Prácticas de observabilidad con Node.js y Grafana Cloud
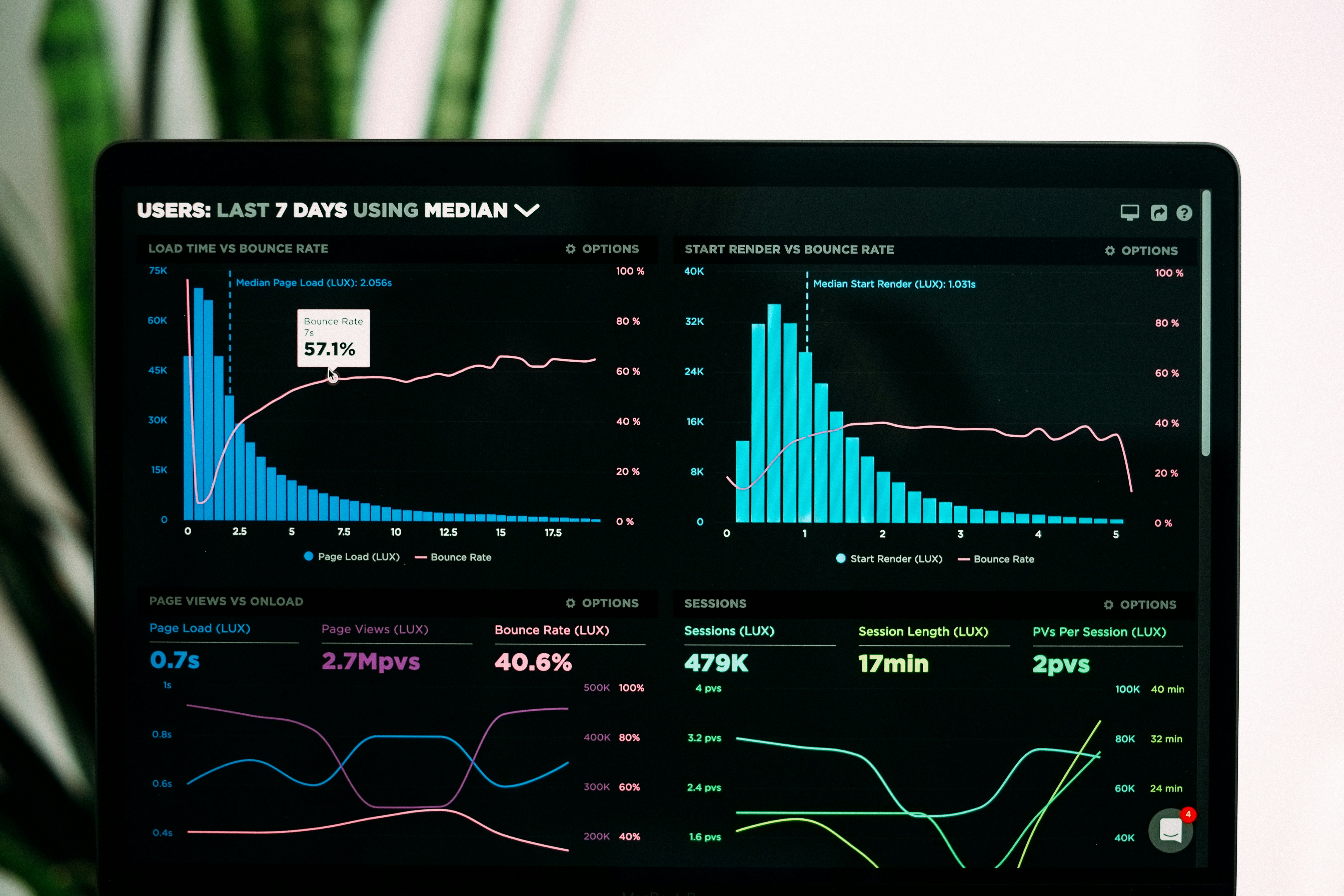
En el ecosistema actual de desarrollo de software, la complejidad de las arquitecturas distribuidas ha convertido la observabilidad en un pilar fundamental para garantizar la fiabilidad y el rendimiento de las aplicaciones. Ya no basta con monitorizar indicadores básicos como el consumo de CPU o memoria; los equipos de ingeniería necesitan herramientas y estrategias que permitan explorar el comportamiento interno de los sistemas en tiempo real. Este artículo ofrece una guía profesional sobre cómo implementar prácticas de observabilidad utilizando Node.js y Grafana Cloud, con un enfoque práctico y orientado a entornos de producción.
La observabilidad va más allá de la monitorización tradicional. Mientras que esta última se limita a responder preguntas predefinidas basadas en umbrales estáticos —por ejemplo, “¿la CPU supera el 90%?”—, la observabilidad permite a los desarrolladores formular preguntas que nunca anticiparon al escribir el código. En sistemas modernos, compuestos por microservicios, contenedores y comunicaciones asíncronas, los fallos suelen ser impredecibles y difíciles de diagnosticar. Contar con telemetría rica —logs estructurados, métricas y trazas— es indispensable para reconstruir el camino de una petición a través de múltiples servicios y encontrar la causa raíz de una anomalía.
En Q2BSTUDIO, entendemos que la observabilidad no es solo una cuestión técnica, sino una decisión estratégica. Nuestra experiencia en el desarrollo de aplicaciones a medida nos ha enseñado que integrar telemetría desde las primeras fases del diseño arquitectónico reduce drásticamente el tiempo de resolución de incidentes y mejora la experiencia del usuario final. Por eso, al construir sistemas basados en Node.js, recomendamos combinar librerías como prom-client para métricas y Winston para logs estructurados, junto con un backend de almacenamiento y visualización como Grafana Cloud.
