
Message Tuning supera al Graph Prompt Tuning: perspectiva prismática
Message Tuning supera al Graph Prompt Tuning: la Teoría del Espacio Prismático explica por qué. Descubre el nuevo método MTG.
Message Tuning supera al Graph Prompt Tuning: la Teoría del Espacio Prismático explica por qué. Descubre el nuevo método MTG.
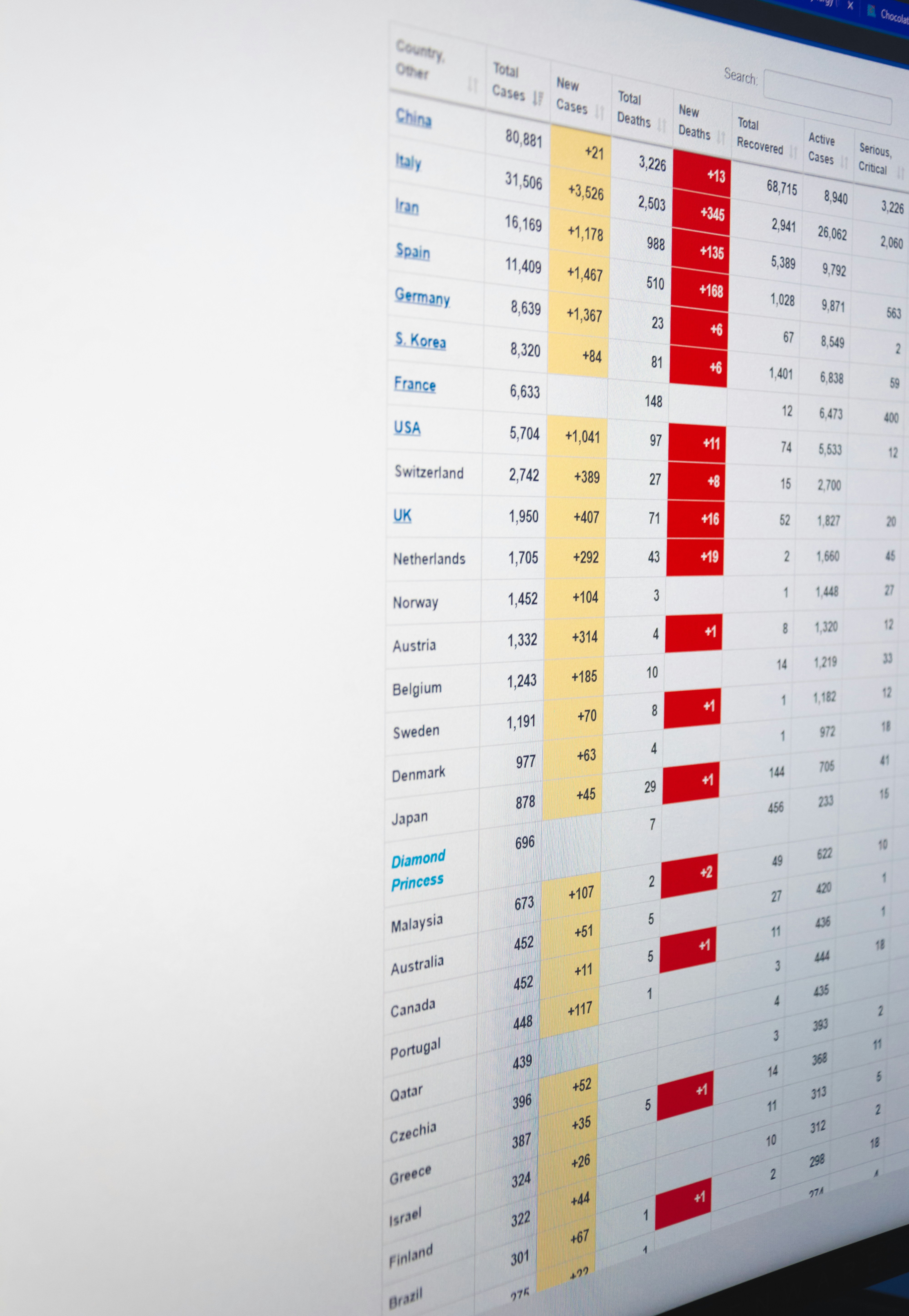
