
Aprendizaje de un optimizador de orden cero para LLMs
Descubre cómo ZO-Finetuner optimiza el ajuste de LLMs sin retropropagación, reduciendo el uso de memoria y mejorando el rendimiento en múltiples tareas.
Descubre cómo ZO-Finetuner optimiza el ajuste de LLMs sin retropropagación, reduciendo el uso de memoria y mejorando el rendimiento en múltiples tareas.

Descubre cómo restaurar el rápido decaimiento de valores singulares mejora la eficiencia del ajuste fino privado de LLMs con DP-SGD, sin comprometer privacidad.

Descubre Go-UT-Bench, dataset para ajustar LLMs que mejora tests unitarios en Go. Modelos ajustados superan en más del 75% a los base. ¡Optimiza!
Descubre cómo los kernels invariantes de árbol garantizan inferencia determinista con resultados bit a bit idénticos, eliminando el desajuste entre entrenamiento e inferencia en LLMs.

Un experimento con cosmología histórica revela cómo la adaptación de dominio cambia los marcos explicativos en modelos de lenguaje.

Descubre cómo los LLMs negocian en simulaciones de compra-venta. ¿Son honestos o aprovechan la asimetría de información? Análisis de su credulidad y rendimiento.
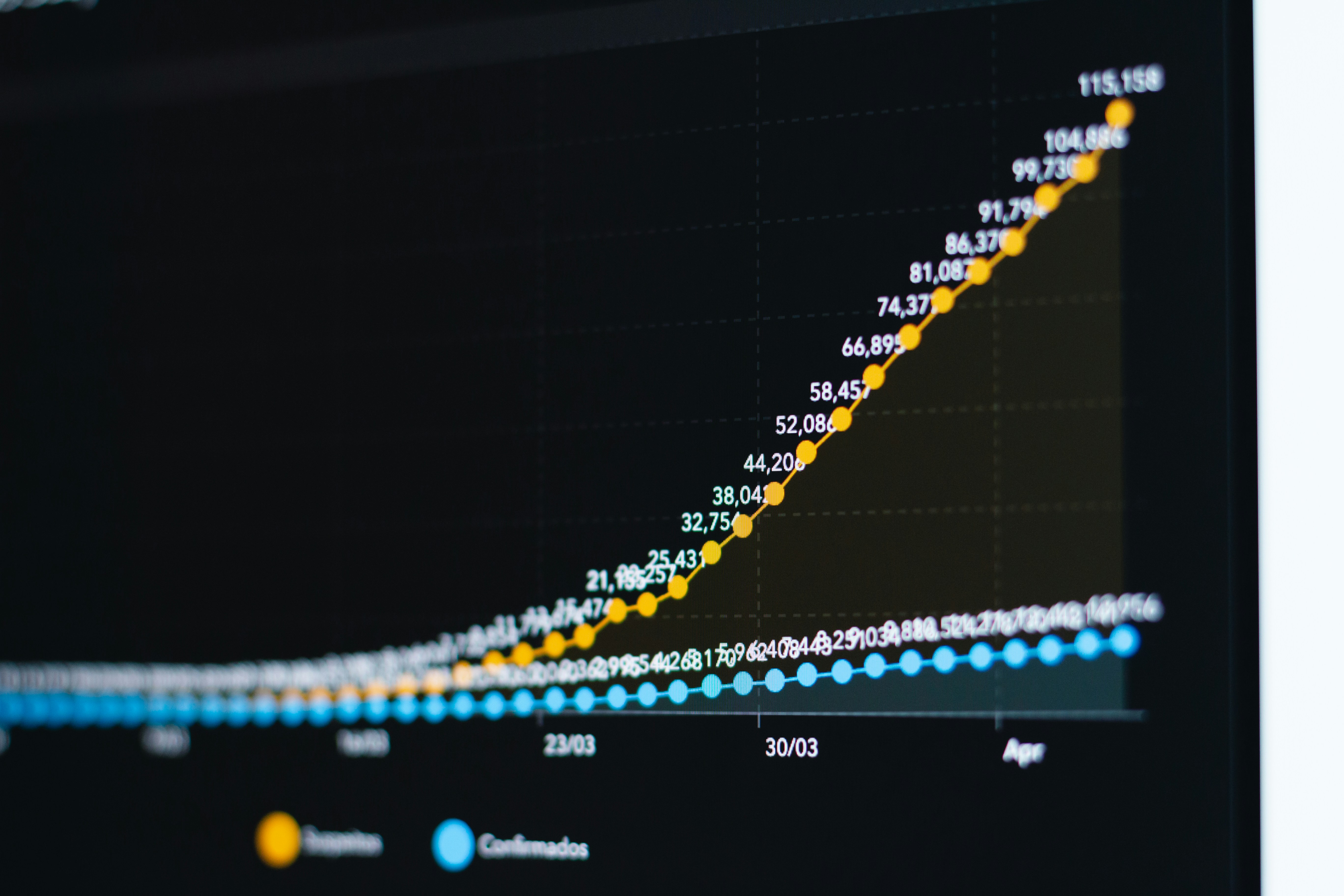
Estudio revela que MDLMs descifran entidades primero en generación texto-gráfico. SFT puede fallar, pero decodificación lambda recupera +9.4 BLEU.
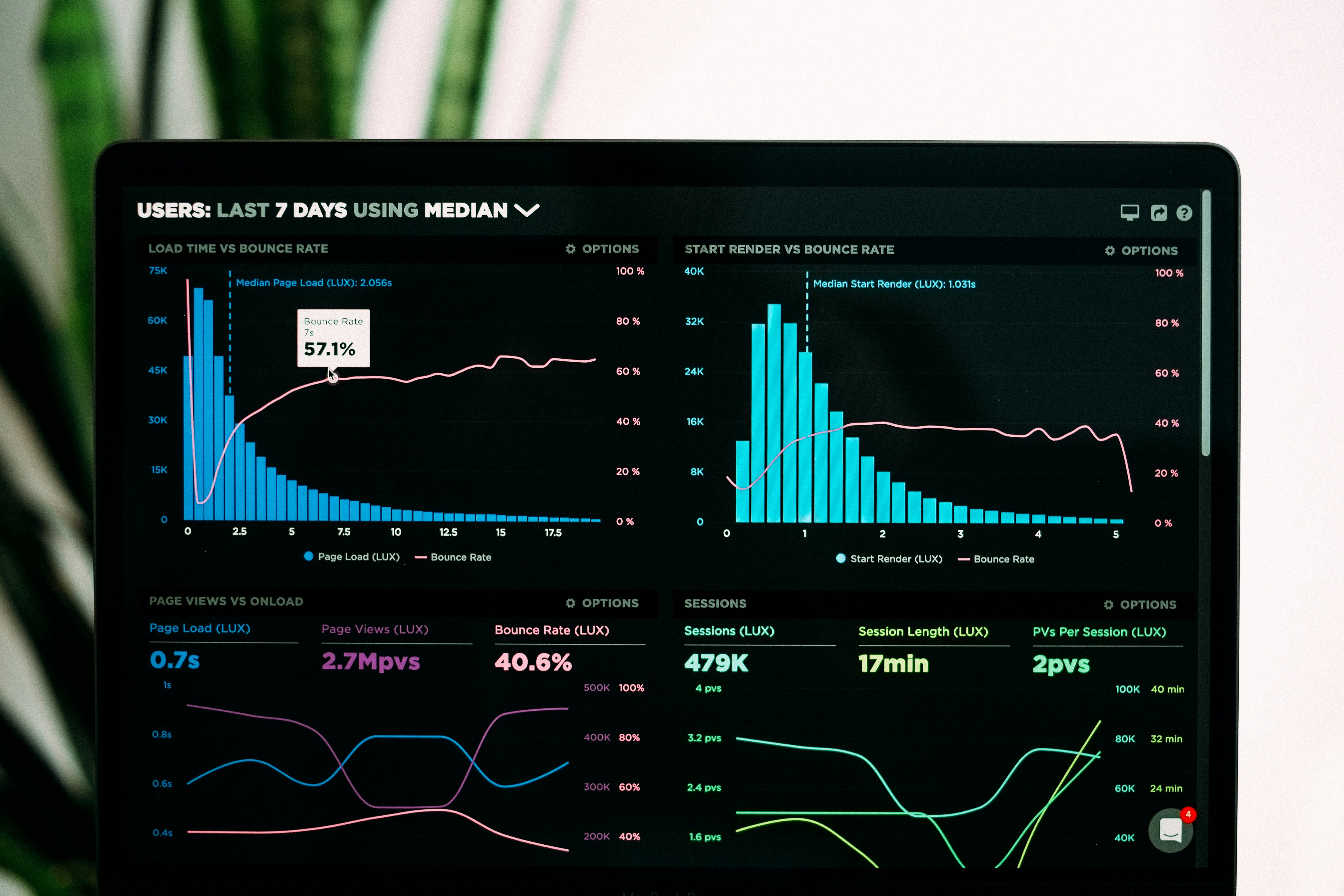
Descubre cómo un nuevo enfoque unifica y optimiza la valoración de datos usando decisiones secuenciales, mejorando la selección en LLM y benchmarks clásicos.

