
Adaptación de dominio con un único embedding visión-lenguaje
Nuevo método de adaptación de dominio con un embedding visión-lenguaje para conducción autónoma sin datos objetivo, superando condiciones adversas.
Nuevo método de adaptación de dominio con un embedding visión-lenguaje para conducción autónoma sin datos objetivo, superando condiciones adversas.

NestRL optimiza la colaboración humano-IA mediante entrenamiento anidado, logrando mayor adaptabilidad y rendimiento frente a métodos tradicionales en Overcooked.

El marco LeARN aprende funciones base mediante meta-aprendizaje, adaptándose a dinámicas no lineales y superando las limitaciones de SINDy.
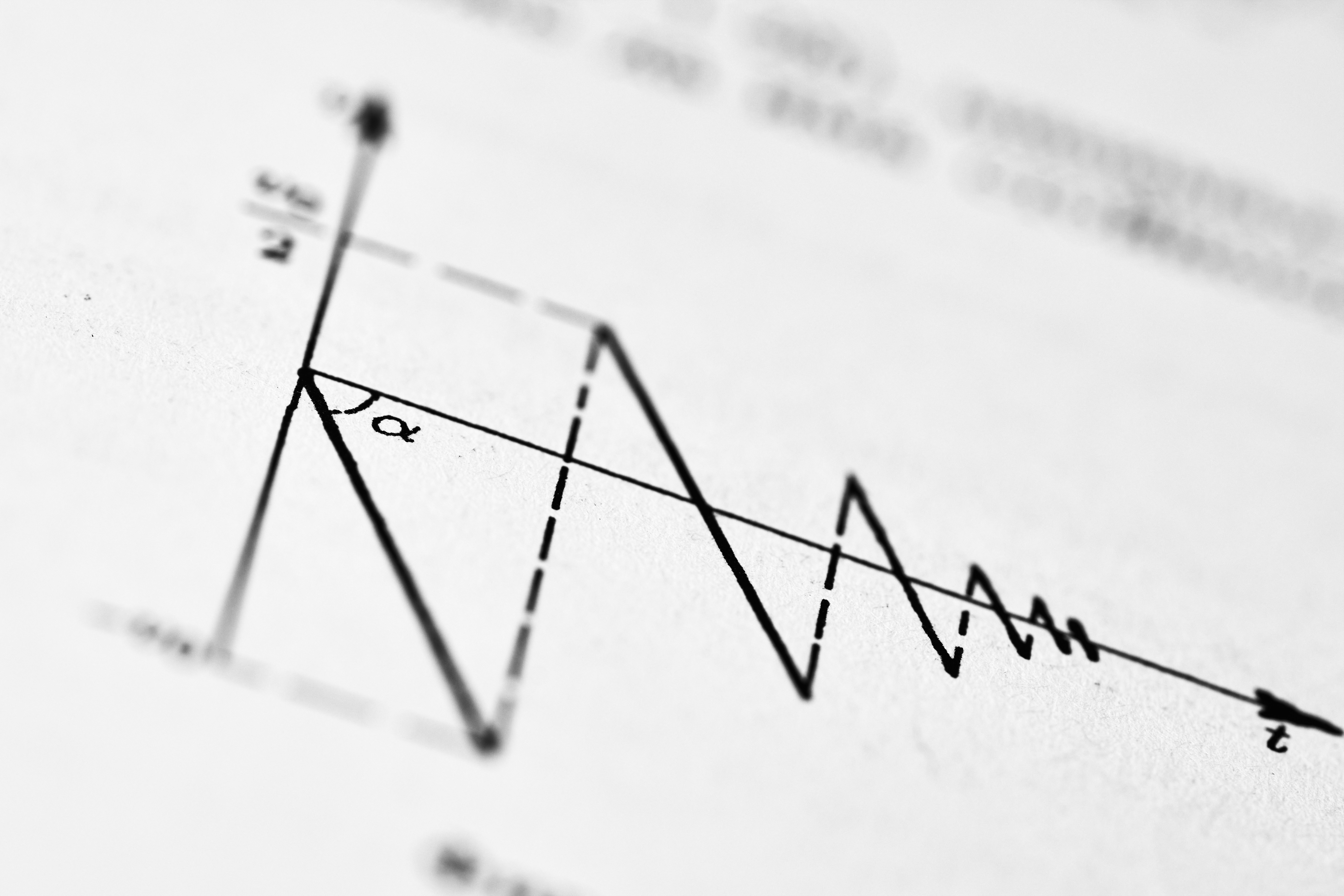
Descubre RefLoRA, una nueva técnica de fine-tuning que acelera la convergencia y mejora el rendimiento de modelos grandes con mínimo costo computacional.
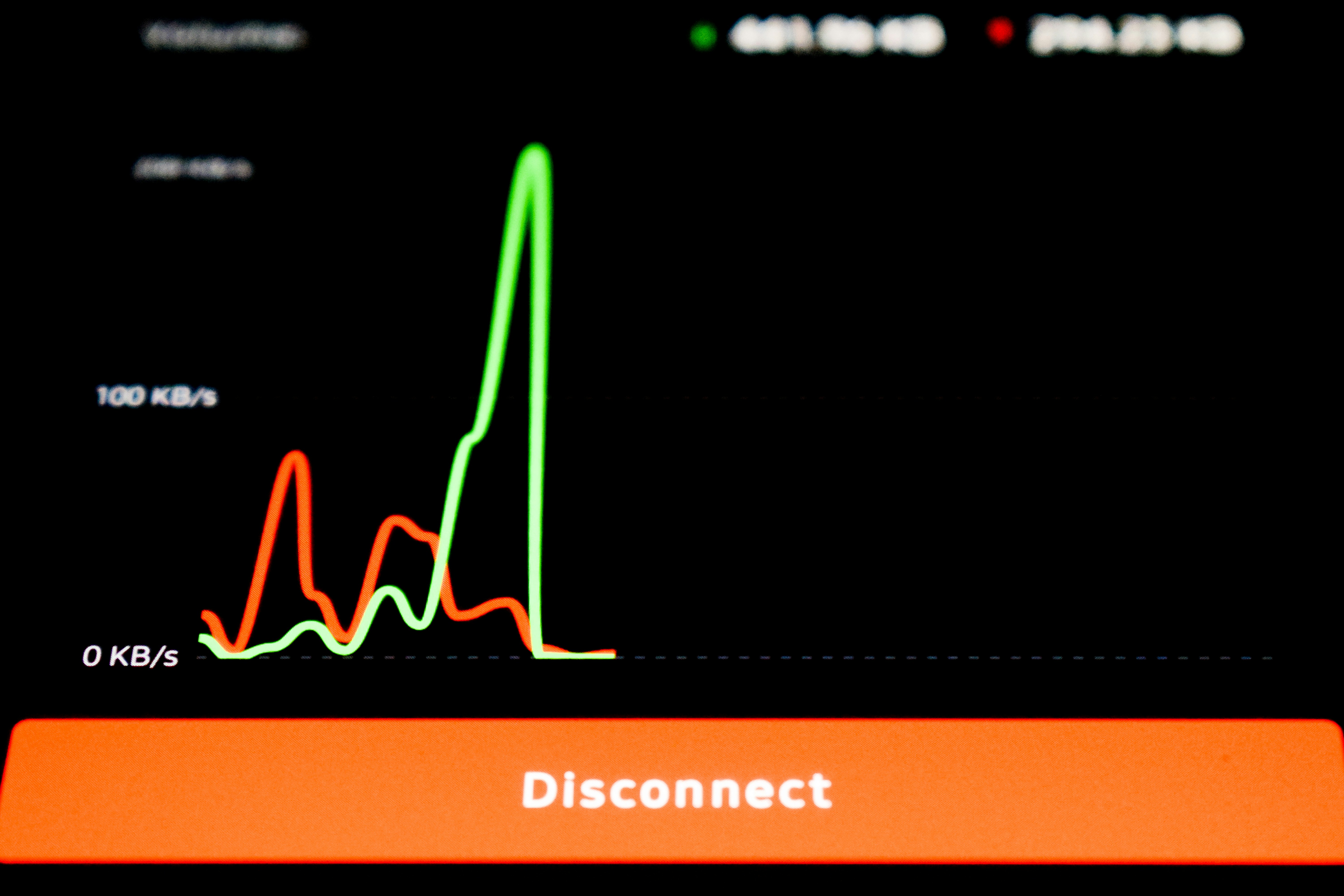
Descubre cómo Tempora evalúa la adaptación en tiempo de prueba bajo presión temporal. Conoce métricas para elegir el mejor método según latencia y precisión.

