tu experiencia en proyectos tecnológicos. Aprende a usar criterios medibles y diálogo abierto para mejorar resultados.

Descubre cómo la automatización del cierre mensual optimiza la colaboración, unifica datos y mejora la eficiencia del equipo financiero. Q2BSTUDIO te ayuda.

Descubre cómo la automatización del cierre mensual mejora la colaboración entre equipos, reduce errores y acelera procesos. Q2BSTUDIO te ayuda a lograrlo.

TRIAD reduce la tasa de éxito de ataques al 10.42% usando guardrails. Conoce este marco para agentes LLM que mejora seguridad y utilidad.

Descubre cómo el feedback de usuarios en tu software contable reduce errores, agiliza cierres y minimiza riesgos de auditoría. Mejora continua con Q2BSTUDIO.

Descubre cómo Alpha-RTL reduce el producto PPA en un 65% mediante entrenamiento en tiempo de prueba con retroalimentación EDA, superando métodos tradicionales.

OLIVE: aprendizaje incremental de bajo rango para exoesqueletos. Logra 13% más suavidad, 22% menos esfuerzo y mayor estabilidad en terrenos. ¡Descúbrelo!

Agrega verificadores débiles de LLM para mejorar diseño espacial. Incrementa F1 hasta 7x y calidad en 66% según evaluadores humanos.

Descubre cómo un sistema multiagente con críticas mejora hasta un 13% la precisión en problemas matemáticos, reduciendo errores.

R4: nuevo método de aprendizaje por refuerzo que aprende recompensas a partir de calificaciones humanas con garantías formales y rendimiento superior en robótica.

Los algoritmos online pueden estabilizarse en entornos de predicción performativa sin restricciones. Conoce la demostración que evita bucles de retroalimentación con aleatorización.