Descubre cómo una app personalizada para reemplazar hojas de cálculo se adapta a tu flujo de trabajo sin interrupciones. Aprende los pasos clave y cómo Q2BSTUDIO te ayuda.
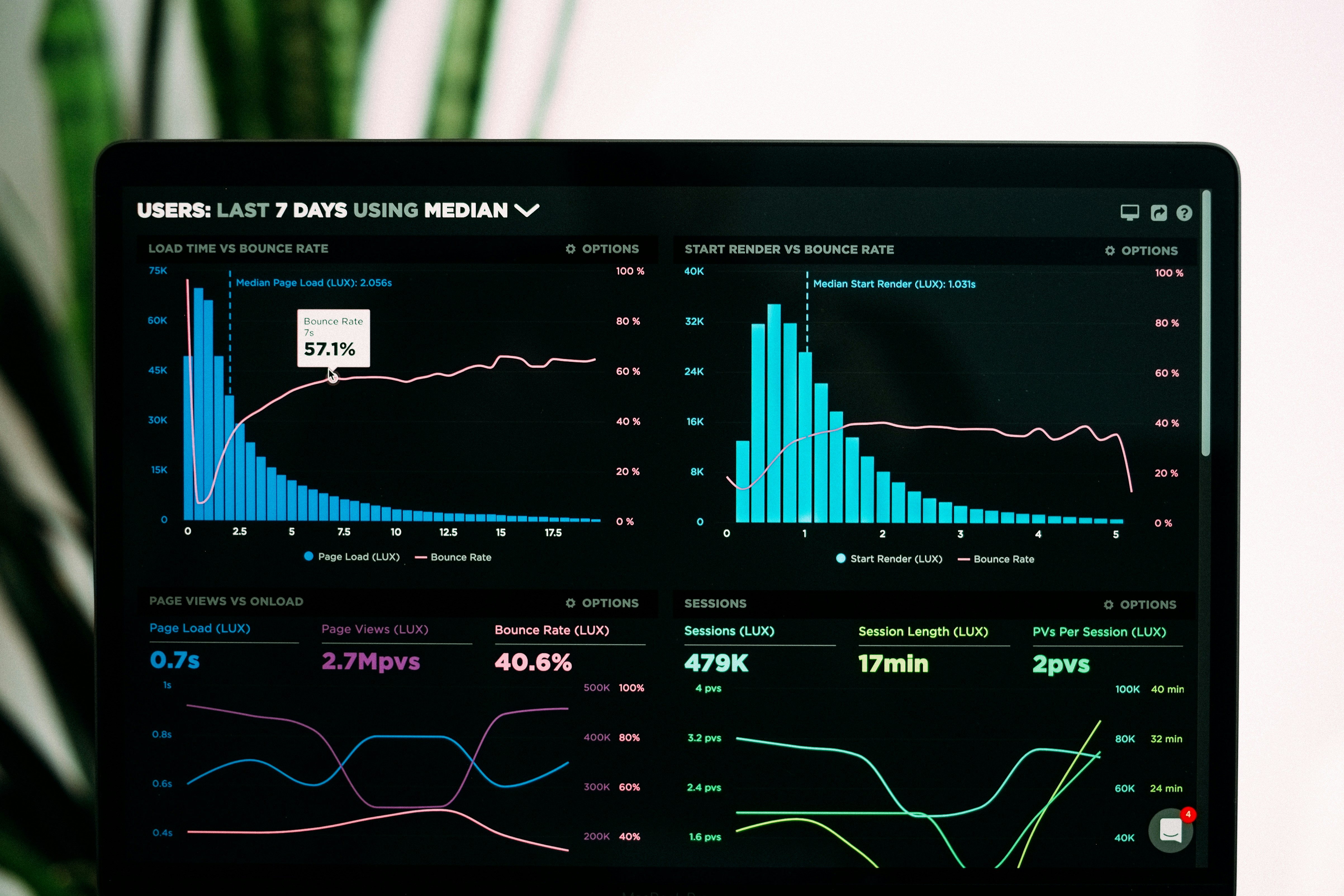
¿Más datos siempre mejoran el aprendizaje multitarea? Un nuevo estudio demuestra que no. Conoce los límites insuperables de la adaptación y el teorema de no-free-lunch.