El fine-tuning secuencial con LoRA vence a métodos CRL complejos en modelos VLA: alta plasticidad, sin olvido catastrófico.

Nueva técnica de aprendizaje off-policy con zero-shot adapta políticas óptimas sin reentrenamiento, usando sucesores y densidades estacionarias. Benchmark en ExoRL y OGBench.

naPINN recupera leyes físicas de mediciones con ruido y outliers sin conocer la distribución del ruido. Ideal para datos corruptos.

Descubre cómo la adaptación de ruido semi-supervisada (SSNA) utiliza ruido sintético para mejorar la generalización de modelos de aprendizaje automático. ¡Optimiza tu rendimiento!

GPTQ-intrinsic LoRA: mejora la cuantización de baja precisión con corrección de bajo rango. Algoritmo casi óptimo para modelos grandes.

GPTQ-intrinsic LoRA combina cuantización de baja precisión y adaptación de bajo rango para comprimir redes neuronales. Algoritmo sin entrenamiento mejora modelos como Qwen3 y DeiT.

Descubre cómo modernizar tus apps legacy para que se adapten a tu flujo de trabajo actual, reduciendo costos y riesgos. Q2BSTUDIO te guía.

G2LoRA: marco que combina gradiente ortogonal y aprendizaje continuo para evitar el olvido catastrófico en grafos textuales. ¡Pruébalo!

