
Monitoreo Constitucional de Caja Negra para Engaños en Agentes LLM
Descubre cómo los monitores constitucionales de caja negra detectan engaños en agentes LLM usando datos sintéticos. Resultados sobre generalización y límites.
Descubre cómo los monitores constitucionales de caja negra detectan engaños en agentes LLM usando datos sintéticos. Resultados sobre generalización y límites.

HALO estabiliza aprendizaje descentralizado en colaboración humano-robot mediante optimización de Lyapunov, mejorando generalización y robustez en casos extremos.

Descubre cómo el análisis con conciencia del repositorio reduce drásticamente los falsos positivos en la detección de malware en skills de agentes de IA. Estudio con más de 238,000 skills.

Aprende cómo los LLMs mejoran el diseño de recompensas en RL cooperativo multiagente, logrando mayor rendimiento en Overcooked.
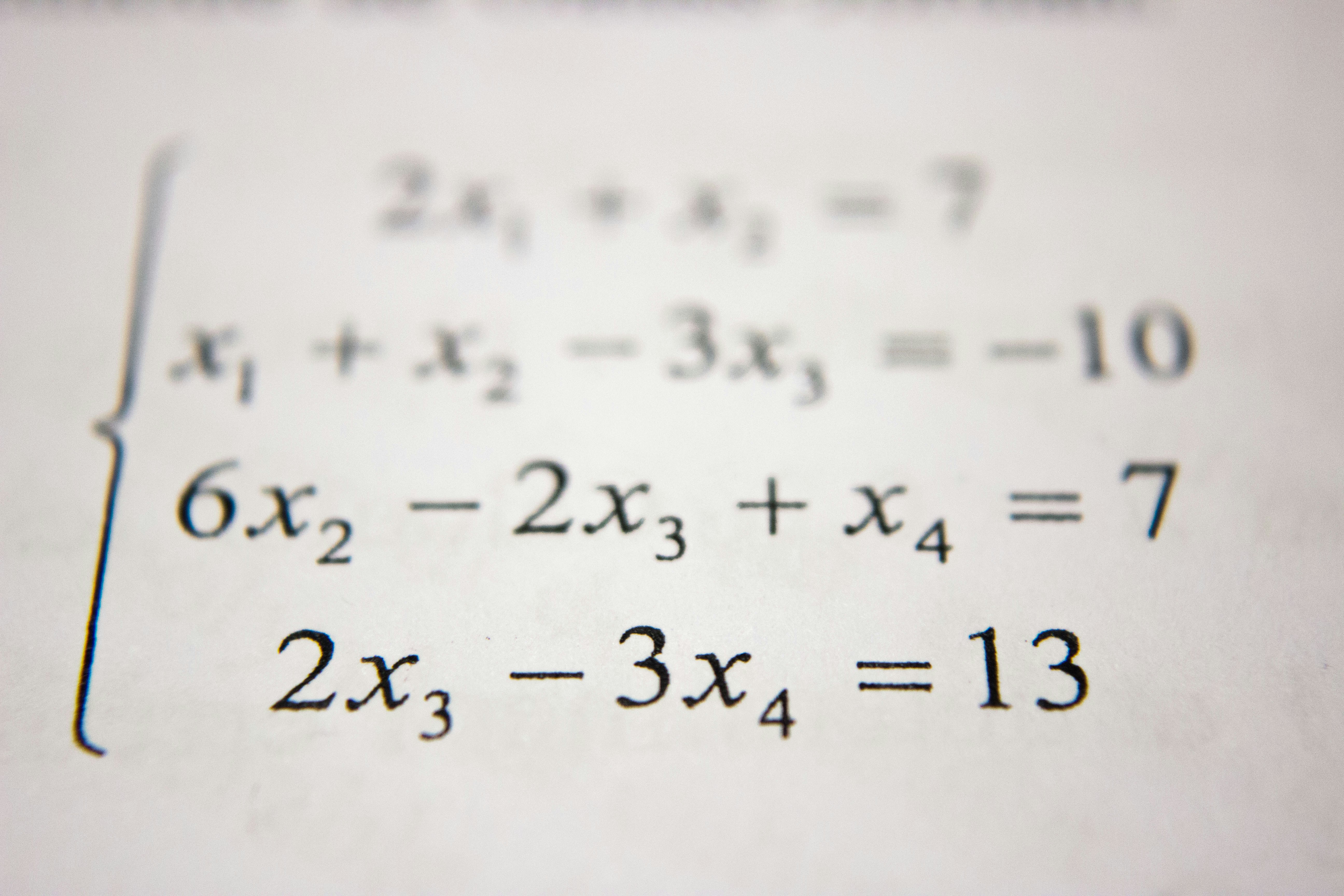
Descubre cómo un marco de IA resuelve problemas matemáticos complejos combinando razonamiento informal y verificación formal en Lean 4, todo sin intervención humana.

Descubre ContextSim: un marco de simulación con agentes LLM que integra tiempo, ubicación y necesidades para evaluar sistemas de recomendación con mayor precisi

¿Tu agente de voz falla en producción? Descubre las 7 mejores plataformas de testing de audio, simulación y observabilidad. Elige la correcta.

Developer Farm obtiene 67.56 en Prueba de Utilidad con una arquitectura IA honesta que evita la Ley de Goodhart. Descubre cómo separan capas y reducen costos.

¿Confías en el resumen de tu agente de IA? Descubre por qué necesitas paquetes de evidencia para auditar cambios reales en el código.

Descubre cómo reducir el desperdicio de tokens en sistemas de IA en producción. Aprende a optimizar costos, prompts y arquitecturas para ahorrar dinero.

Descubre cómo un archivo llms.txt evita que la IA genere Apex obsoleto en Salesforce. Pruebas con Opus, Sonnet y ChatGPT muestran la diferencia.

Descubre por qué nadie instala tu servidor MCP y cómo solucionarlo. El verdadero desafío: la adopción mental. Aprende a convertir instalación en uso real.

Descubre Memory OS, un stack de memoria de código abierto con 6 capas que añade vectores, hechos y wiki auto-curativa sobre Hermes Agent. Totalmente local.

Descubre el protocolo de curación deliberativa que logra 0.826 de precisión bajo estrés, degradándose 3 veces más lento que el voto mayoritario.
ATOM: marco multiagente que coordina agentes en un árbol para optimizar moléculas multiobjetivo. Mejora Pareto en diseño de fármacos. ¡Descúbrelo!
Claude Opus 4.8 de Anthropic ya en Microsoft Foundry. Potencia desarrollo, agentes y análisis empresarial con razonamiento profundo.

En KubeCon Europa, expertos de AWS, Google y Microsoft revelan las claves para lograr IA lista para producción: plataforma madura, seguridad y contribución activa.

AgentRedBench: benchmark dinámico que evalúa seguridad de agentes LLM en integraciones SaaS. AgentRedGuard reduce ataques exitosos del 69.9% al 2.4%.

Descubre SeClaw, un framework que sintetiza tareas de seguridad para evaluar agentes LLM autónomos. Evaluación reproducible y basada en trayectorias.

Un estudio revela que el uso de herramientas en agentes multimodales no siempre mejora su rendimiento. Descubre los sorprendentes resultados.