
RL offline logra planificación efectiva con soluciones aleatorias
CDQAC: RL offline que aprende planificación efectiva incluso de soluciones aleatorias, superando heurísticas complejas con mínimos datos.
CDQAC: RL offline que aprende planificación efectiva incluso de soluciones aleatorias, superando heurísticas complejas con mínimos datos.

¿Sabías que la longitud de razonamiento tiene un punto óptimo? Descubre cómo la investigación optimiza precisión y coste en modelos de lenguaje con RL.

Descubre PiSO, un algoritmo que calcula escalas óptimas de cuantización para LLMs. Mejora perplejidad y precisión en tus modelos.

Descubre cómo la teoría de decisión estadística con pérdida contrafactual permite evaluar decisiones a nivel unitario, superando limitaciones clásicas. Ideal para IA y ciberseguridad.
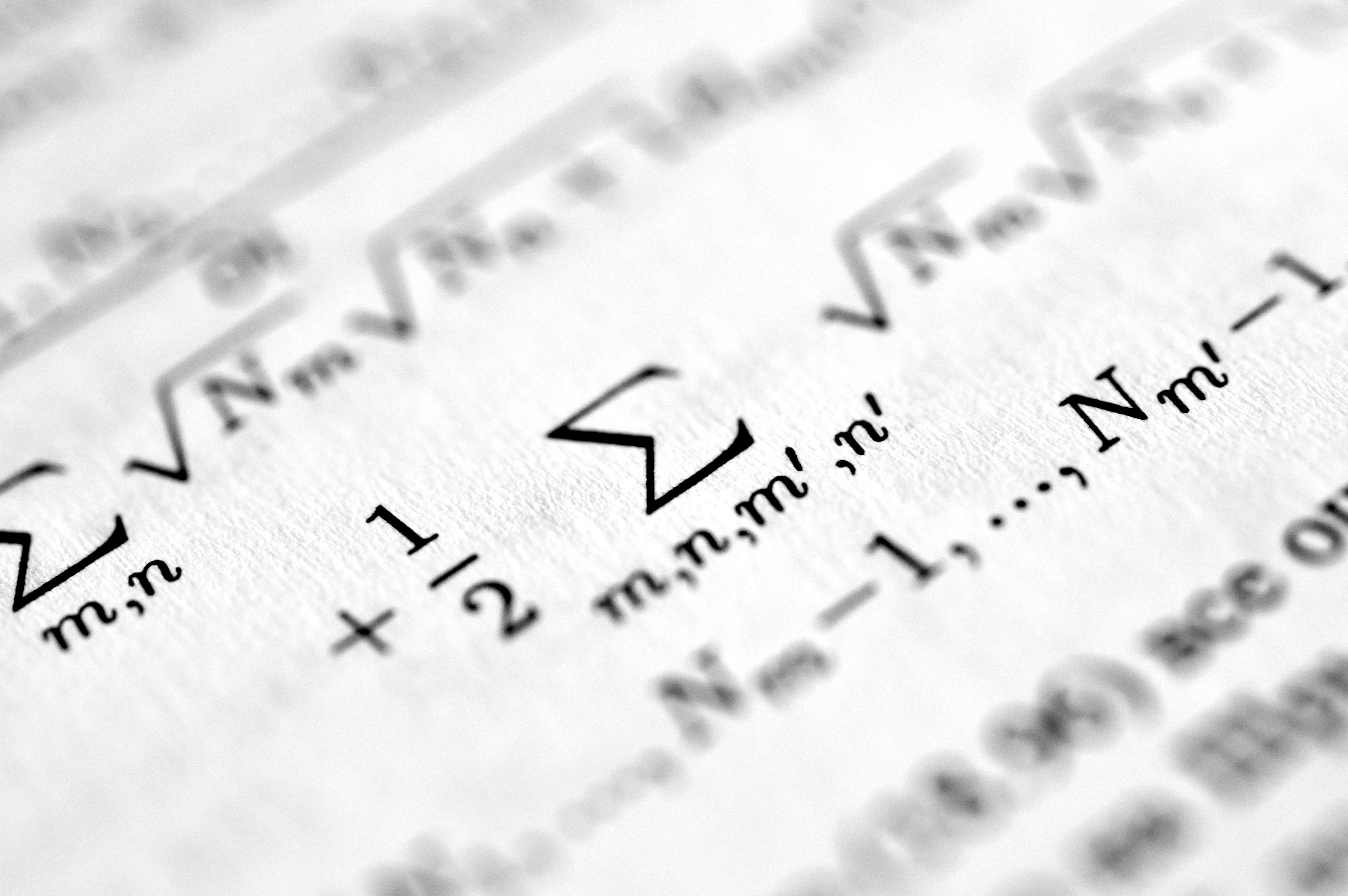
Descubre OptMuon, optimizador con momento ortogonalizado y control adaptativo en bucle cerrado. Logra tasas óptimas incluso sin ruido. Ideal deep learning.

Descubre cómo la escala S=2^8 y la iteración inversa evitan el colapso de precisión en atención FP8, mejorando el MSE entre 3 y 10 veces.

Descubre cómo GD y SGD alcanzan tasas óptimas de generalización en redes ReLU profundas, con resultados minimax comparables a kernels.

Descubre cómo las recompensas dispersas en el aprendizaje por refuerzo mejoran la ciberdefensa, ofreciendo políticas más seguras y efectivas que las densas.

Optimiza agentes LLM de caja negra sin entrenarlos. Agentic Monte Carlo supera a GRPO. Aprende inferencia bayesiana.

