Grammarly cuesta $12/mes, un LLM local lo hace gratis (Chrome + Ollama)
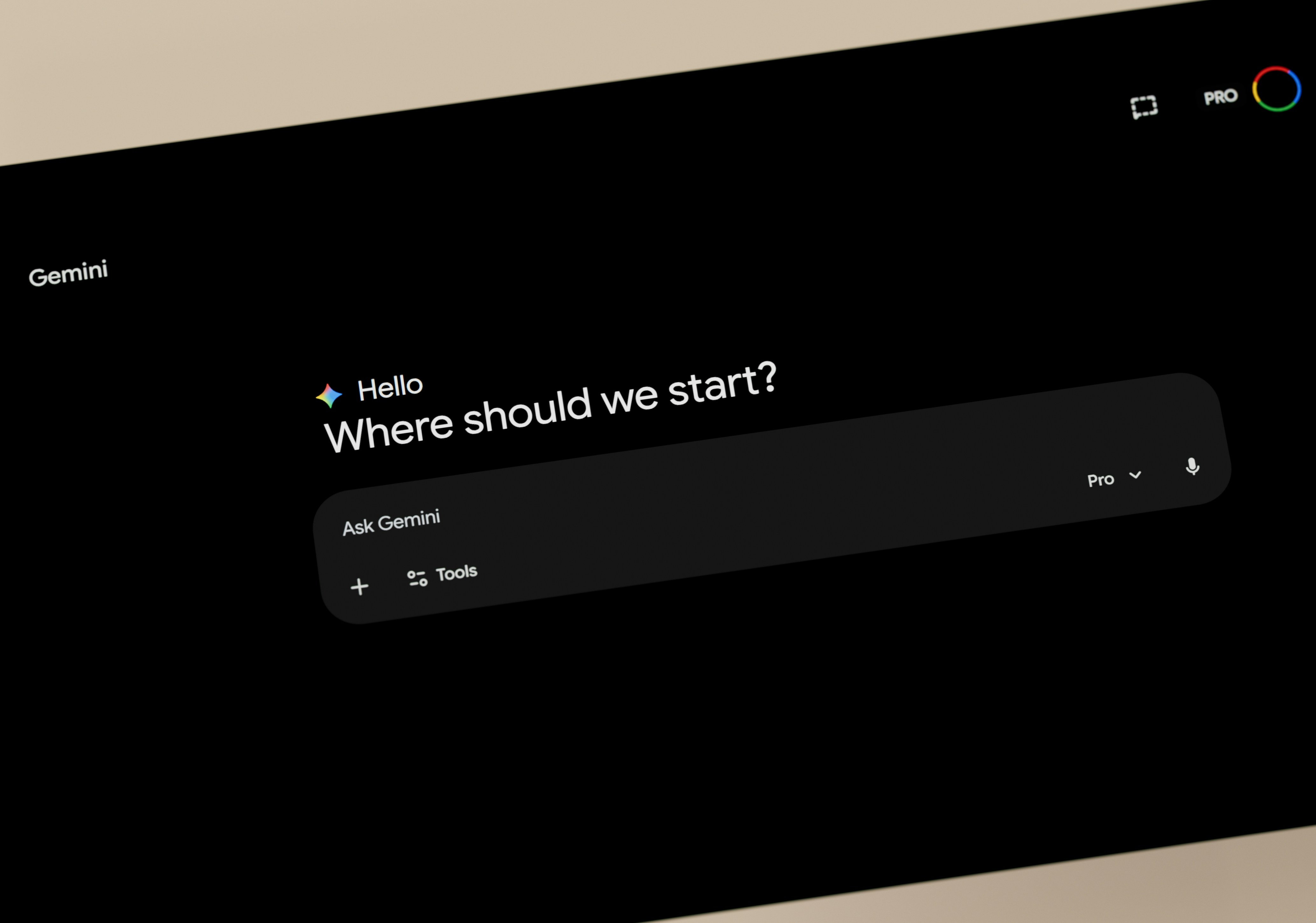
Durante años, la corrección gramatical en el navegador ha estado dominada por soluciones en la nube como Grammarly, que ofrecen una experiencia de usuario impecable pero a costa de enviar cada pulsación a servidores externos. Para muchas empresas, especialmente las que manejan documentación legal, código no publicado o datos de pacientes, esto es un problema de ciberseguridad y cumplimiento normativo. La alternativa tradicional —pegar textos en ChatGPT— genera un bloque reformateado que obliga a re-leer todo el contenido para identificar cambios, además de seguir exponiendo la información. Surge entonces una pregunta: ¿es posible obtener la misma experiencia de revisión visual de cambios (track changes) pero con un modelo de inteligencia artificial que se ejecute completamente en local?