Descubre cómo SALAAD reduce el consumo de memoria en modelos de lenguaje grandes usando estructuras dispersas y de bajo rango, permitiendo un despliegue flexible sin reentrenamiento.

Descubre ToolSelf, un paradigma que permite a agentes de IA reconfigurarse dinámicamente durante la ejecución, mejorando el rendimiento sin intervención manual.
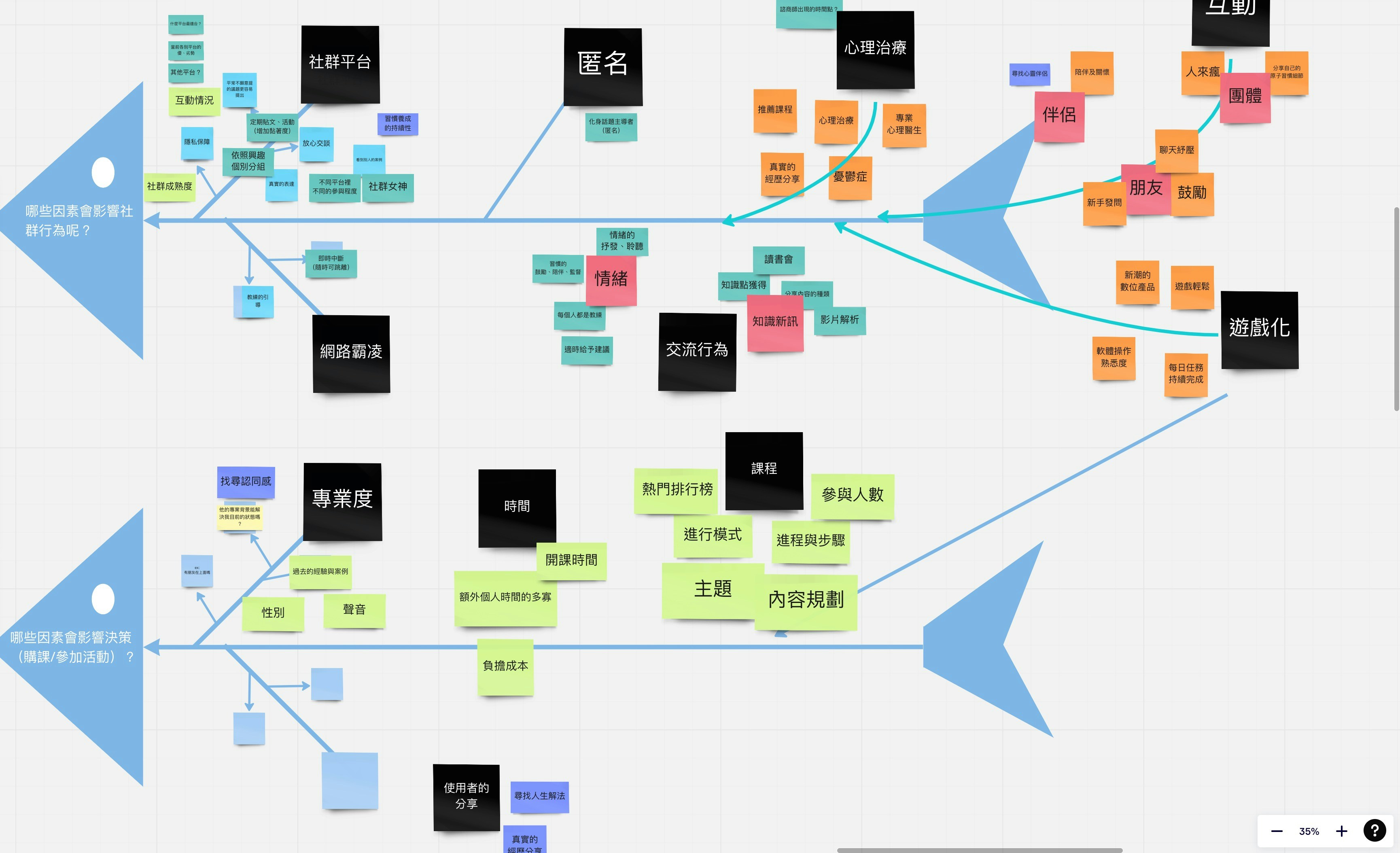
Descubre cómo reemplazar Access con una app moderna que se adapta a tu flujo de trabajo, mejora seguridad e integración sin fricción. Q2BSTUDIO te guía.

Nuevo framework Sherlock usa IA y LLM para adaptar conocimiento dinámico y mejorar la detección de fraudes en e-commerce, con 82% aceptación experta.

Descubre Sympatheia, un asistente de voz que se adapta a tus emociones mediante condicionamiento afectivo continuo. Mejora la interacción humano-máquina con IA empática.

Nuevo método de adaptación de dominio con un embedding visión-lenguaje para conducción autónoma sin datos objetivo, superando condiciones adversas.

NestRL optimiza la colaboración humano-IA mediante entrenamiento anidado, logrando mayor adaptabilidad y rendimiento frente a métodos tradicionales en Overcooked.

