Análisis de geometría de conmutación de la iteración de valor Q deflactado
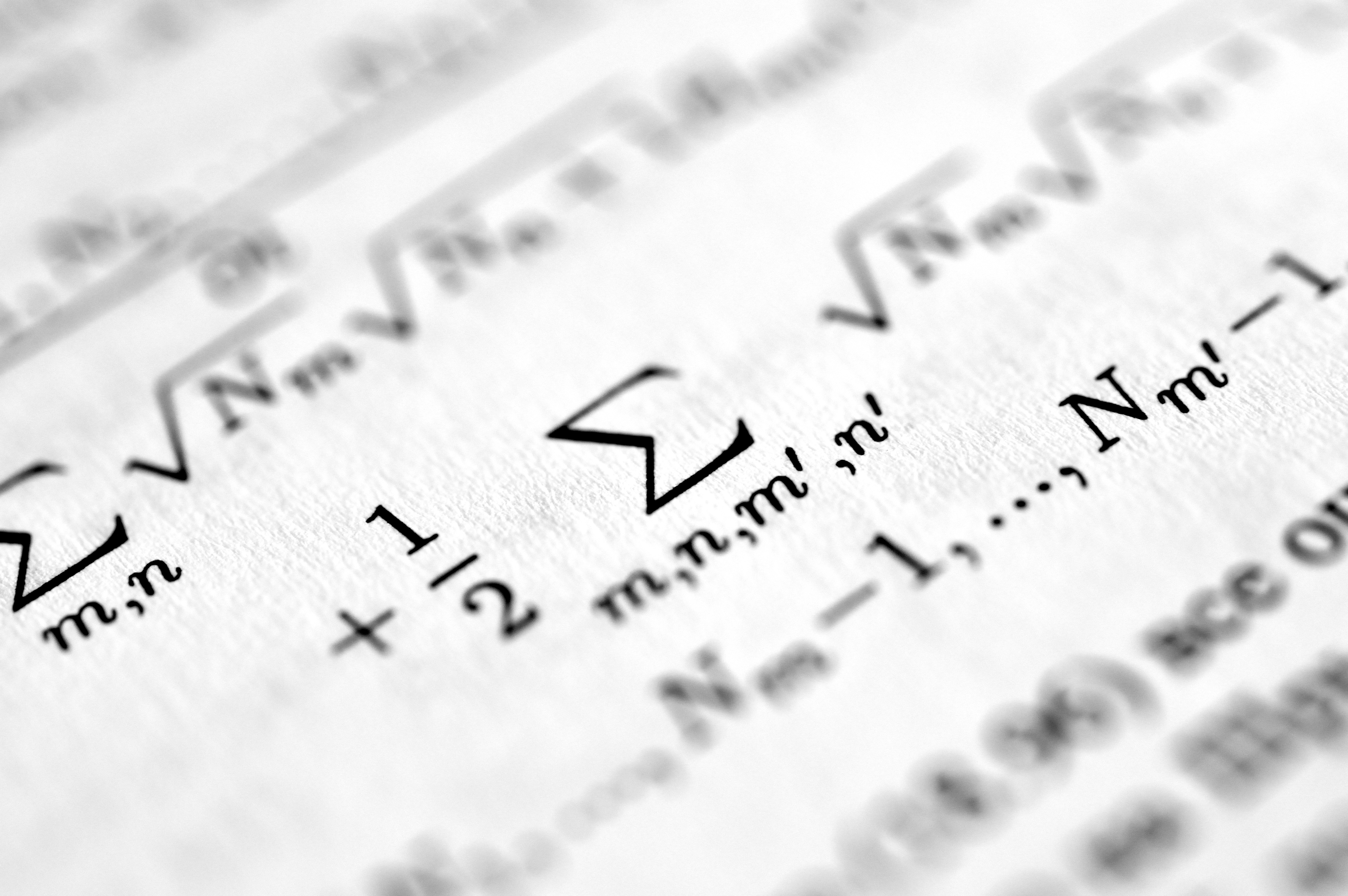
En el ámbito del aprendizaje por refuerzo, la optimización de políticas mediante la iteración de valor Q (Q-VI) es un pilar fundamental para la toma de decisiones secuenciales bajo incertidumbre. Sin embargo, la velocidad de convergencia de estos algoritmos puede verse limitada por la estructura geométrica del espacio de valores. Un enfoque reciente, basado en la deflación de componentes redundantes, permite descomponer la dinámica del error en un subespacio donde la tasa de convergencia es potencialmente más favorable. Este análisis, inspirado en sistemas de conmutación y radios espectrales conjuntos, revela que al eliminar la dirección invariante del vector de unos se obtiene una proyección que sigue una trayectoria idéntica a la del algoritmo estándar, pero con una caracterización más precisa de su comportamiento asintótico. Para las empresas que buscan implementar soluciones de ia para empresas, comprender esta geometría de conmutación puede traducirse en modelos de control más eficientes y predecibles. En Q2BSTUDIO, desarrollamos aplicaciones a medida que integran estos principios en entornos productivos, combinando inteligencia artificial con servicios cloud aws y azure para garantizar escalabilidad. Además, la implementación de agentes IA capaces de aprender y adaptarse se beneficia de un análisis riguroso de convergencia, evitando ciclos de entrenamiento innecesarios. Nuestra oferta también abarca servicios inteligencia de negocio con Power BI, que permiten visualizar el rendimiento de estos algoritmos en tiempo real, y un enfoque en ciberseguridad para proteger los datos sensibles involucrados. Así, la deflación en Q-VI no solo es un concepto teórico, sino una herramienta práctica para optimizar sistemas de decisión automatizados, desde la logística hasta la robótica, siempre con software a medida que se adapta a las necesidades específicas de cada organización.
Comentarios