Descubre los desafíos y oportunidades para competir en el escenario internacional de la IA, desde la adaptación cultural hasta la cadena de suministro de semiconductores.

Descubre cómo las Políticas de Difusión Parametrizadas (PDP) transforman el ruido en control, adaptando comportamientos robóticos sin reentrenar el modelo. Resu

Descubre cómo las políticas de difusión parametrizadas permiten adaptar comportamientos robóticos sin reentrenar, mejorando la síntesis de nuevas conductas.

Descubre cómo la interacción se convierte en la unidad principal de análisis en la IA co-creativa, redefiniendo la inteligencia en sistemas humano-IA.

Descubre FoLoRA: optimización mediante cociente de Rayleigh que preserva capacidades base mientras adapta modelos a tareas específicas. Máximo rendimiento sin olvido.

Aprende cómo ReCAP, un marco de aprendizaje continuo adaptativo al régimen, optimiza carteras y se adapta rápidamente a los cambios del mercado.
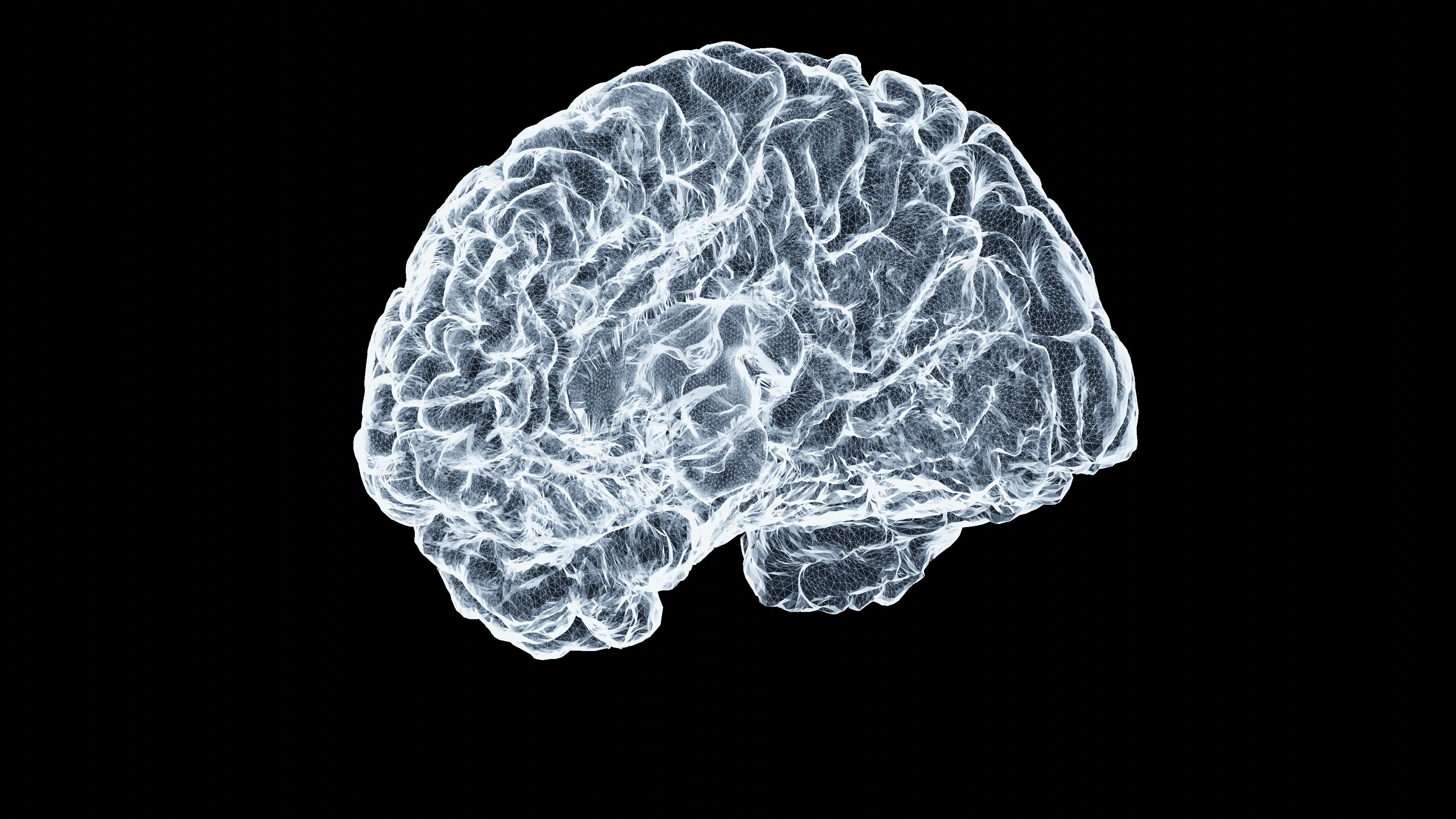
PIGMENT: modelo de IA informado por física para MRI de difusión cuantitativa. Permite mapear microestructura cerebral con datos escasos. Ideal para diagnóstico.