El marco LeARN aprende funciones base mediante meta-aprendizaje, adaptándose a dinámicas no lineales y superando las limitaciones de SINDy.
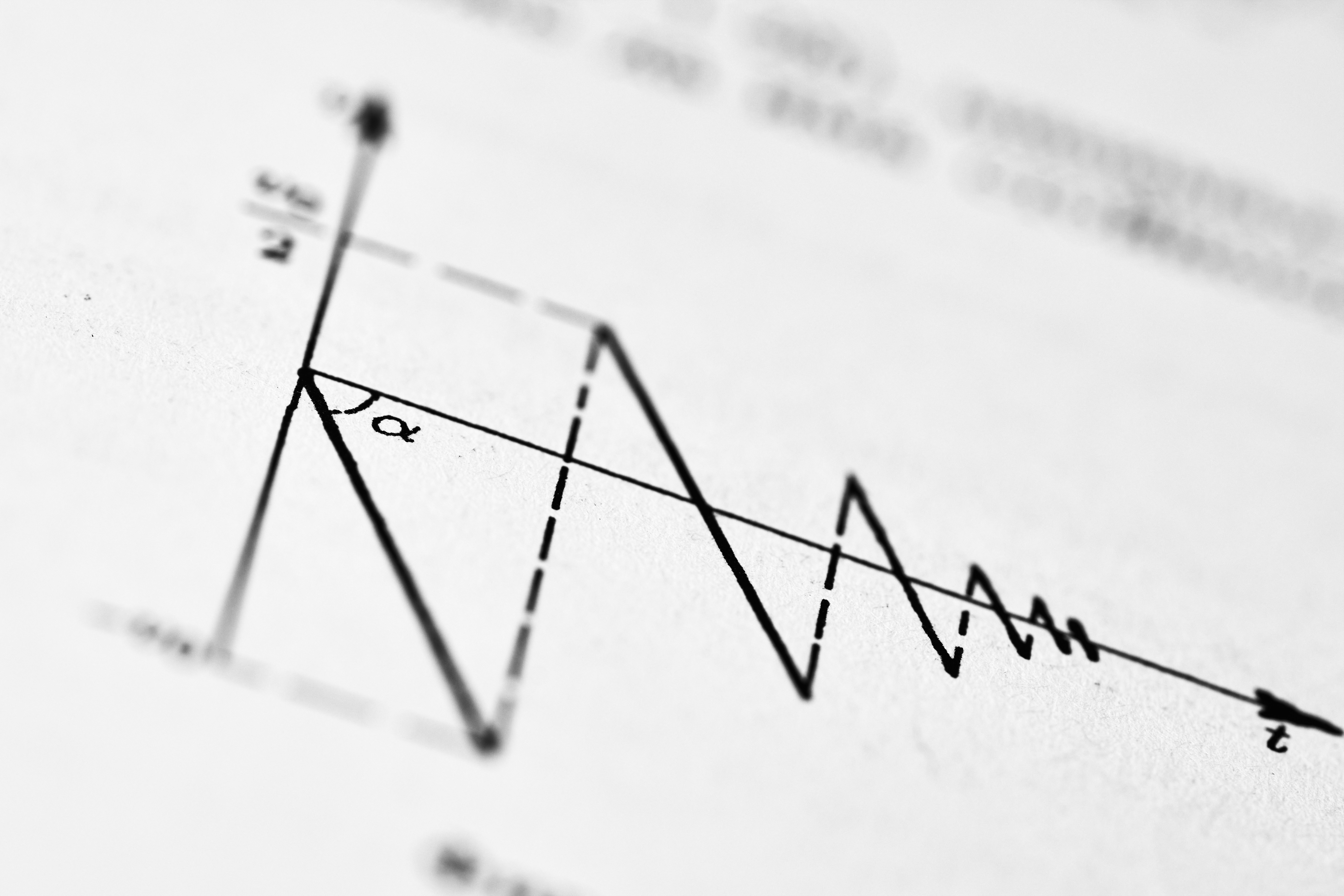
Descubre RefLoRA, una nueva técnica de fine-tuning que acelera la convergencia y mejora el rendimiento de modelos grandes con mínimo costo computacional.
Descubre cómo Tempora evalúa la adaptación en tiempo de prueba bajo presión temporal. Conoce métricas para elegir el mejor método según latencia y precisión.

El fine-tuning secuencial con LoRA vence a métodos CRL complejos en modelos VLA: alta plasticidad, sin olvido catastrófico.

Nueva técnica de aprendizaje off-policy con zero-shot adapta políticas óptimas sin reentrenamiento, usando sucesores y densidades estacionarias. Benchmark en ExoRL y OGBench.

naPINN recupera leyes físicas de mediciones con ruido y outliers sin conocer la distribución del ruido. Ideal para datos corruptos.

Descubre cómo la adaptación de ruido semi-supervisada (SSNA) utiliza ruido sintético para mejorar la generalización de modelos de aprendizaje automático. ¡Optimiza tu rendimiento!

GPTQ-intrinsic LoRA: mejora la cuantización de baja precisión con corrección de bajo rango. Algoritmo casi óptimo para modelos grandes.

GPTQ-intrinsic LoRA combina cuantización de baja precisión y adaptación de bajo rango para comprimir redes neuronales. Algoritmo sin entrenamiento mejora modelos como Qwen3 y DeiT.

Descubre cómo modernizar tus apps legacy para que se adapten a tu flujo de trabajo actual, reduciendo costos y riesgos. Q2BSTUDIO te guía.