Descubre cómo las representaciones Bayes-suficientes preservan la información relevante para la predicción óptima. Incluye experimentos con iNaturalist.

Aprende cómo el aprendizaje bayesiano cuantifica la incertidumbre en rutas estocásticas, mejorando la eficiencia de datos frente a métodos tradicionales.

Descubre cómo el descenso de gradiente logra tasas de generalización óptimas en redes ReLU profundas con dependencia polinomial de la profundidad, mejorando resultados previos.
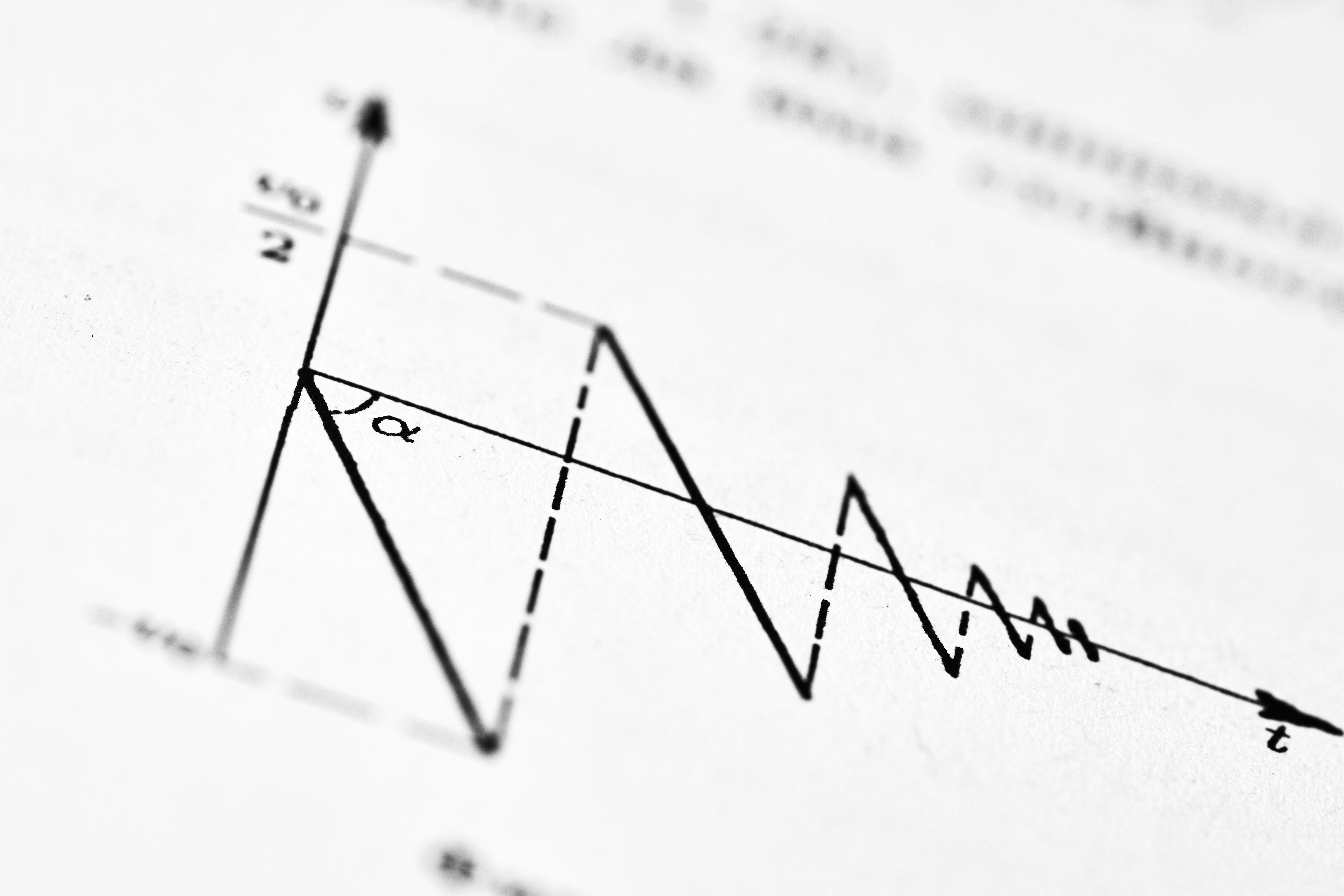
Descubre cómo un enfoque de perturbación logra arrepentimiento óptimo en bandidos lineales no restringidos, con nuevas garantías de alta probabilidad y tasas adaptativas.

Descubre pruebas privadas casi óptimas para hipótesis simples y MLR con privacidad diferencial gaussiana. Resultados comparables a pruebas no privadas.

Estimación casi óptima y eficiente de señales discretas con recurrencias lineales. Descubre el estimador minimax y su aplicación en detección.

Descubre cómo el aprendizaje por refuerzo multiobjetivo optimiza seguridad, eficiencia y costes en camiones autónomos con frontera de Pareto.

Nueva técnica de aprendizaje off-policy con zero-shot adapta políticas óptimas sin reentrenamiento, usando sucesores y densidades estacionarias. Benchmark en ExoRL y OGBench.

Descubre por qué auditar políticas casi óptimas en RL puede ser exponencialmente difícil. Analizamos cotas inferiores de consulta y la capacidad Rashomon.

Aprende cómo los algoritmos de error feedback logran convergencia óptima en optimización distribuida con compresión de gradientes. Análisis para EF y EF21.
Descubre cómo la nueva regla de parada consciente del costo optimiza la optimización bayesiana, reduciendo evaluaciones innecesarias y mejorando el regret simple ajustado al costo.