Elegir la plataforma adecuada es clave. Grafana Cloud ofrece un stack unificado que integra logs, métricas y trazas en un solo panel, eliminando la necesidad de gestionar infraestructura local de Prometheus, Loki o Tempo. Su generoso plan gratuito permite a los equipos pequeños y medianos comenzar a instrumentar sus aplicaciones sin coste inicial. Además, su soporte nativo para PromQL —el lenguaje de consulta de series temporales— facilita el cálculo de percentiles de latencia, tasas de error y otros indicadores esenciales para definir objetivos de nivel de servicio (SLO).
Para ilustrar su aplicación práctica, imaginemos un servicio REST API en Node.js que expone endpoints de usuarios, productos y pedidos. Con prom-client, podemos definir un contador de peticiones totales etiquetado por método, ruta y código de estado, y un histograma que mida la duración de cada solicitud en segundos. Estos datos se serializan en formato Protocol Buffers, se comprimen con Snappy y se envían cada 15 segundos al endpoint de Remote Write de Grafana Cloud. Paralelamente, configuramos Winston para generar logs en JSON con marcas de tiempo y metadatos, facilitando su búsqueda y correlación posterior. Este enfoque permite no solo ver cuántas peticiones fallan, sino también inspeccionar los logs de una transacción específica que generó un error 500.
La gestión de la cardinalidad de las métricas es un aspecto crítico que a menudo se pasa por alto. Etiquetar con valores únicos como identificadores de usuario o rutas dinámicas sin normalizar puede saturar la base de datos de series temporales, disparando los costes y degradando el rendimiento. La buena práctica consiste en agrupar rutas usando patrones como /users/:id en lugar de /users/938201, y limitar las etiquetas a dimensiones con un número acotado de valores posibles. Esta disciplina es especialmente relevante cuando se integran sistemas de ia para empresas, donde la ingesta masiva de datos requiere un diseño cuidadoso para evitar cuellos de botella.
Otro pilar de la observabilidad es la correlación entre telemetrías. Si nuestro middleware de Express asigna un identificador único de transacción a cada petición, podemos incluirlo tanto en las etiquetas de las métricas como en los campos de los logs. Así, cuando un dashboard muestre un pico de errores 500, el ingeniero podrá filtrar los logs por ese identificador y obtener de inmediato la traza de la excepción, el estado de la base de datos o la respuesta de una API externa. Esta práctica acelera enormemente la depuración y reduce el tiempo medio de reparación (MTTR).
En Q2BSTUDIO, aplicamos estos principios en todos nuestros proyectos de software a medida, combinándolos con capacidades de servicios cloud aws y azure para garantizar escalabilidad y resiliencia. Por ejemplo, al desplegar una aplicación Node.js en AWS ECS o Azure Kubernetes Service, configuramos métricas personalizadas que se envían a Grafana Cloud, mientras los logs se centralizan en Loki. Esto permite a los equipos de operaciones detectar patrones anómalos antes de que afecten a los usuarios, y a los desarrolladores optimizar el rendimiento basándose en datos reales.
La inteligencia artificial también juega un papel creciente en la observabilidad. Los agentes IA pueden analizar series temporales de métricas para predecir tendencias de carga o identificar comportamientos atípicos sin necesidad de umbrales estáticos. Por ejemplo, un agente entrenado con datos históricos de latencia podría alertar cuando se detecte un aumento inusual, incluso si ese valor aún no supera el umbral tradicional. Estas capacidades, combinadas con tableros de power bi o Grafana, ofrecen a los responsables de negocio una visión clara del estado de las aplicaciones y su impacto en los objetivos comerciales.
La ciberseguridad también se beneficia de una buena observabilidad. Registrando logs detallados de autenticación, acceso a recursos y cambios en la configuración, es posible detectar intrusiones o comportamientos sospechosos en fases tempranas. En Q2BSTUDIO, integramos prácticas de ciberseguridad con telemetría para construir sistemas que no solo sean observables, sino también auditables y resistentes a ataques. La capacidad de reconstruir una cadena de eventos es invaluable durante un análisis forense posterior a un incidente.
Por último, la automatización de procesos es un complemento natural. Una vez que se dispone de métricas y logs fiables, se pueden configurar alertas inteligentes que disparen workflows automáticos, como escalar horizontalmente un servicio cuando la latencia supera un percentil o reiniciar un contenedor que está generando errores recurrentes. Este tipo de automatización, alineada con los principios de Site Reliability Engineering, libera a los equipos de tareas repetitivas y les permite centrarse en mejoras de producto.
En resumen, la observabilidad con Node.js y Grafana Cloud no es un lujo, sino una necesidad para cualquier organización que aspire a entregar software fiable y de alto rendimiento. Adoptar esta mentalidad implica invertir en instrumentación de calidad, gestionar cuidadosamente la cardinalidad, correlacionar telemetrías y aprovechar herramientas modernas de visualización y alerta. En Q2BSTUDIO, ayudamos a las empresas a recorrer este camino, combinando nuestra experiencia en desarrollo de aplicaciones a medida con tecnologías cloud, inteligencia artificial y ciberseguridad. Si tu equipo busca mejorar su postura de observabilidad o necesita asesoramiento para instrumentar sus sistemas, estamos listos para acompañarte en cada paso.
Comentarios