La respuesta es sí, y la clave está en separar las responsabilidades. En lugar de pedirle al modelo que genere directamente un diff estructurado —tarea en la que los modelos pequeños (como Llama 3.2 de 3B parámetros) suelen fallar al producir JSON mal formado o envoltorios extraños— se le asigna una tarea mucho más natural: devolver el texto corregido como una cadena continua. A partir de ahí, un algoritmo determinista de comparación (basado en la subsecuencia común más larga sobre tokens de palabras, espacios y puntuación) calcula los cambios exactos. Esta arquitectura, que puede implementarse en una extensión de Chrome usando Ollama como backend local, permite que cada corrección se muestre en un panel de revisión con botones de aceptar o rechazar, exactamente como Grammarly, pero sin que ningún dato salga del ordenador del usuario.
Una de las barreras técnicas más comunes al conectar una extensión con un servidor local de Ollama es el error 403 provocado por el encabezado Origin de las peticiones desde chrome-extension://. La solución habitual —configurar la variable de entorno OLLAMA_ORIGINS— añade fricción al usuario y suele ser el mayor punto de abandono. En su lugar, se puede emplear el API declarativeNetRequest de Manifest V3 para eliminar dinámicamente ese encabezado en las solicitudes dirigidas al endpoint local, sin comprometer la seguridad. Esto, combinado con la ejecución de las peticiones desde el service worker (evitando restricciones CSP de la página), ofrece una experiencia de instalación de solo dos pasos: instalar Ollama y ejecutar ollama serve, luego instalar la extensión.
Para las empresas, este enfoque abre la puerta a desarrollar aplicaciones a medida que integren inteligencia artificial local en flujos de trabajo de redacción, traducción o ajuste de tono, manteniendo los datos bajo control. La misma interfaz de diff puede reutilizarse con distintos prompts del sistema, convirtiendo la herramienta en un traductor o un reescritor de estilo. Además, la arquitectura es completamente agnóstica al modelo: funciona igual con 3B que con 70B parámetros, y puede alimentarse desde cualquier endpoint compatible con OpenAI (llama.cpp, LM Studio, vLLM, o incluso la propia clave de OpenAI).
En Q2BSTUDIO entendemos que la verdadera ventaja competitiva no está solo en la tecnología subyacente, sino en cómo se integra en los procesos de negocio. Por eso ofrecemos ia para empresas que permite construir soluciones como esta: privadas, personalizables y escalables. Nuestros servicios de software a medida abarcan desde la implementación de modelos locales hasta la orquestación de agentes IA en entornos cloud (servicios cloud aws y azure), garantizando además la ciberseguridad de los datos. También ayudamos a las organizaciones a extraer valor de sus datos mediante servicios inteligencia de negocio con Power BI, y a automatizar procesos críticos con bots inteligentes. El resultado es un ecosistema donde la inteligencia artificial deja de ser un producto cerrado y se convierte en una herramienta moldeable a las necesidades reales de cada empresa.
En definitiva, la propuesta de valor de Grammarly no era su motor gramatical, sino su interfaz de cambios controlados. Hoy, cualquier equipo de desarrollo puede replicar esa experiencia combinando un LLM local con una lógica determinista de diff, y hacerlo de forma gratuita. La próxima generación de herramientas de productividad empresarial no necesitará sacrificar privacidad por usabilidad: bastará con diseñar bien la frontera entre lo que hace el modelo y lo que hace el código.
Comentarios