Mejora la toma de decisiones de los LLMs con Iterative RMFT: un método que minimiza el arrepentimiento y optimiza el equilibrio exploración-explotación.

Descubre PRISM, un método que selecciona datos de instrucción visual sin entrenamiento, reduciendo costes y mejorando el rendimiento de modelos multimodales.

Descubre cómo el sobreajuste provoca fallos en PINNs y cómo la regularización y el doble backpropagation permiten resolver ecuaciones con menos puntos de colocación.

Descubre CAM, un método no supervisado de difusión para optimización combinatoria que supera soluciones supervisadas. Resultados competitivos sin datos etiquetados.
Descubre cómo los portafolios de recuperadores optimizan RAG: selección automática de múltiples recuperadores para mejorar precisión y reducir latencia en QA.

DRIFT optimiza modelos de lenguaje en múltiples turnos con eficiencia de SFT y rendimiento de RL. Descubre cómo.
Acelera tu fine-tuning con BaLoRA: elimina invariancia de parámetros para convergencia más rápida y mejor rendimiento.

Descubre cómo un mayor weight decay durante el preentrenamiento puede mejorar la plasticidad de los LLM, generando mejor rendimiento tras el fine-tuning.

REAL: nuevo método de RL con regresión que mejora la evaluación de LLMs. Aumenta correlación hasta +18. Ideal para desarrolladores de IA.
Descubre cómo el algoritmo CFO equilibra recompensa y restricciones en el diseño molecular mediante ajuste fino secuencial. Resultados prometedores.

El fine-tuning reorganiza la incertidumbre en modelos de lenguaje, mejorando la transmisión de información. Descubre la métrica Canopy Entropy.

<meta content=Descubre 6 ajustes esenciales para optimizar la transmisión de Jellyfin en Android y mejorar tu experiencia multimedia sin interrupciones.>