Estrategias de niveles de log: DEBUG, INFO y ERROR
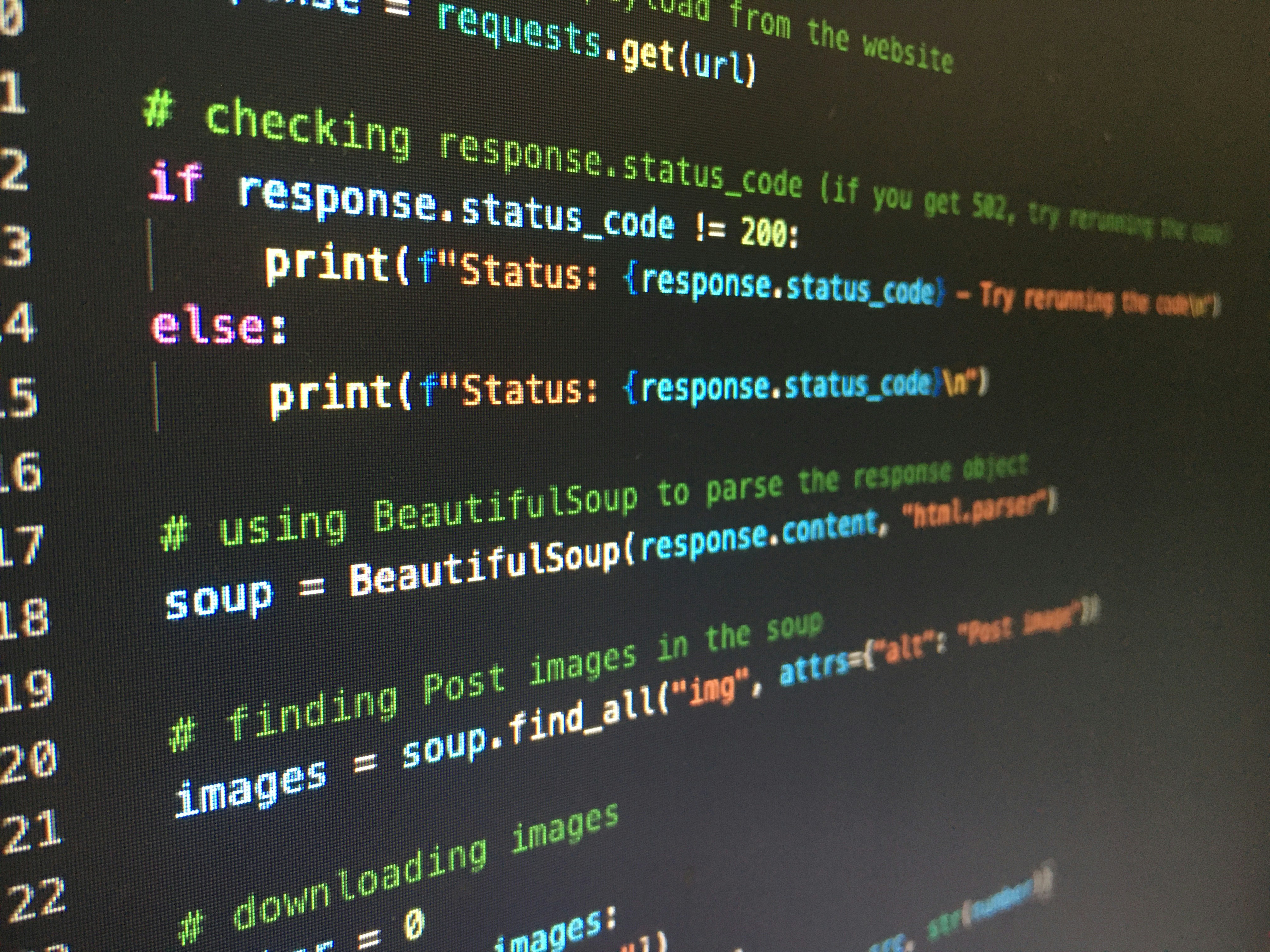
En el desarrollo de software moderno, los registros de eventos (logs) constituyen una de las fuentes más valiosas de inteligencia operativa. Sin embargo, su utilidad depende directamente de cómo se clasifican y gestionan los distintos niveles de log. Una estrategia bien definida permite transformar archivos de texto en herramientas de diagnóstico ágiles, mientras que una mala praxis puede generar ruido, riesgos de seguridad y cuellos de botella en rendimiento. En Q2BSTUDIO, empresa especializada en aplicaciones a medida, aplicamos estos principios para garantizar sistemas observables y eficientes.
Los niveles de log —DEBUG, INFO, WARN, ERROR y FATAL— actúan como filtros que determinan qué información se registra y con qué urgencia se trata. Durante el desarrollo, el nivel DEBUG permite rastrear cada variable y flujo de ejecución, facilitando la depuración. En producción, sin embargo, ese mismo nivel puede saturar discos, consumir CPU e incluso exponer datos sensibles. Por eso, en entornos productivos solemos configurar niveles INFO o superiores, y solo activamos DEBUG de forma temporal y acotada cuando investigamos incidencias concretas. Este enfoque es especialmente relevante cuando desarrollamos servicios cloud AWS y Azure, donde el volumen de logs puede dispararse si no se controla adecuadamente.
El nivel INFO es el pulso del sistema: refleja eventos clave del flujo de negocio, como recepción de pedidos, pagos procesados o actualizaciones de inventario. En proyectos de inteligencia de negocio y Power BI, estos logs alimentan dashboards que monitorizan la salud operativa en tiempo real. Por otro lado, los niveles WARN y ERROR alertan sobre problemas potenciales o fallos. Un WARN típico puede ser una respuesta lenta de una API externa; un ERROR, una conexión a base de datos rechazada. En Q2BSTUDIO incorporamos agentes IA para detectar patrones anómalos en estos registros y automatizar respuestas, reduciendo el tiempo de resolución.
Una de las malas prácticas más comunes es registrar mensajes genéricos como 'error inesperado' sin incluir trazas ni contexto. Esto convierte la depuración en una tarea casi detectivesca. Por el contrario, un registro completo debe contener el identificador único de la transacción, el stack trace y los valores relevantes. También es crítico evitar la exposición de datos personales o credenciales; por ello, aplicamos técnicas de enmascaramiento y cifrado, alineadas con las normativas de ciberseguridad. Nuestros equipos integran estas directrices en cada fase del software a medida que desarrollamos.
La flexibilidad en la configuración de niveles es otro pilar. En entornos de producción, podemos cambiar dinámicamente el nivel de log de un módulo concreto mediante variables de entorno o endpoints internos, sin necesidad de reiniciar el servicio. Esto resulta invaluable cuando se investigan cuellos de botella en bases de datos o comportamientos erráticos de integraciones con terceros. En Q2BSTUDIO, combinamos esta capacidad con servicios de inteligencia artificial para empresas, entrenando modelos que identifican correlaciones entre logs y fallos recurrentes, y generando alertas predictivas que anticipan incidentes.
Finalmente, la integración con herramientas como Grafana Loki o el stack ELK permite centralizar logs, aplicar búsquedas avanzadas y crear paneles de control. Al adoptar estas estrategias, los logs dejan de ser un simple almacén de texto y se convierten en un activo estratégico para la mejora continua. En Q2BSTUDIO acompañamos a nuestros clientes en todo este proceso, desde el diseño de la arquitectura de logging hasta la implementación de agentes IA que extraen valor de cada traza.
Comentarios